 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Gestalt Principle of Closure in Deep Convolutional Neural Networks
Nov 01, 2024Deep neural networks perform well in object recognition, but do they perceive objects like humans? This study investigates the Gestalt principle of closure in convolutional neural networks. We propose a protocol to identify closure and conduct experiments using simple visual stimuli with progressively removed edge sections. We evaluate well-known networks on their ability to classify incomplete polygons. Our findings reveal a performance degradation as the edge removal percentage increases, indicating that current models heavily rely on complete edge information for accurate classification. The data used in our study is available on Github.
Finding Closure: A Closer Look at the Gestalt Law of Closure in Convolutional Neural Networks
Aug 22, 2024



The human brain has an inherent ability to fill in gaps to perceive figures as complete wholes, even when parts are missing or fragmented. This phenomenon is known as Closure in psychology, one of the Gestalt laws of perceptual organization, explaining how the human brain interprets visual stimuli. Given the importance of Closure for human object recognition, we investigate whether neural networks rely on a similar mechanism. Exploring this crucial human visual skill in neural networks has the potential to highlight their comparability to humans. Recent studies have examined the Closure effect in neural networks. However, they typically focus on a limited selection of Convolutional Neural Networks (CNNs) and have not reached a consensus on their capability to perform Closure. To address these gaps, we present a systematic framework for investigating the Closure principle in neural networks. We introduce well-curated datasets designed to test for Closure effects, including both modal and amodal completion. We then conduct experiments on various CNNs employing different measurements. Our comprehensive analysis reveals that VGG16 and DenseNet-121 exhibit the Closure effect, while other CNNs show variable results. We interpret these findings by blending insights from psychology and neural network research, offering a unique perspective that enhances transparency in understanding neural networks. Our code and dataset will be made available on GitHub.
Choosing Transfer Languages for Cross-Lingual Learning
Jun 07, 2019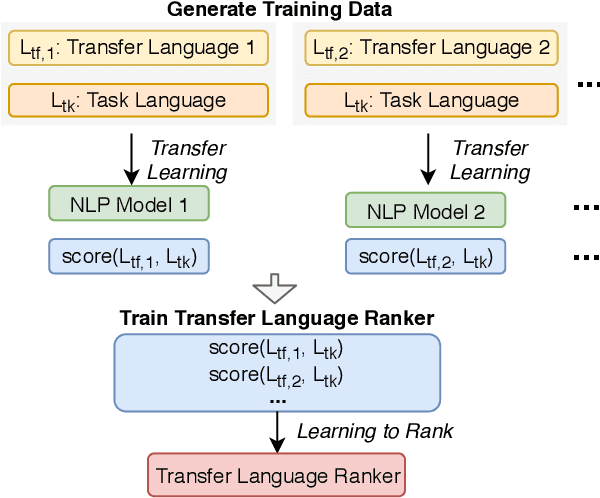
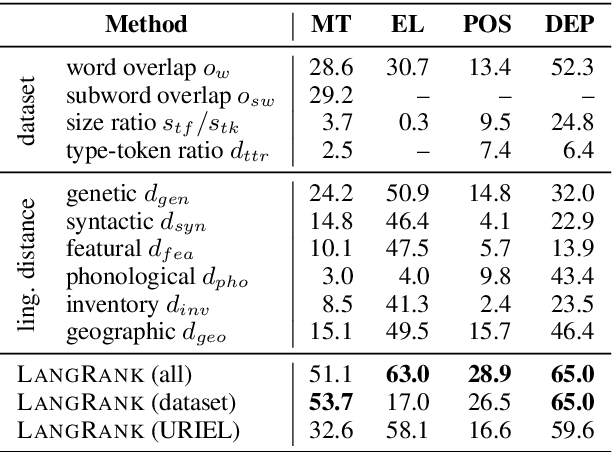
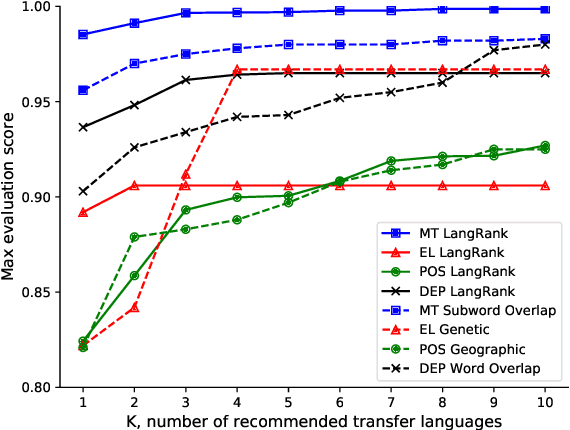
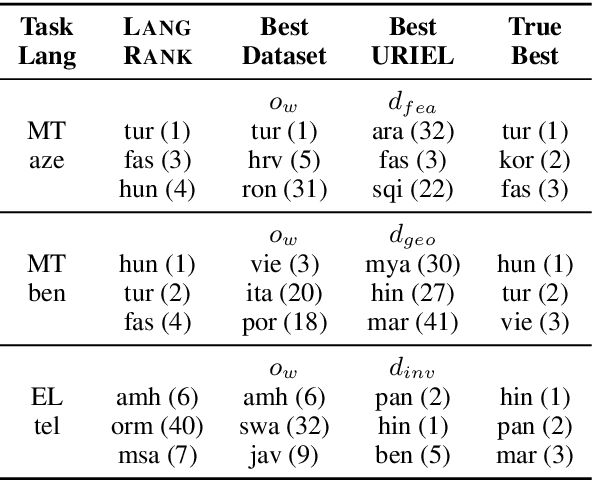
Cross-lingual transfer, where a high-resource transfer language is used to improve the accuracy of a low-resource task language, is now an invaluable tool for improving performance of natural language processing (NLP) on low-resource languages. However, given a particular task language, it is not clear which language to transfer from, and the standard strategy is to select languages based on ad hoc criteria, usually the intuition of the experimenter. Since a large number of features contribute to the success of cross-lingual transfer (including phylogenetic similarity, typological properties, lexical overlap, or size of available data), even the most enlightened experimenter rarely considers all these factors for the particular task at hand. In this paper, we consider this task of automatically selecting optimal transfer languages as a ranking problem, and build models that consider the aforementioned features to perform this prediction. In experiments on representative NLP tasks, we demonstrate that our model predicts good transfer languages much better than ad hoc baselines considering single features in isolation, and glean insights on what features are most informative for each different NLP tasks, which may inform future ad hoc selection even without use of our method. Code, data, and pre-trained models are available at https://github.com/neulab/langrank
Towards a General-Purpose Linguistic Annotation Backend
Dec 13, 2018



Language documentation is inherently a time-intensive process; transcription, glossing, and corpus management consume a significant portion of documentary linguists' work. Advances in natural language processing can help to accelerate this work, using the linguists' past decisions as training material, but questions remain about how to prioritize human involvement. In this extended abstract, we describe the beginnings of a new project that will attempt to ease this language documentation process through the use of natural language processing (NLP) technology. It is based on (1) methods to adapt NLP tools to new languages, based on recent advances in massively multilingual neural networks, and (2) backend APIs and interfaces that allow linguists to upload their data. We then describe our current progress on two fronts: automatic phoneme transcription, and glossing. Finally, we briefly describe our future directions.
Whale swarm algorithm with the mechanism of identifying and escaping from extreme point for multimodal function optimization
Jul 10, 2018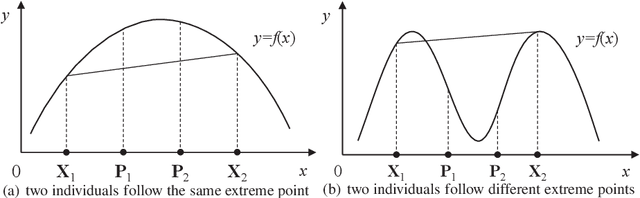
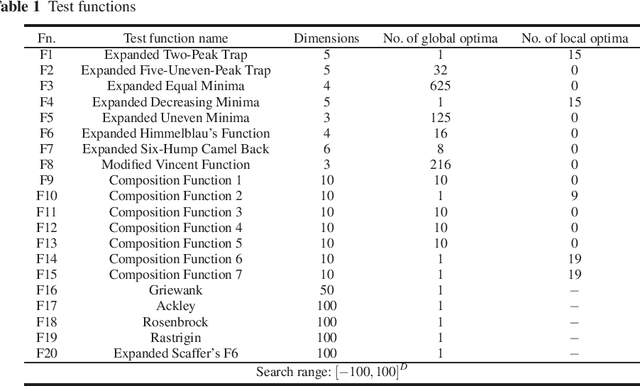


Most real-world optimization problems often come with multiple global optima or local optima. Therefore, increasing niching metaheuristic algorithms, which devote to finding multiple optima in a single run, are developed to solve these multimodal optimization problems. However, there are two difficulties urgently to be solved for most existing niching metaheuristic algorithms: how to set the optimal values of niching parameters for different optimization problems, and how to jump out of the local optima efficiently. These two difficulties limited their practicality largely. Based on Whale Swarm Algorithm (WSA) we proposed previously, this paper presents a new multimodal optimizer named WSA with Iterative Counter (WSA-IC) to address these two difficulties. In the one hand, WSA-IC improves the iteration rule of the original WSA for multimodal optimization, which removes the need of specifying different values of attenuation coefficient for different problems to form multiple subpopulations, without introducing any niching parameter. In the other hand, WSA-IC enables the identification of extreme point during iterations relying on two new parameters (i.e., stability threshold Ts and fitness threshold Tf), to jump out of the located extreme point. Moreover, the convergence of WSA-IC is proved. Finally, the proposed WSA-IC is compared with several niching metaheuristic algorithms on CEC2015 niching benchmark test functions and five additional classical multimodal functions with high dimensions. The experimental results demonstrate that WSA-IC statistically outperforms other niching metaheuristic algorithms on most test functions.