 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Full Text-Dependent End to End Mispronunciation Detection and Diagnosis with Easy Data Augmentation Techniques
Apr 17, 2021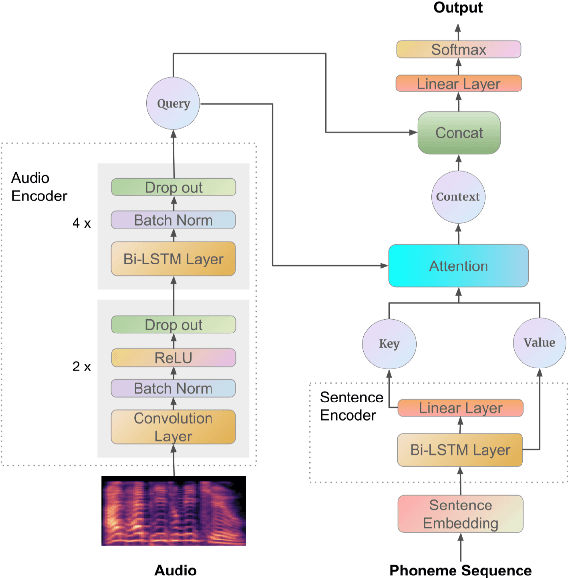
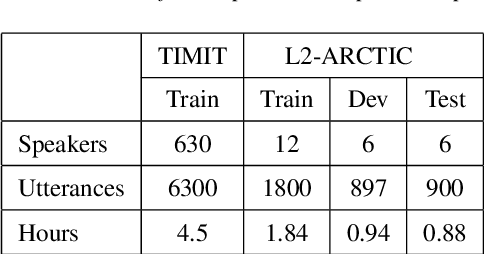
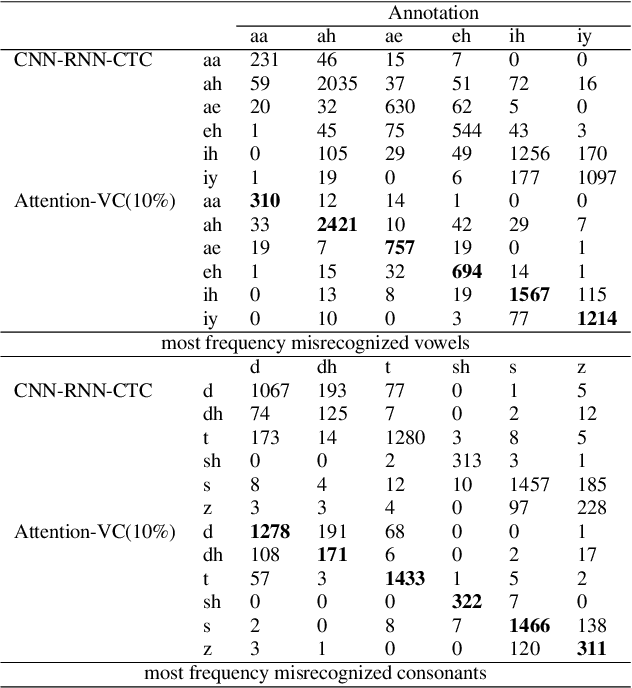
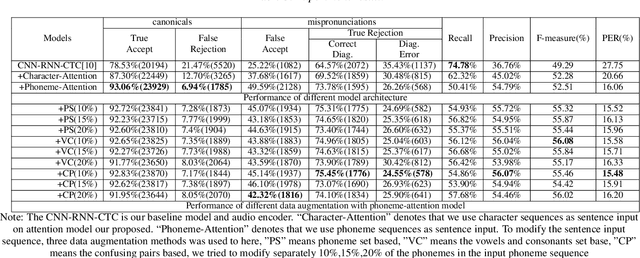
Recently, end-to-end mispronunciation detection and diagnosis (MD&D) systems has become a popular alternative to greatly simplify the model-building process of conventional hybrid DNN-HMM systems by representing complicated modules with a single deep network architecture. In this paper, in order to utilize the prior text in the end-to-end structure, we present a novel text-dependent model which is difference with sed-mdd, the model achieves a fully end-to-end system by aligning the audio with the phoneme sequences of the prior text inside the model through the attention mechanism. Moreover, the prior text as input will be a problem of imbalance between positive and negative samples in the phoneme sequence. To alleviate this problem, we propose three simple data augmentation methods, which effectively improve the ability of model to capture mispronounced phonemes. We conduct experiments on L2-ARCTIC, and our best performance improved from 49.29% to 56.08% in F-measure metric compared to the CNN-RNN-CTC model.