 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirCopBench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoning
Nov 14, 2025
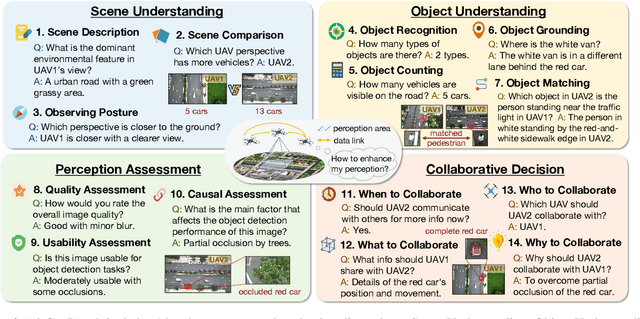
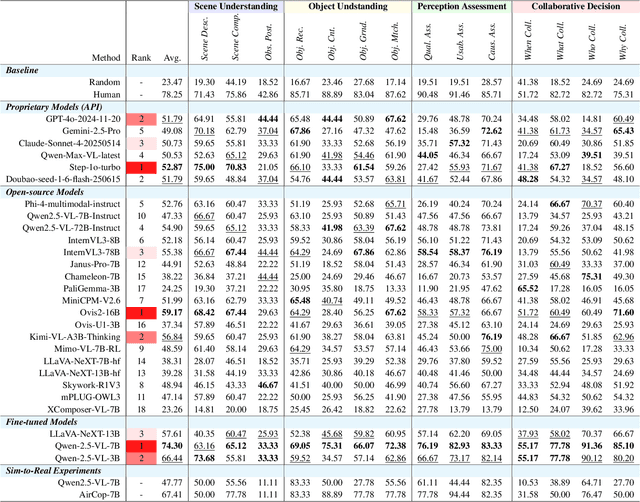
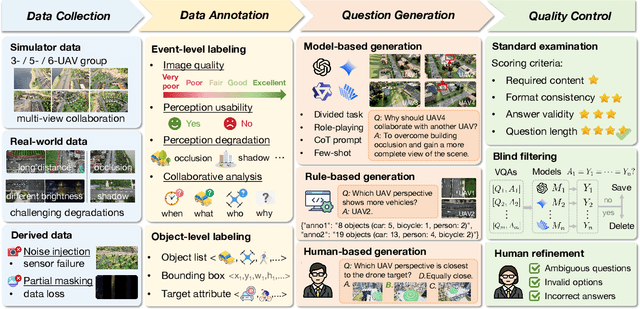
Multimodal Large Language Models (MLLMs) have shown promise in single-agent vision tasks, yet benchmarks for evaluating multi-agent collaborative perception remain scarce. This gap is critical, as multi-drone systems provide enhanced coverage, robustness, and collaboration compared to single-sensor setups. Existing multi-image benchmarks mainly target basic perception tasks using high-quality single-agent images, thus failing to evaluate MLLMs in more complex, egocentric collaborative scenarios, especially under real-world degraded perception conditions.To address these challenges, we introduce AirCopBench, the first comprehensive benchmark designed to evaluate MLLMs in embodied aerial collaborative perception under challenging perceptual conditions. AirCopBench includes 14.6k+ questions derived from both simulator and real-world data, spanning four key task dimensions: Scene Understanding, Object Understanding, Perception Assessment, and Collaborative Decision, across 14 task types. We construct the benchmark using data from challenging degraded-perception scenarios with annotated collaborative events, generating large-scale questions through model-, rule-, and human-based methods under rigorous quality control. Evaluations on 40 MLLMs show significant performance gaps in collaborative perception tasks, with the best model trailing humans by 24.38% on average and exhibiting inconsistent results across tasks. Fine-tuning experiments further confirm the feasibility of sim-to-real transfer in aerial collaborative perception and reasoning.
DIMM: Decoupled Multi-hierarchy Kalman Filter for 3D Object Tracking
May 18, 2025State estimation is challenging for 3D object tracking with high maneuverability, as the target's state transition function changes rapidly, irregularly, and is unknown to the estimator. Existing work based on interacting multiple model (IMM) achieves more accurate estimation than single-filter approaches through model combination, aligning appropriate models for different motion modes of the target object over time. However, two limitations of conventional IMM remain unsolved. First, the solution space of the model combination is constrained as the target's diverse kinematic properties in different directions are ignored. Second, the model combination weights calculated by the observation likelihood are not accurate enough due to the measurement uncertainty. In this paper, we propose a novel framework, DIMM, to effectively combine estimates from different motion models in each direction, thus increasing the 3D object tracking accuracy. First, DIMM extends the model combination solution space of conventional IMM from a hyperplane to a hypercube by designing a 3D-decoupled multi-hierarchy filter bank, which describes the target's motion with various-order linear models. Second, DIMM generates more reliable combination weight matrices through a differentiable adaptive fusion network for importance allocation rather than solely relying on the observation likelihood; it contains an attention-based twin delayed deep deterministic policy gradient (TD3) method with a hierarchical reward. Experiments demonstrate that DIMM significantly improves the tracking accuracy of existing state estimation methods by 31.61%~99.23%.
A Unified and Scalable Membership Inference Method for Visual Self-supervised Encoder via Part-aware Capability
May 15, 2025Self-supervised learning shows promise in harnessing extensive unlabeled data, but it also confronts significant privacy concerns, especially in vision. In this paper, we perform membership inference on visual self-supervised models in a more realistic setting: self-supervised training method and details are unknown for an adversary when attacking as he usually faces a black-box system in practice. In this setting, considering that self-supervised model could be trained by completely different self-supervised paradigms, e.g., masked image modeling and contrastive learning, with complex training details, we propose a unified membership inference method called PartCrop. It is motivated by the shared part-aware capability among models and stronger part response on the training data. Specifically, PartCrop crops parts of objects in an image to query responses within the image in representation space. We conduct extensive attacks on self-supervised models with different training protocols and structures using three widely used image datasets. The results verify the effectiveness and generalization of PartCrop. Moreover, to defend against PartCrop, we evaluate two common approaches, i.e., early stop and differential privacy, and propose a tailored method called shrinking crop scale range. The defense experiments indicate that all of them are effective. Finally, besides prototype testing on toy visual encoders and small-scale image datasets, we quantitatively study the impacts of scaling from both data and model aspects in a realistic scenario and propose a scalable PartCrop-v2 by introducing two structural improvements to PartCrop. Our code is at https://github.com/JiePKU/PartCrop.
How to Enable LLM with 3D Capacity? A Survey of Spatial Reasoning in LLM
Apr 08, 20253D spatial understanding is essential in real-world applications such as robotics, autonomous vehicles, virtual reality, and medical imaging. Recently, Large Language Models (LLMs), having demonstrated remarkable success across various domains, have been leveraged to enhance 3D understanding tasks, showing potential to surpass traditional computer vision methods. In this survey, we present a comprehensive review of methods integrating LLMs with 3D spatial understanding. We propose a taxonomy that categorizes existing methods into three branches: image-based methods deriving 3D understanding from 2D visual data, point cloud-based methods working directly with 3D representations, and hybrid modality-based methods combining multiple data streams. We systematically review representative methods along these categories, covering data representations, architectural modifications, and training strategies that bridge textual and 3D modalities. Finally, we discuss current limitations, including dataset scarcity and computational challenges, while highlighting promising research directions in spatial perception, multi-modal fusion, and real-world applications.
UrbanVideo-Bench: Benchmarking Vision-Language Models on Embodied Intelligence with Video Data in Urban Spaces
Mar 08, 2025Large multimodal models exhibit remarkable intelligence, yet their embodied cognitive abilities during motion in open-ended urban 3D space remain to be explored. We introduce a benchmark to evaluate whether video-large language models (Video-LLMs) can naturally process continuous first-person visual observations like humans, enabling recall, perception, reasoning, and navigation. We have manually control drones to collect 3D embodied motion video data from real-world cities and simulated environments, resulting in 1.5k video clips. Then we design a pipeline to generate 5.2k multiple-choice questions. Evaluations of 17 widely-used Video-LLMs reveal current limitations in urban embodied cognition. Correlation analysis provides insight into the relationships between different tasks, showing that causal reasoning has a strong correlation with recall, perception, and navigation, while the abilities for counterfactual and associative reasoning exhibit lower correlation with other tasks. We also validate the potential for Sim-to-Real transfer in urban embodiment through fine-tuning.
A Unified Membership Inference Method for Visual Self-supervised Encoder via Part-aware Capability
Apr 03, 2024

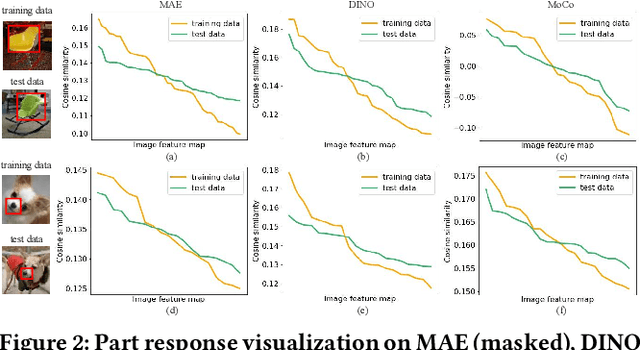
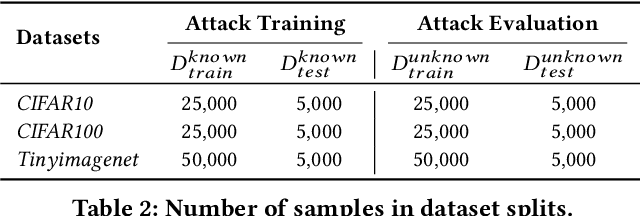
Self-supervised learning shows promise in harnessing extensive unlabeled data, but it also confronts significant privacy concerns, especially in vision. In this paper, we aim to perform membership inference on visual self-supervised models in a more realistic setting: self-supervised training method and details are unknown for an adversary when attacking as he usually faces a black-box system in practice. In this setting, considering that self-supervised model could be trained by completely different self-supervised paradigms, e.g., masked image modeling and contrastive learning, with complex training details, we propose a unified membership inference method called PartCrop. It is motivated by the shared part-aware capability among models and stronger part response on the training data. Specifically, PartCrop crops parts of objects in an image to query responses with the image in representation space. We conduct extensive attacks on self-supervised models with different training protocols and structures using three widely used image datasets. The results verify the effectiveness and generalization of PartCrop. Moreover, to defend against PartCrop, we evaluate two common approaches, i.e., early stop and differential privacy, and propose a tailored method called shrinking crop scale range. The defense experiments indicate that all of them are effective. Our code is available at https://github.com/JiePKU/PartCrop