 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropertyGPT: LLM-driven Formal Verification of Smart Contracts through Retrieval-Augmented Property Generation
May 04, 2024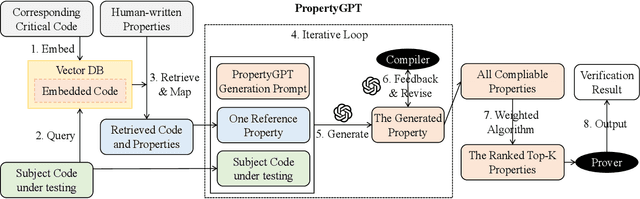
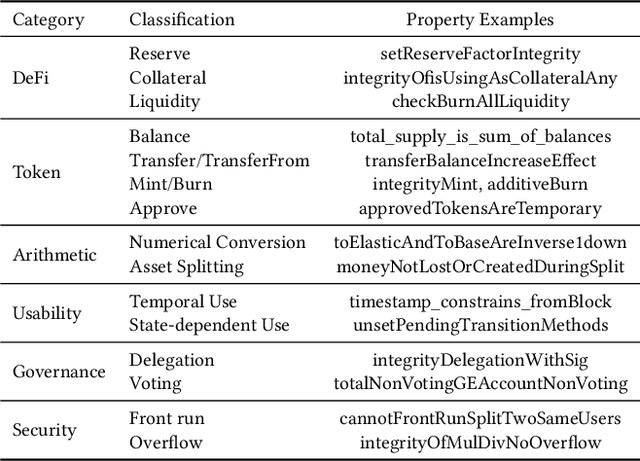

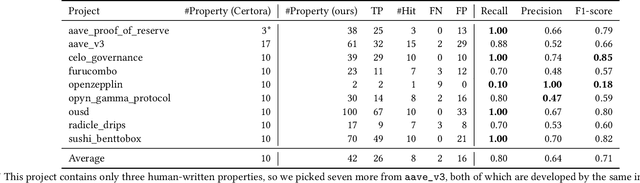
With recent advances in large language models (LLMs), this paper explores the potential of leveraging state-of-the-art LLMs, such as GPT-4, to transfer existing human-written properties (e.g., those from Certora auditing reports) and automatically generate customized properties for unknown code. To this end, we embed existing properties into a vector database and retrieve a reference property for LLM-based in-context learning to generate a new prop- erty for a given code. While this basic process is relatively straight- forward, ensuring that the generated properties are (i) compilable, (ii) appropriate, and (iii) runtime-verifiable presents challenges. To address (i), we use the compilation and static analysis feedback as an external oracle to guide LLMs in iteratively revising the generated properties. For (ii), we consider multiple dimensions of similarity to rank the properties and employ a weighted algorithm to identify the top-K properties as the final result. For (iii), we design a dedicated prover to formally verify the correctness of the generated prop- erties. We have implemented these strategies into a novel system called PropertyGPT, with 623 human-written properties collected from 23 Certora projects. Our experiments show that PropertyGPT can generate comprehensive and high-quality properties, achieving an 80% recall compared to the ground truth. It successfully detected 26 CVEs/attack incidents out of 37 tested and also uncovered 12 zero-day vulnerabilities, resulting in $8,256 bug bounty rewards.
LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs' Vulnerability Reasoning
Jan 29, 2024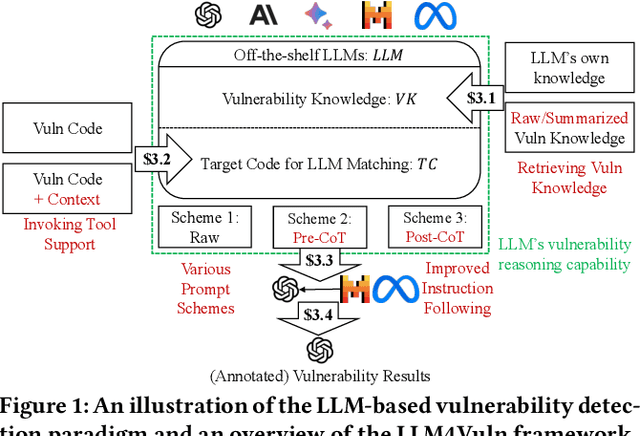

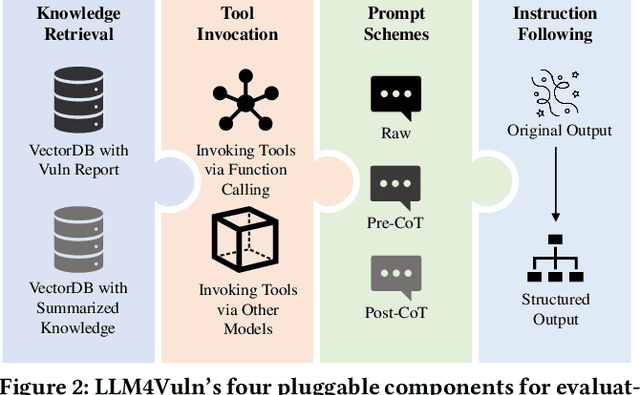
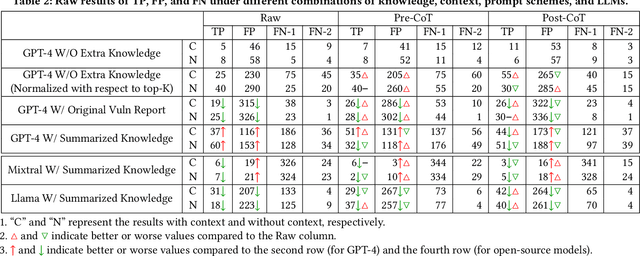
Large language models (LLMs) have demonstrated significant potential for many downstream tasks, including those requiring human-level intelligence, such as vulnerability detection. However, recent attempts to use LLMs for vulnerability detection are still preliminary, as they lack an in-depth understanding of a subject LLM's vulnerability reasoning capability -- whether it originates from the model itself or from external assistance, such as invoking tool support and retrieving vulnerability knowledge. In this paper, we aim to decouple LLMs' vulnerability reasoning capability from their other capabilities, including the ability to actively seek additional information (e.g., via function calling in SOTA models), adopt relevant vulnerability knowledge (e.g., via vector-based matching and retrieval), and follow instructions to output structured results. To this end, we propose a unified evaluation framework named LLM4Vuln, which separates LLMs' vulnerability reasoning from their other capabilities and evaluates how LLMs' vulnerability reasoning could be enhanced when combined with the enhancement of other capabilities. To demonstrate the effectiveness of LLM4Vuln, we have designed controlled experiments using 75 ground-truth smart contract vulnerabilities, which were extensively audited as high-risk on Code4rena from August to November 2023, and tested them in 4,950 different scenarios across three representative LLMs (GPT-4, Mixtral, and Code Llama). Our results not only reveal ten findings regarding the varying effects of knowledge enhancement, context supplementation, prompt schemes, and models but also enable us to identify 9 zero-day vulnerabilities in two pilot bug bounty programs with over 1,000 USD being awarded.