 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODABS: Multi-Objective Learning for Dynamic Aspect-Based Summarization
Paper and Code

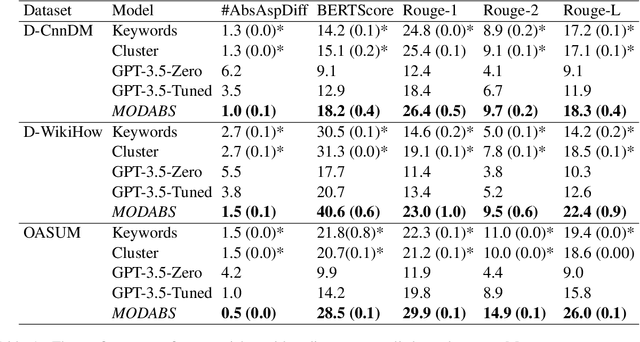
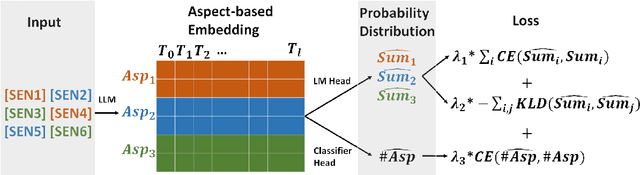
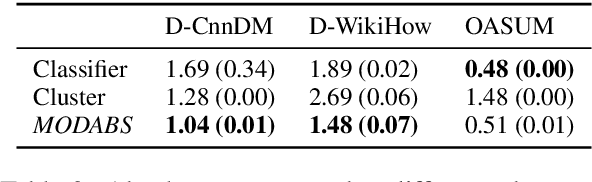
The rapid proliferation of online content necessitates effective summarization methods, among which dynamic aspect-based summarization stands out. Unlike its traditional counterpart, which assumes a fixed set of known aspects, this approach adapts to the varied aspects of the input text. We introduce a novel multi-objective learning framework employing a Longformer-Encoder-Decoder for this task. The framework optimizes aspect number prediction, minimizes disparity between generated and reference summaries for each aspect, and maximizes dissimilarity across aspect-specific summaries. Extensive experiments show our method significantly outperforms baselines on three diverse datasets, largely due to the effective alignment of generated and reference aspect counts without sacrificing single-aspect summarization quality.