 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-path CNN with Max Gated block for Text-Based Person Re-identification
Paper and Code
Sep 20, 2020
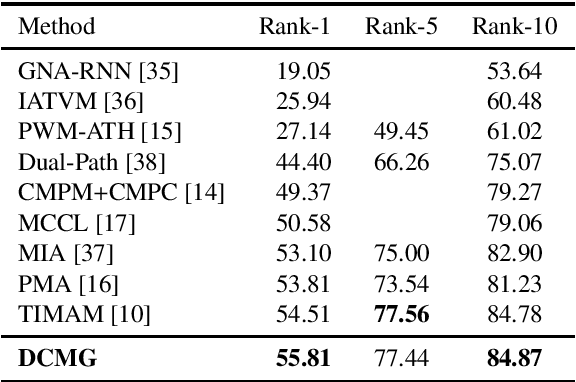
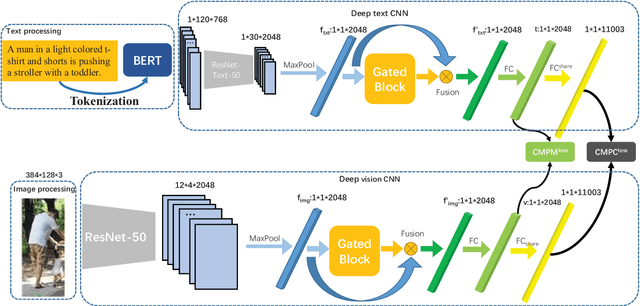
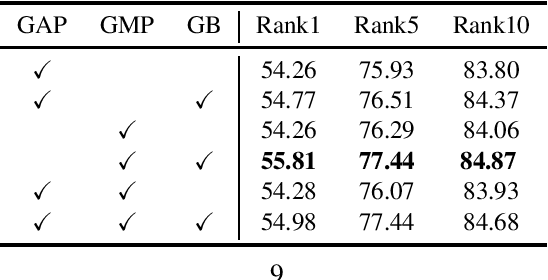
Text-based person re-identification(Re-id) is an important task in video surveillance, which consists of retrieving the corresponding person's image given a textual description from a large gallery of images. It is difficult to directly match visual contents with the textual descriptions due to the modality heterogeneity. On the one hand, the textual embeddings are not discriminative enough, which originates from the high abstraction of the textual descriptions. One the other hand,Global average pooling (GAP) is commonly utilized to extract more general or smoothed features implicitly but ignores salient local features, which are more important for the cross-modal matching problem. With that in mind, a novel Dual-path CNN with Max Gated block (DCMG) is proposed to extract discriminative word embeddings and make visual-textual association concern more on remarkable features of both modalities. The proposed framework is based on two deep residual CNNs jointly optimized with cross-modal projection matching (CMPM) loss and cross-modal projection classification (CMPC) loss to embed the two modalities into a joint feature space. First, the pre-trained language model, BERT, is combined with the convolutional neural network (CNN) to learn better word embeddings in the text-to-image matching domain. Second, the global Max pooling (GMP) layer is applied to make the visual-textual features focus more on the salient part. To further alleviate the noise of the maxed-pooled features, the gated block (GB) is proposed to produce an attention map that focuses on meaningful features of both modalities. Finally, extensive experiments are conducted on the benchmark dataset, CUHK-PEDES, in which our approach achieves the rank-1 score of 55.81% and outperforms the state-of-the-art method by 1.3%.