 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSevolve: Enabling Real-Time Adaptive Scheduling on Dynamic Shop Floor with LLM-Evolved Heuristic Portfolios
Mar 29, 2026In dynamic manufacturing environments, disruptions such as machine breakdowns and new order arrivals continuously shift the optimal dispatching strategy, making adaptive rule selection essential. Existing LLM-powered Automatic Heuristic Design (AHD) frameworks evolve toward a single elite rule that cannot meet this adaptability demand. To address this, we present DSevolve, an industrial scheduling framework that evolves a quality-diverse portfolio of dispatching rules offline and adaptively deploys them online with second-level response time. Multi-persona seeding and topology-aware evolutionary operators produce a behaviorally diverse rule archive indexed by a MAP-Elites feature space. Upon each disruption event, a probe-based fingerprinting mechanism characterizes the current shop floor state, retrieves high-quality candidate rules from an offline knowledge base, and selects the best one via rapid look-ahead simulation. Evaluated on 500 dynamic flexible job shop instances derived from real industrial data, DSevolve outperforms state-of-the-art AHD frameworks, classical dispatching rules, genetic programming, and deep reinforcement learning, offering a practical and deployable solution for intelligent shop floor scheduling.
AlignDrive: Aligned Lateral-Longitudinal Planning for End-to-End Autonomous Driving
Jan 05, 2026End-to-end autonomous driving has rapidly progressed, enabling joint perception and planning in complex environments. In the planning stage, state-of-the-art (SOTA) end-to-end autonomous driving models decouple planning into parallel lateral and longitudinal predictions. While effective, this parallel design can lead to i) coordination failures between the planned path and speed, and ii) underutilization of the drive path as a prior for longitudinal planning, thus redundantly encoding static information. To address this, we propose a novel cascaded framework that explicitly conditions longitudinal planning on the drive path, enabling coordinated and collision-aware lateral and longitudinal planning. Specifically, we introduce a path-conditioned formulation that explicitly incorporates the drive path into longitudinal planning. Building on this, the model predicts longitudinal displacements along the drive path rather than full 2D trajectory waypoints. This design simplifies longitudinal reasoning and more tightly couples it with lateral planning. Additionally, we introduce a planning-oriented data augmentation strategy that simulates rare safety-critical events, such as vehicle cut-ins, by adding agents and relabeling longitudinal targets to avoid collision. Evaluated on the challenging Bench2Drive benchmark, our method sets a new SOTA, achieving a driving score of 89.07 and a success rate of 73.18%, demonstrating significantly improved coordination and safety
Optimal Transport Regularization for Speech Text Alignment in Spoken Language Models
Aug 11, 2025Spoken Language Models (SLMs), which extend Large Language Models (LLMs) to perceive speech inputs, have gained increasing attention for their potential to advance speech understanding tasks. However, despite recent progress, studies show that SLMs often struggle to generalize across datasets, even for trained languages and tasks, raising concerns about whether they process speech in a text-like manner as intended. A key challenge underlying this limitation is the modality gap between speech and text representations. The high variability in speech embeddings may allow SLMs to achieve strong in-domain performance by exploiting unintended speech variations, ultimately hindering generalization. To mitigate this modality gap, we introduce Optimal Transport Regularization (OTReg), a method that formulates speech-text alignment as an optimal transport problem and derives a regularization loss to improve SLM training. In each training iteration, OTReg first establishes a structured correspondence between speech and transcript embeddings by determining the optimal transport plan, then incorporates the regularization loss based on this transport plan to optimize SLMs in generating speech embeddings that align more effectively with transcript embeddings. OTReg is lightweight, requiring no additional labels or learnable parameters, and integrates seamlessly into existing SLM training procedures. Extensive multilingual ASR experiments demonstrate that OTReg enhances speech-text alignment, mitigates the modality gap, and consequently improves SLM generalization across diverse datasets.
Automatic MILP Model Construction for Multi-Robot Task Allocation and Scheduling Based on Large Language Models
Mar 18, 2025With the accelerated development of Industry 4.0, intelligent manufacturing systems increasingly require efficient task allocation and scheduling in multi-robot systems. However, existing methods rely on domain expertise and face challenges in adapting to dynamic production constraints. Additionally, enterprises have high privacy requirements for production scheduling data, which prevents the use of cloud-based large language models (LLMs) for solution development. To address these challenges, there is an urgent need for an automated modeling solution that meets data privacy requirements. This study proposes a knowledge-augmented mixed integer linear programming (MILP) automated formulation framework, integrating local LLMs with domain-specific knowledge bases to generate executable code from natural language descriptions automatically. The framework employs a knowledge-guided DeepSeek-R1-Distill-Qwen-32B model to extract complex spatiotemporal constraints (82% average accuracy) and leverages a supervised fine-tuned Qwen2.5-Coder-7B-Instruct model for efficient MILP code generation (90% average accuracy). Experimental results demonstrate that the framework successfully achieves automatic modeling in the aircraft skin manufacturing case while ensuring data privacy and computational efficiency. This research provides a low-barrier and highly reliable technical path for modeling in complex industrial scenarios.
Automatic programming via large language models with population self-evolution for dynamic job shop scheduling problem
Oct 30, 2024Heuristic dispatching rules (HDRs) are widely regarded as effective methods for solving dynamic job shop scheduling problems (DJSSP) in real-world production environments. However, their performance is highly scenario-dependent, often requiring expert customization. To address this, genetic programming (GP) and gene expression programming (GEP) have been extensively used for automatic algorithm design. Nevertheless, these approaches often face challenges due to high randomness in the search process and limited generalization ability, hindering the application of trained dispatching rules to new scenarios or dynamic environments. Recently, the integration of large language models (LLMs) with evolutionary algorithms has opened new avenues for prompt engineering and automatic algorithm design. To enhance the capabilities of LLMs in automatic HDRs design, this paper proposes a novel population self-evolutionary (SeEvo) method, a general search framework inspired by the self-reflective design strategies of human experts. The SeEvo method accelerates the search process and enhances exploration capabilities. Experimental results show that the proposed SeEvo method outperforms GP, GEP, end-to-end deep reinforcement learning methods, and more than 10 common HDRs from the literature, particularly in unseen and dynamic scenarios.
Simple parameter-free self-attention approximation
Jul 22, 2023The hybrid model of self-attention and convolution is one of the methods to lighten ViT. The quadratic computational complexity of self-attention with respect to token length limits the efficiency of ViT on edge devices. We propose a self-attention approximation without training parameters, called SPSA, which captures global spatial features with linear complexity. To verify the effectiveness of SPSA combined with convolution, we conduct extensive experiments on image classification and object detection tasks.
Winning Solution for the CVPR2023 Visual Anomaly and Novelty Detection Challenge: Multimodal Prompting for Data-centric Anomaly Detection
Jun 15, 2023This technical report introduces the winning solution of the team \textit{Segment Any Anomaly} for the CVPR2023 Visual Anomaly and Novelty Detection (VAND) challenge. Going beyond uni-modal prompt, \textit{e.g.}, language prompt, we present a novel framework, \textit{i.e.}, Segment Any Anomaly + (SAA$+$), for zero-shot anomaly segmentation with multi-modal prompts for the regularization of cascaded modern foundation models. Inspired by the great zero-shot generalization ability of foundation models like Segment Anything, we first explore their assembly (SAA) to leverage diverse multi-modal prior knowledge for anomaly localization. Subsequently, we further introduce multimodal prompts (SAA$+$) derived from domain expert knowledge and target image context to enable the non-parameter adaptation of foundation models to anomaly segmentation. The proposed SAA$+$ model achieves state-of-the-art performance on several anomaly segmentation benchmarks, including VisA and MVTec-AD, in the zero-shot setting. We will release the code of our winning solution for the CVPR2023 VAND challenge at \href{Segment-Any-Anomaly}{https://github.com/caoyunkang/Segment-Any-Anomaly} \footnote{The extended-version paper with more details is available at ~\cite{cao2023segment}.}
Segment Any Anomaly without Training via Hybrid Prompt Regularization
May 18, 2023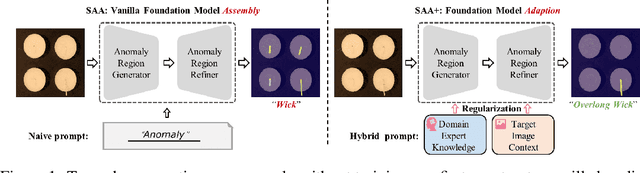
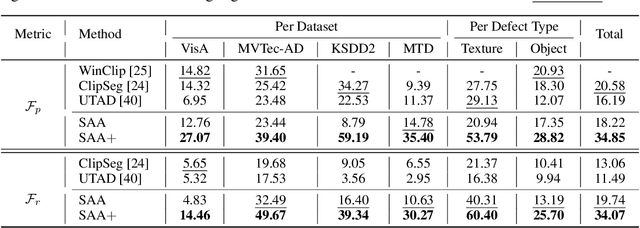
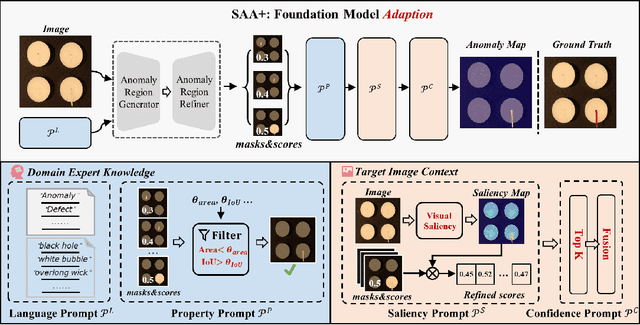
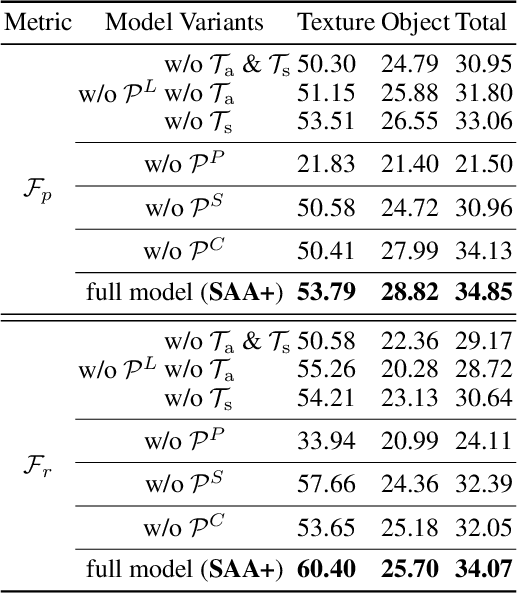
We present a novel framework, i.e., Segment Any Anomaly + (SAA+), for zero-shot anomaly segmentation with hybrid prompt regularization to improve the adaptability of modern foundation models. Existing anomaly segmentation models typically rely on domain-specific fine-tuning, limiting their generalization across countless anomaly patterns. In this work, inspired by the great zero-shot generalization ability of foundation models like Segment Anything, we first explore their assembly to leverage diverse multi-modal prior knowledge for anomaly localization. For non-parameter foundation model adaptation to anomaly segmentation, we further introduce hybrid prompts derived from domain expert knowledge and target image context as regularization. Our proposed SAA+ model achieves state-of-the-art performance on several anomaly segmentation benchmarks, including VisA, MVTec-AD, MTD, and KSDD2, in the zero-shot setting. We will release the code at \href{https://github.com/caoyunkang/Segment-Any-Anomaly}{https://github.com/caoyunkang/Segment-Any-Anomaly}.
FedDC: Federated Learning with Non-IID Data via Local Drift Decoupling and Correction
Mar 22, 2022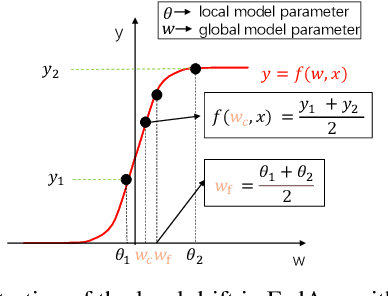
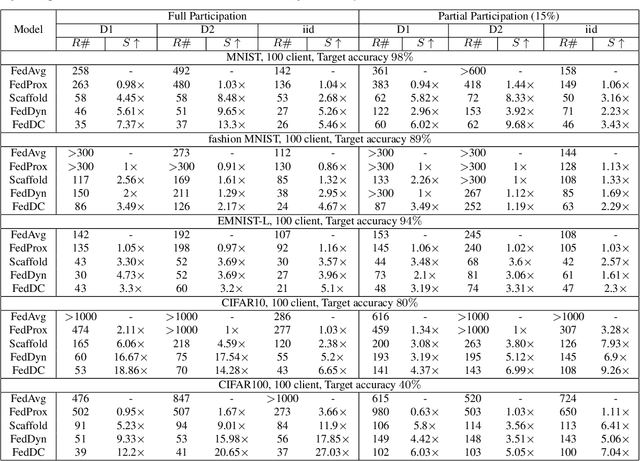
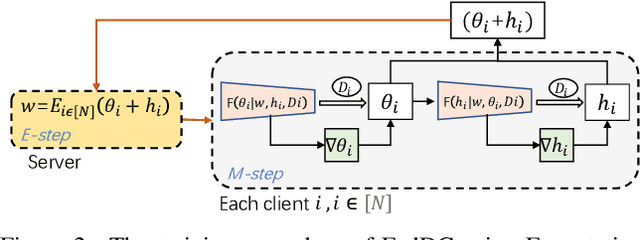
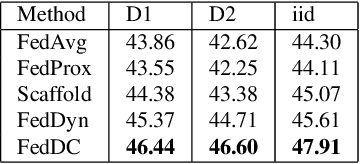
Federated learning (FL) allows multiple clients to collectively train a high-performance global model without sharing their private data. However, the key challenge in federated learning is that the clients have significant statistical heterogeneity among their local data distributions, which would cause inconsistent optimized local models on the client-side. To address this fundamental dilemma, we propose a novel federated learning algorithm with local drift decoupling and correction (FedDC). Our FedDC only introduces lightweight modifications in the local training phase, in which each client utilizes an auxiliary local drift variable to track the gap between the local model parameter and the global model parameters. The key idea of FedDC is to utilize this learned local drift variable to bridge the gap, i.e., conducting consistency in parameter-level. The experiment results and analysis demonstrate that FedDC yields expediting convergence and better performance on various image classification tasks, robust in partial participation settings, non-iid data, and heterogeneous clients.
A new neighborhood structure for job shop scheduling problems
Sep 07, 2021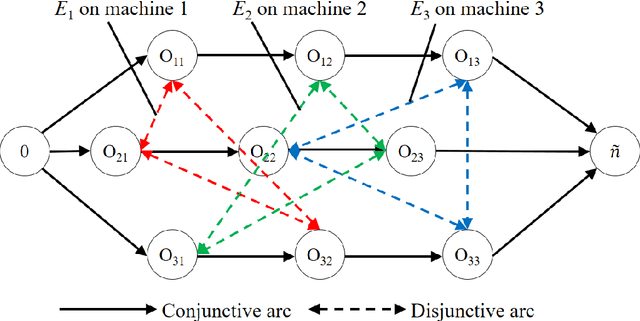
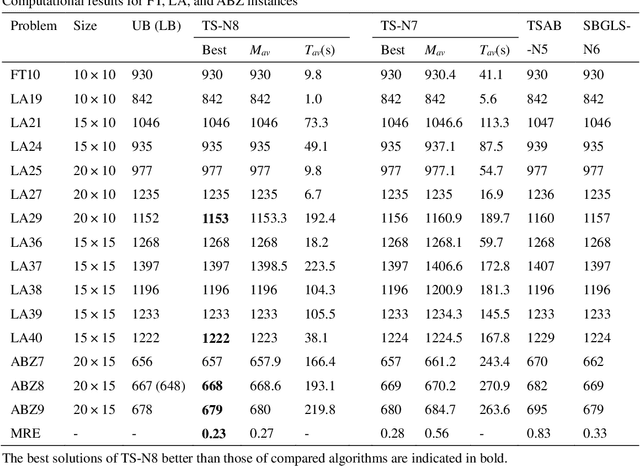
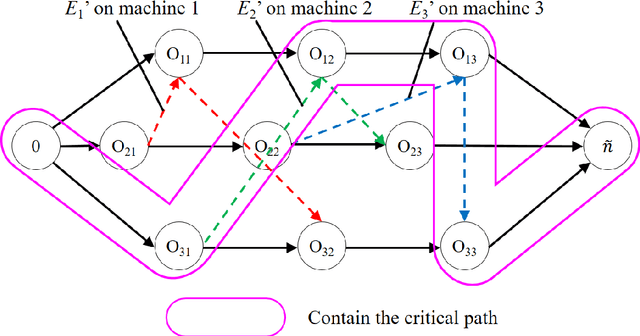
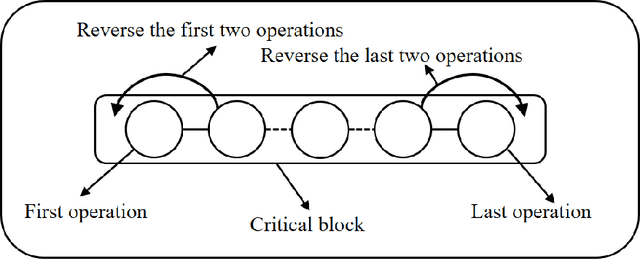
Job shop scheduling problem (JSP) is a widely studied NP-complete combinatorial optimization problem. Neighborhood structures play a critical role in solving JSP. At present, there are three state-of-the-art neighborhood structures, i.e., N5, N6, and N7. Improving the upper bounds of some famous benchmarks is inseparable from the role of these neighborhood structures. However, these existing neighborhood structures only consider the movement of critical operations within a critical block. According to our experiments, it is also possible to improve the makespan of a scheduling scheme by moving a critical operation outside its critical block. According to the above finding, this paper proposes a new N8 neighborhood structure considering the movement of critical operations within a critical block and the movement of critical operations outside the critical block. Besides, a neighborhood clipping method is designed to avoid invalid movement, reducing the computational time. Tabu search (TS) is a commonly used algorithm framework combined with neighborhood structures. This paper uses this framework to compare the N8 neighborhood structure with N5, N6, and N7 neighborhood structures on four famous benchmarks. The experimental results verify that the N8 neighborhood structure is more effective and efficient in solving JSP than the other state-of-the-art neighborhood structures.