 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Before You Leap: Problem Elaboration Prompting Improves Mathematical Reasoning in Large Language Models
Feb 24, 2024



Large language models~(LLMs) have exhibited impressive performance across NLP tasks. So far they still face challenges in complex reasoning tasks and can be sensitive to input context. Despite significant efforts have been invested in enhancing reasoning process and improving prefix-prompts robustness, the crucial role of problem context has been overlooked. In this study, we propose a new approach to improve the mathematical capacities of LLMs, named Problem Elaboration Prompting~(PEP). Specifically, PEP decomposes and elucidates the problem context before reasoning, thus enhancing the global context modeling and reducing the parsing difficulties. Experiments on datasets demonstrate promising performances on complex reasoning and indicate the beneficial impact for ill-formed problems. For instance, with the GPT-3.5 model~(\texttt{text-davinci-003}), we observed a 9.93\% improvement with greedy decoding and 8.80\% improvement with self-consistency on GSM8k compared to the standard CoT. With ChatGPT~(\texttt{turbo}) and PEP, we achieve SOTA performances on SVAMP with 86.2\% and GSM8k with 90.98\%.
Modeling Complex Mathematical Reasoning via Large Language Model based MathAgent
Dec 17, 2023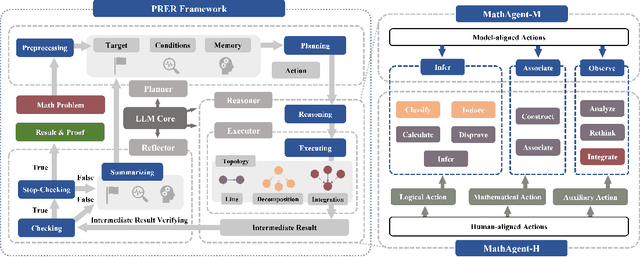
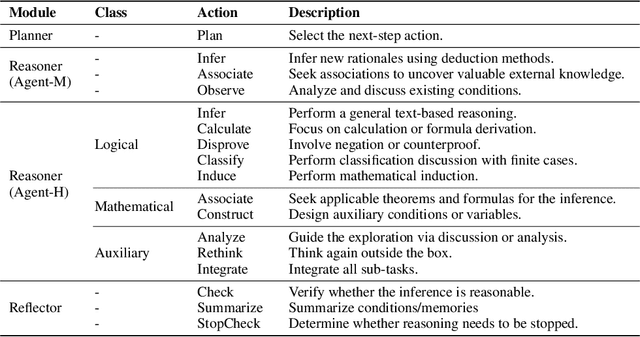
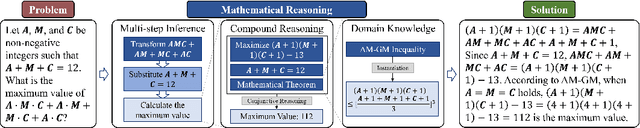
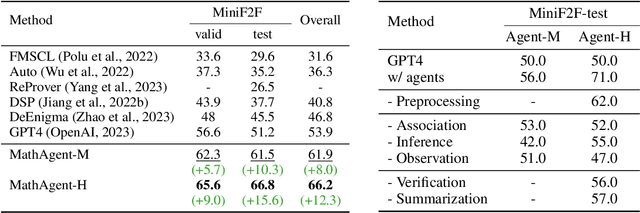
Large language models (LLMs) face challenges in solving complex mathematical problems that require comprehensive capacities to parse the statements, associate domain knowledge, perform compound logical reasoning, and integrate the intermediate rationales. Tackling all these problems once could be arduous for LLMs, thus leading to confusion in generation. In this work, we explore the potential of enhancing LLMs with agents by meticulous decomposition and modeling of mathematical reasoning process. Specifically, we propose a formal description of the mathematical solving and extend LLMs with an agent-based zero-shot framework named $\bf{P}$lanner-$\bf{R}$easoner-$\bf{E}$xecutor-$\bf{R}$eflector (PRER). We further provide and implement two MathAgents that define the logical forms and inherent relations via a pool of actions in different grains and orientations: MathAgent-M adapts its actions to LLMs, while MathAgent-H aligns with humankind. Experiments on miniF2F and MATH have demonstrated the effectiveness of PRER and proposed MathAgents, achieving an increase of $12.3\%$($53.9\%\xrightarrow{}66.2\%$) on the MiniF2F, $9.2\%$ ($49.8\%\xrightarrow{}59.0\%$) on MATH, and $13.2\%$($23.2\%\xrightarrow{}35.4\%$) for level-5 problems of MATH against GPT-4. Further analytical results provide more insightful perspectives on exploiting the behaviors of LLMs as agents.