 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJADS: A Framework for Self-supervised Joint Aspect Discovery and Summarization
Paper and Code
May 28, 2024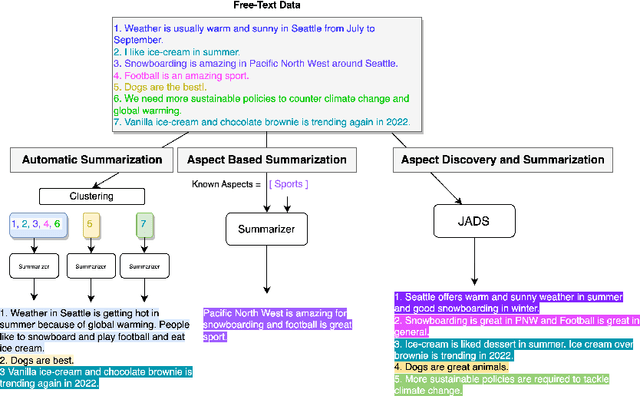
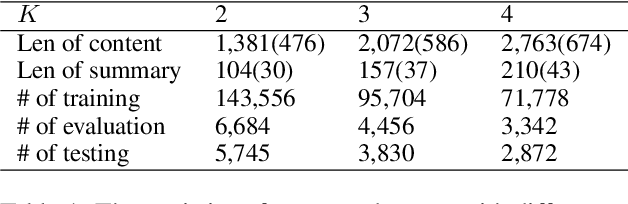
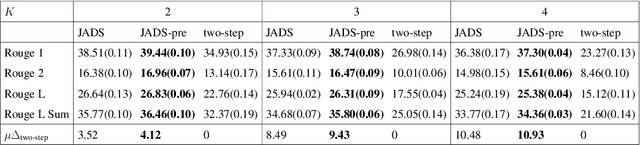
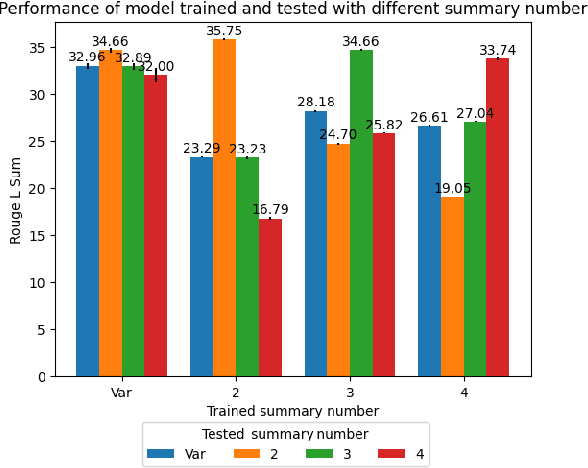
To generate summaries that include multiple aspects or topics for text documents, most approaches use clustering or topic modeling to group relevant sentences and then generate a summary for each group. These approaches struggle to optimize the summarization and clustering algorithms jointly. On the other hand, aspect-based summarization requires known aspects. Our solution integrates topic discovery and summarization into a single step. Given text data, our Joint Aspect Discovery and Summarization algorithm (JADS) discovers aspects from the input and generates a summary of the topics, in one step. We propose a self-supervised framework that creates a labeled dataset by first mixing sentences from multiple documents (e.g., CNN/DailyMail articles) as the input and then uses the article summaries from the mixture as the labels. The JADS model outperforms the two-step baselines. With pretraining, the model achieves better performance and stability. Furthermore, embeddings derived from JADS exhibit superior clustering capabilities. Our proposed method achieves higher semantic alignment with ground truth and is factual.