 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerial Position Effects of Large Language Models
Paper and Code
Jun 23, 2024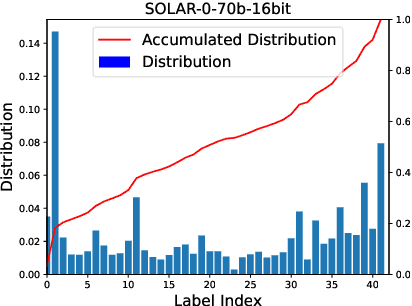
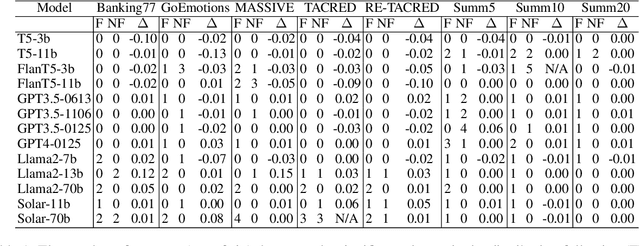

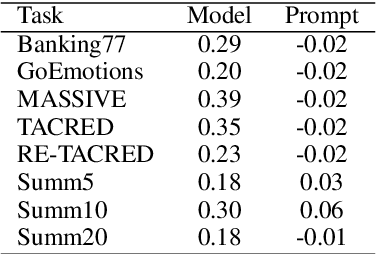
Large Language Models (LLMs) have shown remarkable capabilities in zero-shot learning applications, generating responses to queries using only pre-training information without the need for additional fine-tuning. This represents a significant departure from traditional machine learning approaches. Previous research has indicated that LLMs may exhibit serial position effects, such as primacy and recency biases, which are well-documented cognitive biases in human psychology. Our extensive testing across various tasks and models confirms the widespread occurrence of these effects, although their intensity varies. We also discovered that while carefully designed prompts can somewhat mitigate these biases, their effectiveness is inconsistent. These findings underscore the significance of serial position effects during the inference process, particularly in scenarios where there are no ground truth labels, highlighting the need for greater focus on addressing these effects in LLM applications.