 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCICADA: Cross-Domain Interpretable Coding for Anomaly Detection and Adaptation in Multivariate Time Series
May 01, 2025Unsupervised Time series anomaly detection plays a crucial role in applications across industries. However, existing methods face significant challenges due to data distributional shifts across different domains, which are exacerbated by the non-stationarity of time series over time. Existing models fail to generalize under multiple heterogeneous source domains and emerging unseen new target domains. To fill the research gap, we introduce CICADA (Cross-domain Interpretable Coding for Anomaly Detection and Adaptation), with four key innovations: (1) a mixture of experts (MOE) framework that captures domain-agnostic anomaly features with high flexibility and interpretability; (2) a novel selective meta-learning mechanism to prevent negative transfer between dissimilar domains, (3) an adaptive expansion algorithm for emerging heterogeneous domain expansion, and (4) a hierarchical attention structure that quantifies expert contributions during fusion to enhance interpretability further.Extensive experiments on synthetic and real-world industrial datasets demonstrate that CICADA outperforms state-of-the-art methods in both cross-domain detection performance and interpretability.
Evidence-Driven Retrieval Augmented Response Generation for Online Misinformation
Mar 22, 2024



The proliferation of online misinformation has posed significant threats to public interest. While numerous online users actively participate in the combat against misinformation, many of such responses can be characterized by the lack of politeness and supporting facts. As a solution, text generation approaches are proposed to automatically produce counter-misinformation responses. Nevertheless, existing methods are often trained end-to-end without leveraging external knowledge, resulting in subpar text quality and excessively repetitive responses. In this paper, we propose retrieval augmented response generation for online misinformation (RARG), which collects supporting evidence from scientific sources and generates counter-misinformation responses based on the evidences. In particular, our RARG consists of two stages: (1) evidence collection, where we design a retrieval pipeline to retrieve and rerank evidence documents using a database comprising over 1M academic articles; (2) response generation, in which we align large language models (LLMs) to generate evidence-based responses via reinforcement learning from human feedback (RLHF). We propose a reward function to maximize the utilization of the retrieved evidence while maintaining the quality of the generated text, which yields polite and factual responses that clearly refutes misinformation. To demonstrate the effectiveness of our method, we study the case of COVID-19 and perform extensive experiments with both in- and cross-domain datasets, where RARG consistently outperforms baselines by generating high-quality counter-misinformation responses.
Multi-robot task allocation for safe planning under dynamic uncertainties
Mar 02, 2021
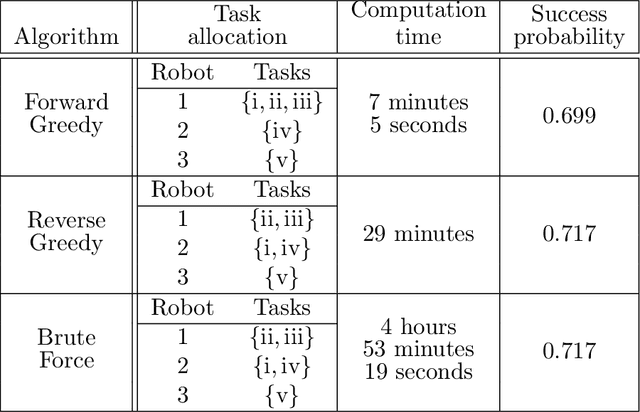
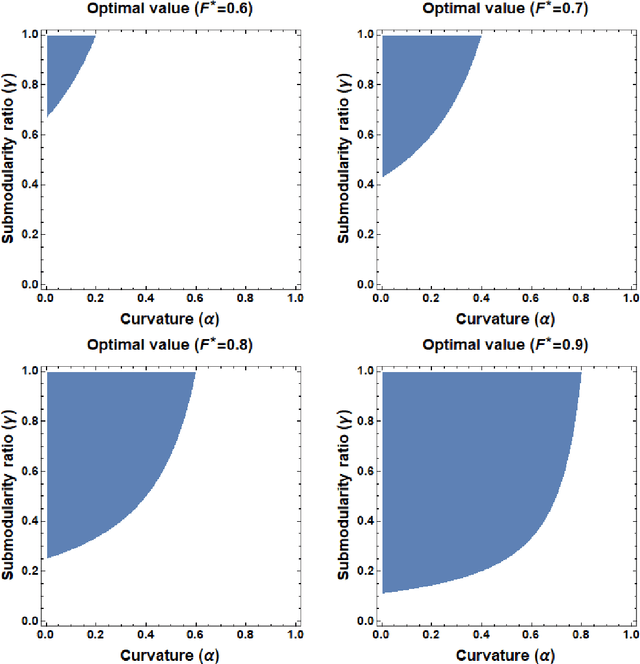
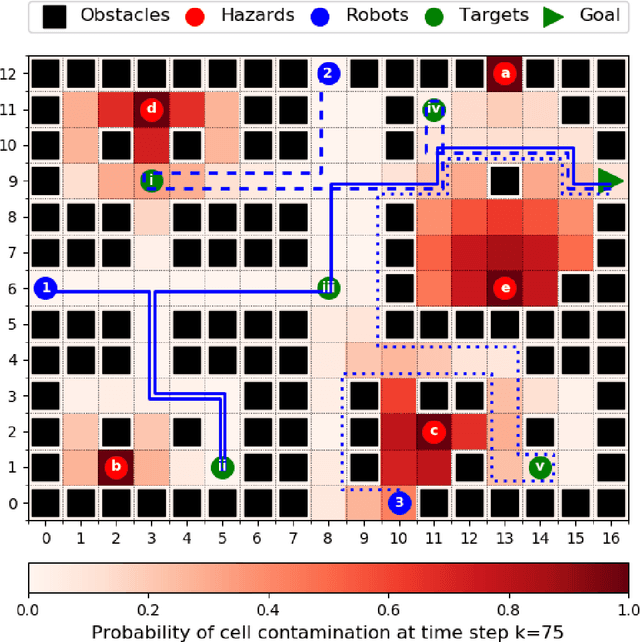
This paper considers the problem of multi-robot safe mission planning in uncertain dynamic environments. This problem arises in several applications including safety-critical exploration, surveillance, and emergency rescue missions. Computation of a multi-robot optimal control policy is challenging not only because of the complexity of incorporating dynamic uncertainties while planning, but also because of the exponential growth in problem size as a function of the number of robots. Leveraging recent works obtaining a tractable safety maximizing plan for a single robot, we propose a scalable two-stage framework to solve the problem at hand. Specifically, the problem is split into a low-level single-agent planning problem and a high-level task allocation problem. The low-level problem uses an efficient approximation of stochastic reachability for a Markov decision process to handle the dynamic uncertainty. The task allocation, on the other hand, is solved using polynomial-time forward and reverse greedy heuristics. The safety objective of our multi-robot safe planning problem allows an implementation of the greedy heuristics through a distributed auction-based approach. Moreover, by leveraging the properties of the safety objective function, we ensure provable performance bounds on the safety of the approximate solutions proposed by these two heuristics. Our result is illustrated through case studies.
Safe Mission Planning under Dynamical Uncertainties
Mar 05, 2020


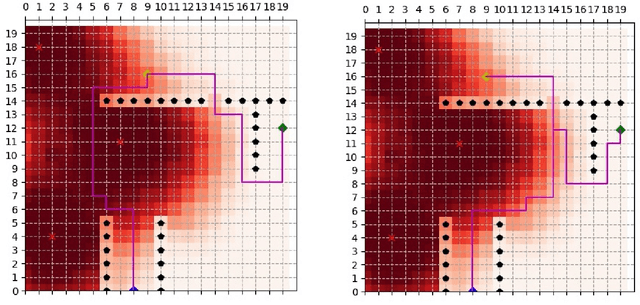
This paper considers safe robot mission planning in uncertain dynamical environments. This problem arises in applications such as surveillance, emergency rescue, and autonomous driving. It is a challenging problem due to modeling and integrating dynamical uncertainties into a safe planning framework, and finding a solution in a computationally tractable way. In this work, we first develop a probabilistic model for dynamical uncertainties. Then, we provide a framework to generate a path that maximizes safety for complex missions by incorporating the uncertainty model. We also devise a Monte Carlo method to obtain a safe path efficiently. Finally, we evaluate the performance of our approach and compare it to potential alternatives in several case studies.