 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill it Merge? On The Causes of Model Mergeability
Jan 10, 2026Model merging has emerged as a promising technique for combining multiple fine-tuned models into a single multitask model without retraining. However, the factors that determine whether merging will succeed or fail remain poorly understood. In this work, we investigate why specific models are merged better than others. To do so, we propose a concrete, measurable definition of mergeability. We investigate several potential causes for high or low mergeability, highlighting the base model knowledge as a dominant factor: Models fine-tuned on instances that the base model knows better are more mergeable than models fine-tuned on instances that the base model struggles with. Based on our mergeability definition, we explore a simple weighted merging technique that better preserves weak knowledge in the base model.
Growing a Tail: Increasing Output Diversity in Large Language Models
Nov 05, 2024



How diverse are the outputs of large language models when diversity is desired? We examine the diversity of responses of various models to questions with multiple possible answers, comparing them with human responses. Our findings suggest that models' outputs are highly concentrated, reflecting a narrow, mainstream 'worldview', in comparison to humans, whose responses exhibit a much longer-tail. We examine three ways to increase models' output diversity: 1) increasing generation randomness via temperature sampling; 2) prompting models to answer from diverse perspectives; 3) aggregating outputs from several models. A combination of these measures significantly increases models' output diversity, reaching that of humans. We discuss implications of these findings for AI policy that wishes to preserve cultural diversity, an essential building block of a democratic social fabric.
Fast Forwarding Low-Rank Training
Sep 06, 2024



Parameter efficient finetuning methods like low-rank adaptation (LoRA) aim to reduce the computational costs of finetuning pretrained Language Models (LMs). Enabled by these low-rank settings, we propose an even more efficient optimization strategy: Fast Forward, a simple and effective approach to accelerate large segments of training. In a Fast Forward stage, we repeat the most recent optimizer step until the loss stops improving on a tiny validation set. By alternating between regular optimization steps and Fast Forward stages, Fast Forward provides up to an 87\% reduction in FLOPs and up to an 81\% reduction in train time over standard SGD with Adam. We validate Fast Forward by finetuning various models on different tasks and demonstrate that it speeds up training without compromising model performance. Additionally, we analyze when and how to apply Fast Forward.
ContraSim -- A Similarity Measure Based on Contrastive Learning
Mar 29, 2023Recent work has compared neural network representations via similarity-based analyses, shedding light on how different aspects (architecture, training data, etc.) affect models' internal representations. The quality of a similarity measure is typically evaluated by its success in assigning a high score to representations that are expected to be matched. However, existing similarity measures perform mediocrely on standard benchmarks. In this work, we develop a new similarity measure, dubbed ContraSim, based on contrastive learning. In contrast to common closed-form similarity measures, ContraSim learns a parameterized measure by using both similar and dissimilar examples. We perform an extensive experimental evaluation of our method, with both language and vision models, on the standard layer prediction benchmark and two new benchmarks that we introduce: the multilingual benchmark and the image-caption benchmark. In all cases, ContraSim achieves much higher accuracy than previous similarity measures, even when presented with challenging examples, and reveals new insights not captured by previous measures.
Robustness through Cognitive Dissociation Mitigation in Contrastive Adversarial Training
Mar 19, 2022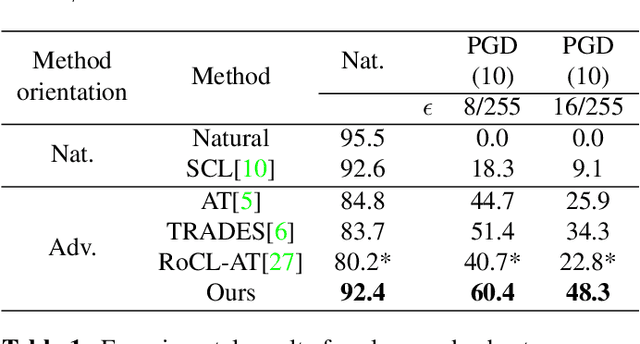
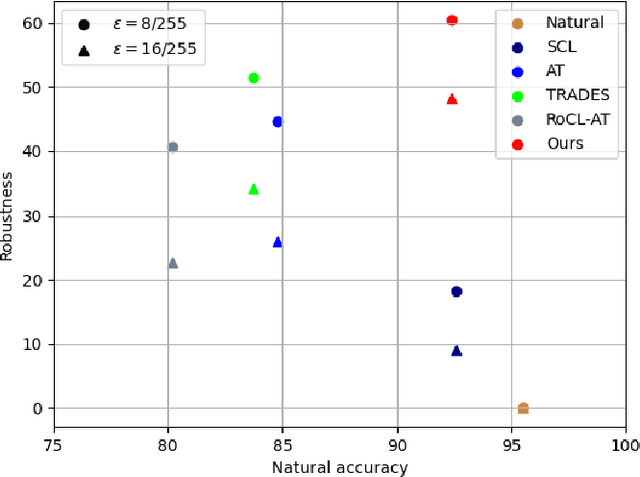
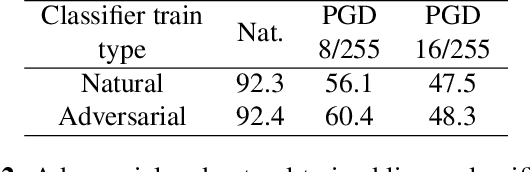
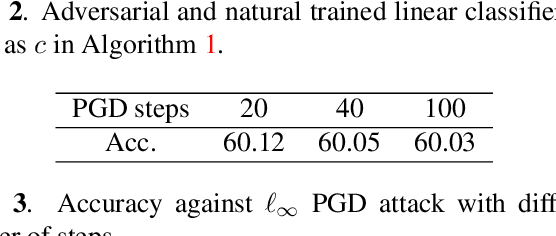
In this paper, we introduce a novel neural network training framework that increases model's adversarial robustness to adversarial attacks while maintaining high clean accuracy by combining contrastive learning (CL) with adversarial training (AT). We propose to improve model robustness to adversarial attacks by learning feature representations that are consistent under both data augmentations and adversarial perturbations. We leverage contrastive learning to improve adversarial robustness by considering an adversarial example as another positive example, and aim to maximize the similarity between random augmentations of data samples and their adversarial example, while constantly updating the classification head in order to avoid a cognitive dissociation between the classification head and the embedding space. This dissociation is caused by the fact that CL updates the network up to the embedding space, while freezing the classification head which is used to generate new positive adversarial examples. We validate our method, Contrastive Learning with Adversarial Features(CLAF), on the CIFAR-10 dataset on which it outperforms both robust accuracy and clean accuracy over alternative supervised and self-supervised adversarial learning methods.