 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudent Become Decathlon Master in Retinal Vessel Segmentation via Dual-teacher Multi-target Domain Adaptation
Paper and Code
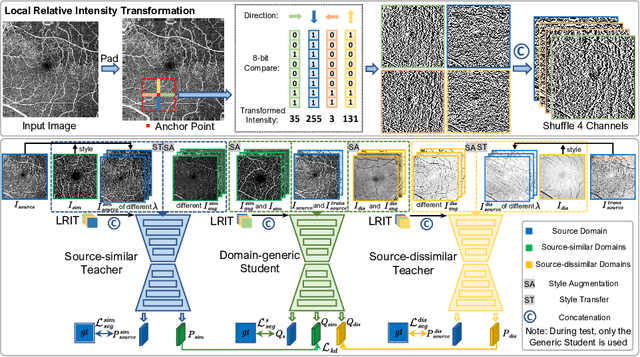
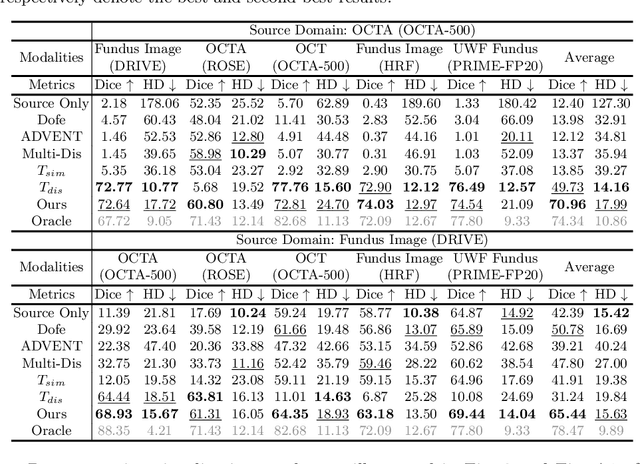
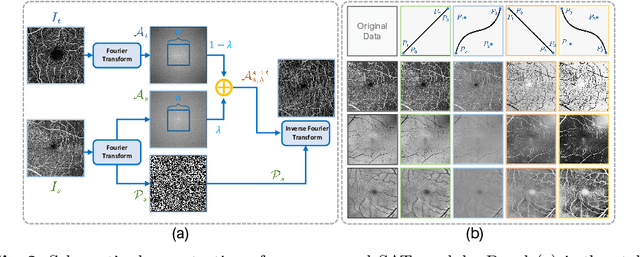
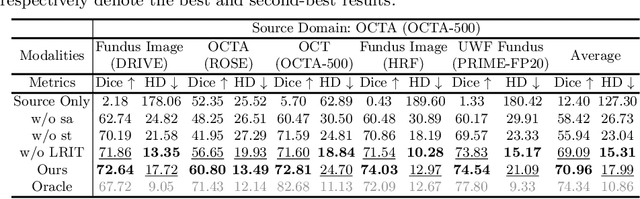
Unsupervised domain adaptation has been proposed recently to tackle the so-called domain shift between training data and test data with different distributions. However, most of them only focus on single-target domain adaptation and cannot be applied to the scenario with multiple target domains. In this paper, we propose RVms, a novel unsupervised multi-target domain adaptation approach to segment retinal vessels (RVs) from multimodal and multicenter retinal images. RVms mainly consists of a style augmentation and transfer (SAT) module and a dual-teacher knowledge distillation (DTKD) module. SAT augments and clusters images into source-similar domains and source-dissimilar domains via B\'ezier and Fourier transformations. DTKD utilizes the augmented and transformed data to train two teachers, one for source-similar domains and the other for source-dissimilar domains. Afterwards, knowledge distillation is performed to iteratively distill different domain knowledge from teachers to a generic student. The local relative intensity transformation is employed to characterize RVs in a domain invariant manner and promote the generalizability of teachers and student models. Moreover, we construct a new multimodal and multicenter vascular segmentation dataset from existing publicly-available datasets, which can be used to benchmark various domain adaptation and domain generalization methods. Through extensive experiments, RVms is found to be very close to the target-trained Oracle in terms of segmenting the RVs, largely outperforming other state-of-the-art methods.