 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZigzagPointMamba: Spatial-Semantic Mamba for Point Cloud Understanding
May 27, 2025State Space models (SSMs) such as PointMamba enable efficient feature extraction for point cloud self-supervised learning with linear complexity, outperforming Transformers in computational efficiency. However, existing PointMamba-based methods depend on complex token ordering and random masking, which disrupt spatial continuity and local semantic correlations. We propose ZigzagPointMamba to tackle these challenges. The core of our approach is a simple zigzag scan path that globally sequences point cloud tokens, enhancing spatial continuity by preserving the proximity of spatially adjacent point tokens. Nevertheless, random masking undermines local semantic modeling in self-supervised learning. To address this, we introduce a Semantic-Siamese Masking Strategy (SMS), which masks semantically similar tokens to facilitate reconstruction by integrating local features of original and similar tokens. This overcomes the dependence on isolated local features and enables robust global semantic modeling. Our pre-trained ZigzagPointMamba weights significantly improve downstream tasks, achieving a 1.59% mIoU gain on ShapeNetPart for part segmentation, a 0.4% higher accuracy on ModelNet40 for classification, and 0.19%, 1.22%, and 0.72% higher accuracies respectively for the classification tasks on the OBJ-BG, OBJ-ONLY, and PB-T50-RS subsets of ScanObjectNN. The code is available at: https://anonymous.4open.science/r/ZigzagPointMamba-1800/
Bearing Fault Diagnosis using Graph Sampling and Aggregation Network
Aug 12, 2024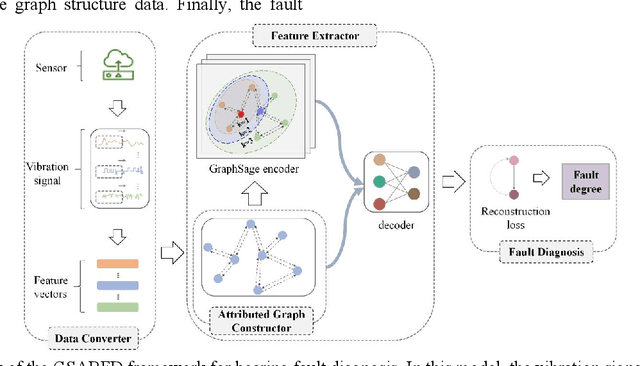
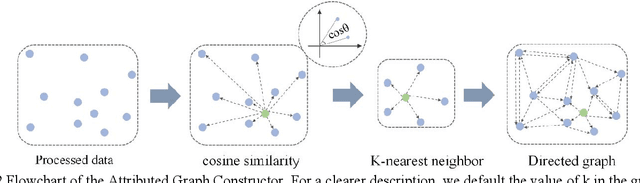

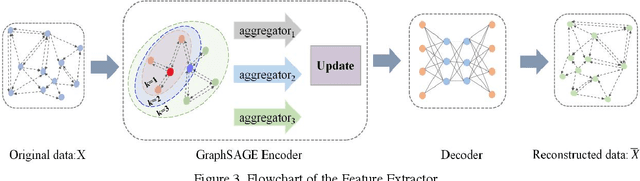
Bearing fault diagnosis technology has a wide range of practical applications in industrial production, energy and other fields. Timely and accurate detection of bearing faults plays an important role in preventing catastrophic accidents and ensuring product quality. Traditional signal analysis techniques and deep learning-based fault detection algorithms do not take into account the intricate correlation between signals, making it difficult to further improve detection accuracy. To address this problem, we introduced Graph Sampling and Aggregation (GraphSAGE) network and proposed GraphSAGE-based Bearing fault Diagnosis (GSABFD) algorithm. The original vibration signal is firstly sliced through a fixed size non-overlapping sliding window, and the sliced data is feature transformed using signal analysis methods; then correlations are constructed for the transformed vibration signal and further transformed into vertices in the graph; then the GraphSAGE network is used for training; finally the fault level of the object is calculated in the output layer of the network. The proposed algorithm is compared with five advanced algorithms in a real-world public dataset for experiments, and the results show that the GSABFD algorithm improves the AUC value by 5% compared with the next best algorithm.
Learning to Optimize Resource Assignment for Task Offloading in Mobile Edge Computing
Mar 15, 2022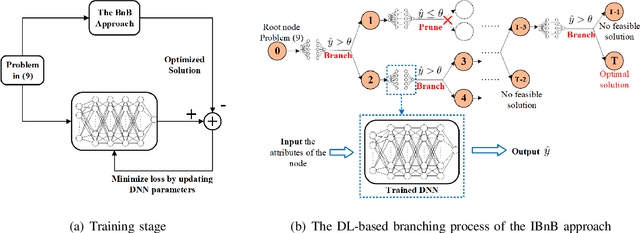
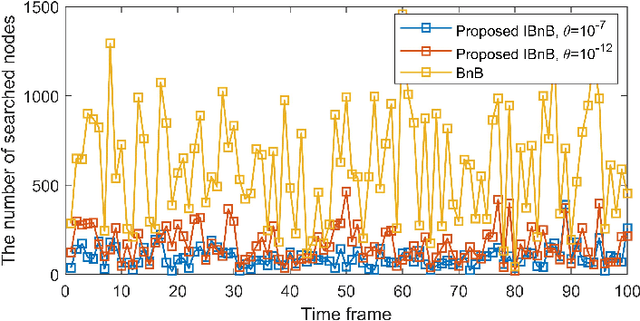
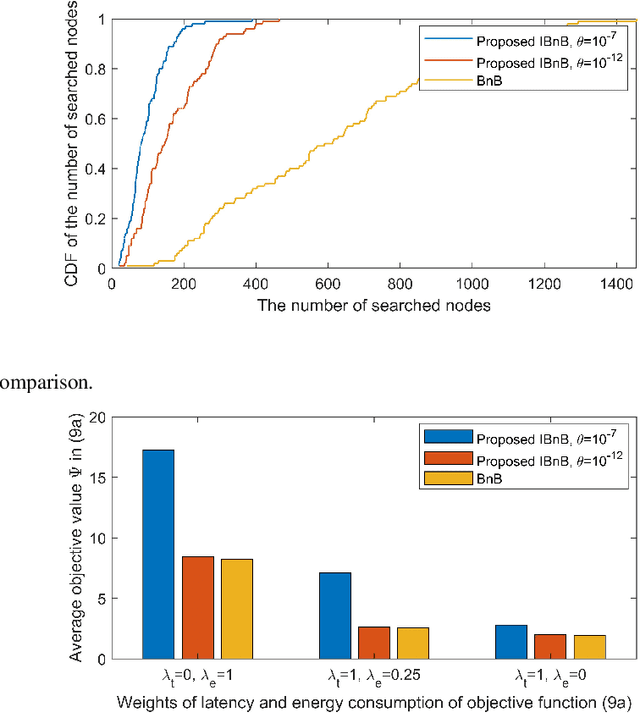
In this paper, we consider a multiuser mobile edge computing (MEC) system, where a mixed-integer offloading strategy is used to assist the resource assignment for task offloading. Although the conventional branch and bound (BnB) approach can be applied to solve this problem, a huge burden of computational complexity arises which limits the application of BnB. To address this issue, we propose an intelligent BnB (IBnB) approach which applies deep learning (DL) to learn the pruning strategy of the BnB approach. By using this learning scheme, the structure of the BnB approach ensures near-optimal performance and meanwhile DL-based pruning strategy significantly reduces the complexity. Numerical results verify that the proposed IBnB approach achieves optimal performance with complexity reduced by over 80%.
SDNet: mutil-branch for single image deraining using swin
May 31, 2021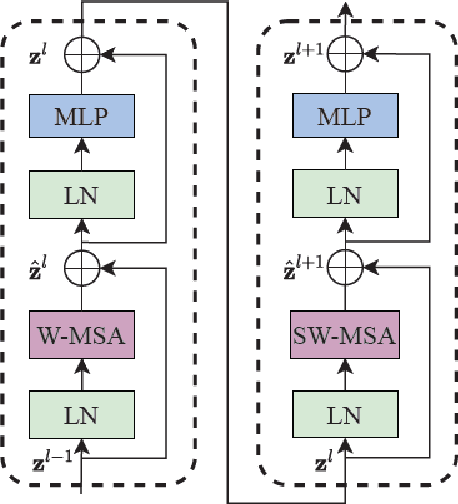
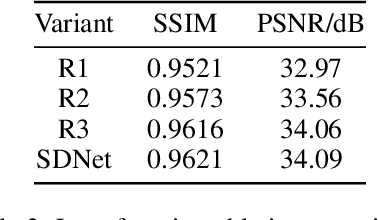
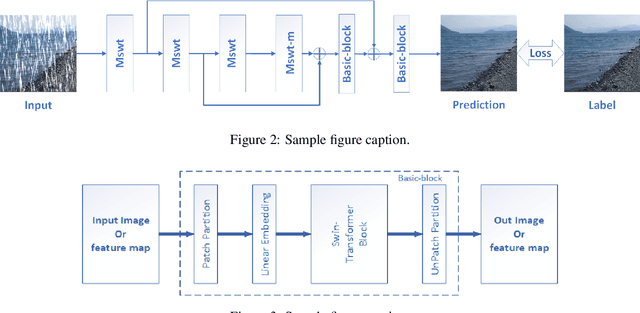
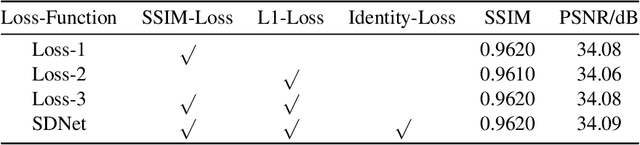
Rain streaks degrade the image quality and seriously affect the performance of subsequent computer vision tasks, such as autonomous driving, social security, etc. Therefore, removing rain streaks from a given rainy images is of great significance. Convolutional neural networks(CNN) have been widely used in image deraining tasks, however, the local computational characteristics of convolutional operations limit the development of image deraining tasks. Recently, the popular transformer has global computational features that can further facilitate the development of image deraining tasks. In this paper, we introduce Swin-transformer into the field of image deraining for the first time to study the performance and potential of Swin-transformer in the field of image deraining. Specifically, we improve the basic module of Swin-transformer and design a three-branch model to implement single-image rain removal. The former implements the basic rain pattern feature extraction, while the latter fuses different features to further extract and process the image features. In addition, we employ a jump connection to fuse deep features and shallow features. In terms of experiments, the existing public dataset suffers from image duplication and relatively homogeneous background. So we propose a new dataset Rain3000 to validate our model. Therefore, we propose a new dataset Rain3000 for validating our model. Experimental results on the publicly available datasets Rain100L, Rain100H and our dataset Rain3000 show that our proposed method has performance and inference speed advantages over the current mainstream single-image rain streaks removal models.The source code will be available at https://github.com/H-tfx/SDNet.
Dual-path CNN with Max Gated block for Text-Based Person Re-identification
Sep 20, 2020
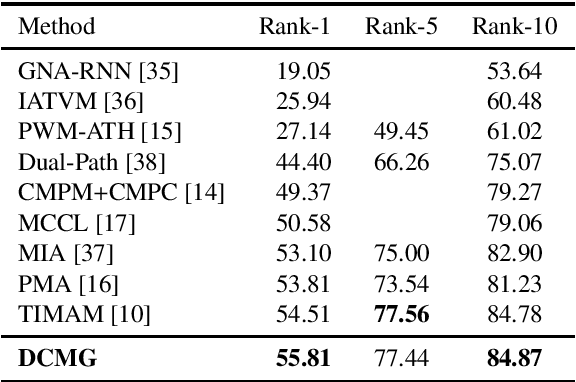
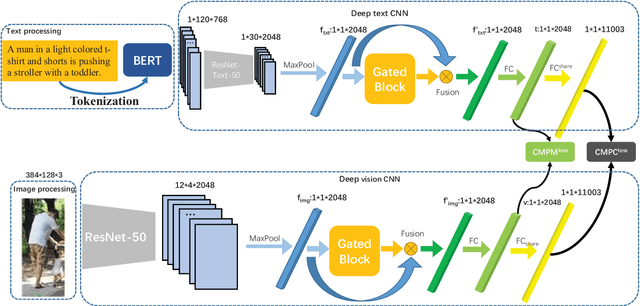
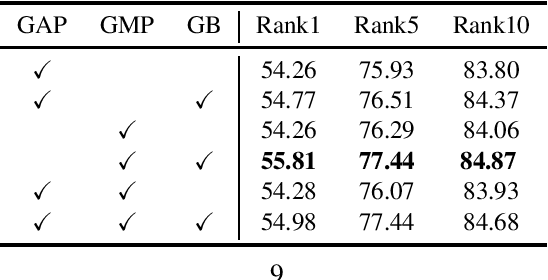
Text-based person re-identification(Re-id) is an important task in video surveillance, which consists of retrieving the corresponding person's image given a textual description from a large gallery of images. It is difficult to directly match visual contents with the textual descriptions due to the modality heterogeneity. On the one hand, the textual embeddings are not discriminative enough, which originates from the high abstraction of the textual descriptions. One the other hand,Global average pooling (GAP) is commonly utilized to extract more general or smoothed features implicitly but ignores salient local features, which are more important for the cross-modal matching problem. With that in mind, a novel Dual-path CNN with Max Gated block (DCMG) is proposed to extract discriminative word embeddings and make visual-textual association concern more on remarkable features of both modalities. The proposed framework is based on two deep residual CNNs jointly optimized with cross-modal projection matching (CMPM) loss and cross-modal projection classification (CMPC) loss to embed the two modalities into a joint feature space. First, the pre-trained language model, BERT, is combined with the convolutional neural network (CNN) to learn better word embeddings in the text-to-image matching domain. Second, the global Max pooling (GMP) layer is applied to make the visual-textual features focus more on the salient part. To further alleviate the noise of the maxed-pooled features, the gated block (GB) is proposed to produce an attention map that focuses on meaningful features of both modalities. Finally, extensive experiments are conducted on the benchmark dataset, CUHK-PEDES, in which our approach achieves the rank-1 score of 55.81% and outperforms the state-of-the-art method by 1.3%.