 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistFL: Distribution-aware Federated Learning for Mobile Scenarios
Paper and Code
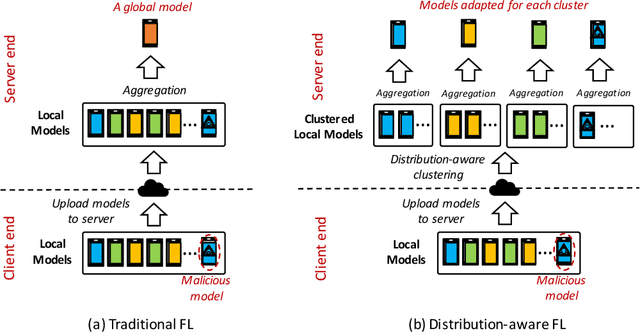
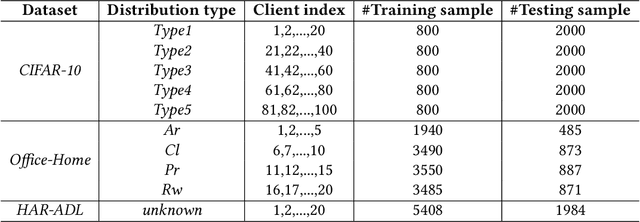
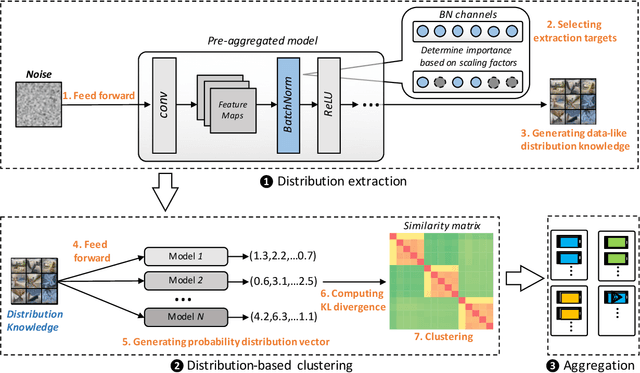
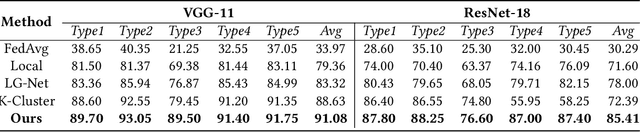
Federated learning (FL) has emerged as an effective solution to decentralized and privacy-preserving machine learning for mobile clients. While traditional FL has demonstrated its superiority, it ignores the non-iid (independently identically distributed) situation, which widely exists in mobile scenarios. Failing to handle non-iid situations could cause problems such as performance decreasing and possible attacks. Previous studies focus on the "symptoms" directly, as they try to improve the accuracy or detect possible attacks by adding extra steps to conventional FL models. However, previous techniques overlook the root causes for the "symptoms": blindly aggregating models with the non-iid distributions. In this paper, we try to fundamentally address the issue by decomposing the overall non-iid situation into several iid clusters and conducting aggregation in each cluster. Specifically, we propose \textbf{DistFL}, a novel framework to achieve automated and accurate \textbf{Dist}ribution-aware \textbf{F}ederated \textbf{L}earning in a cost-efficient way. DistFL achieves clustering via extracting and comparing the \textit{distribution knowledge} from the uploaded models. With this framework, we are able to generate multiple personalized models with distinctive distributions and assign them to the corresponding clients. Extensive experiments on mobile scenarios with popular model architectures have demonstrated the effectiveness of DistFL.