 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack Against Image-Based Localization Neural Networks
Oct 11, 2022

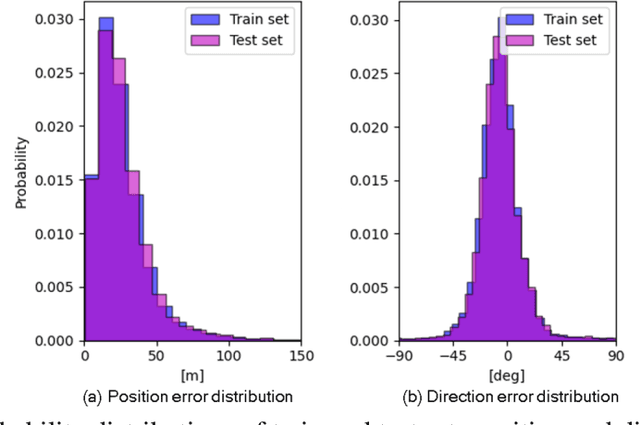
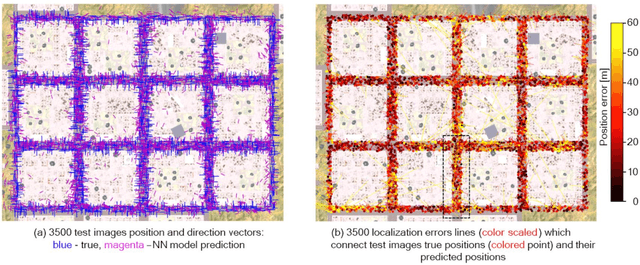
In this paper, we present a proof of concept for adversarially attacking the image-based localization module of an autonomous vehicle. This attack aims to cause the vehicle to perform a wrong navigational decisions and prevent it from reaching a desired predefined destination in a simulated urban environment. A database of rendered images allowed us to train a deep neural network that performs a localization task and implement, develop and assess the adversarial pattern. Our tests show that using this adversarial attack we can prevent the vehicle from turning at a given intersection. This is done by manipulating the vehicle's navigational module to falsely estimate its current position and thus fail to initialize the turning procedure until the vehicle misses the last opportunity to perform a safe turn in a given intersection.
Robustness through Cognitive Dissociation Mitigation in Contrastive Adversarial Training
Mar 19, 2022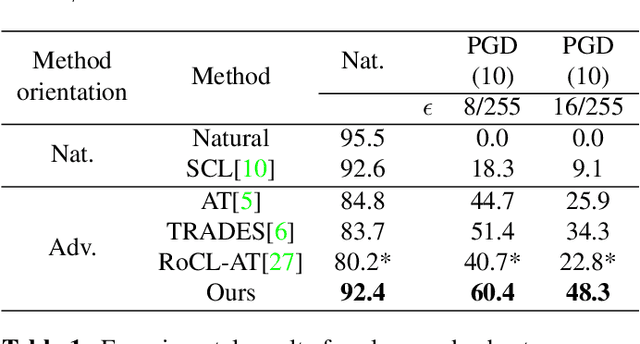
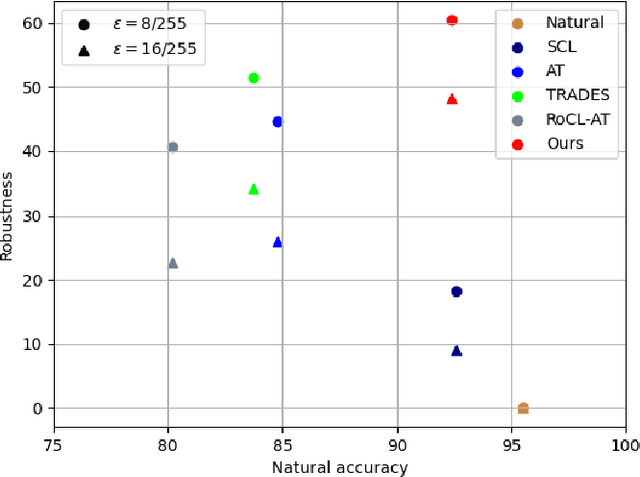
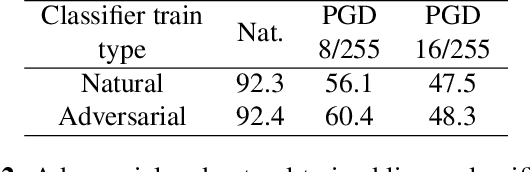
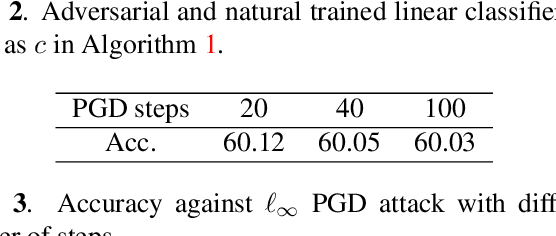
In this paper, we introduce a novel neural network training framework that increases model's adversarial robustness to adversarial attacks while maintaining high clean accuracy by combining contrastive learning (CL) with adversarial training (AT). We propose to improve model robustness to adversarial attacks by learning feature representations that are consistent under both data augmentations and adversarial perturbations. We leverage contrastive learning to improve adversarial robustness by considering an adversarial example as another positive example, and aim to maximize the similarity between random augmentations of data samples and their adversarial example, while constantly updating the classification head in order to avoid a cognitive dissociation between the classification head and the embedding space. This dissociation is caused by the fact that CL updates the network up to the embedding space, while freezing the classification head which is used to generate new positive adversarial examples. We validate our method, Contrastive Learning with Adversarial Features(CLAF), on the CIFAR-10 dataset on which it outperforms both robust accuracy and clean accuracy over alternative supervised and self-supervised adversarial learning methods.
Stealing Black-Box Functionality Using The Deep Neural Tree Architecture
Feb 23, 2020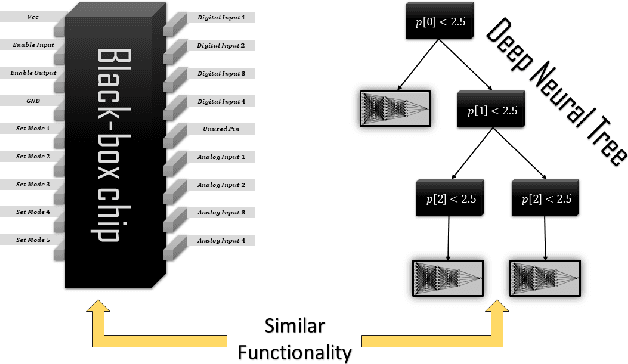
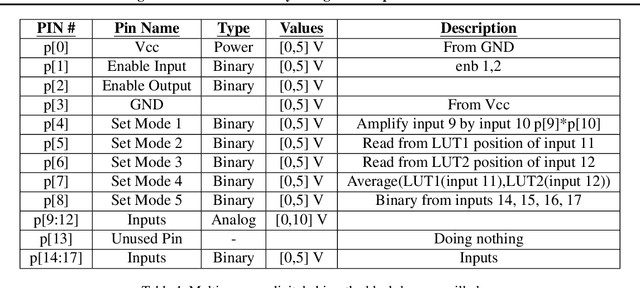
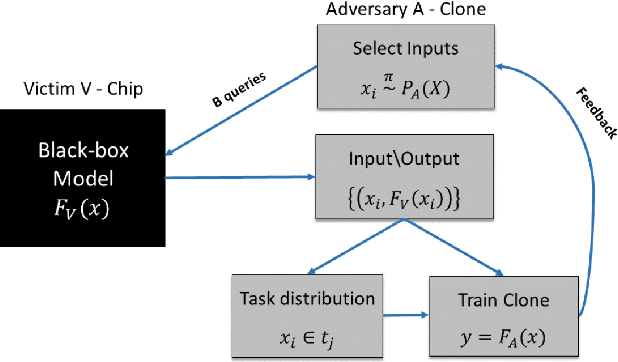
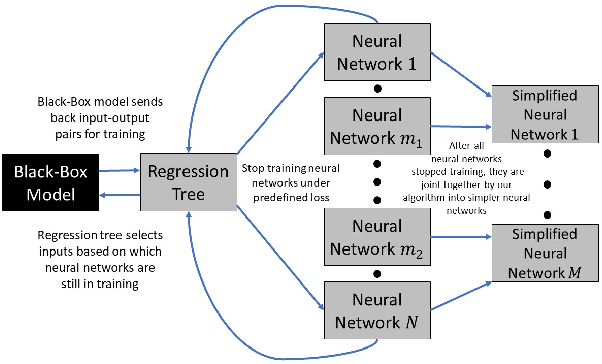
This paper makes a substantial step towards cloning the functionality of black-box models by introducing a Machine learning (ML) architecture named Deep Neural Trees (DNTs). This new architecture can learn to separate different tasks of the black-box model, and clone its task-specific behavior. We propose to train the DNT using an active learning algorithm to obtain faster and more sample-efficient training. In contrast to prior work, we study a complex "victim" black-box model based solely on input-output interactions, while at the same time the attacker and the victim model may have completely different internal architectures. The attacker is a ML based algorithm whereas the victim is a generally unknown module, such as a multi-purpose digital chip, complex analog circuit, mechanical system, software logic or a hybrid of these. The trained DNT module not only can function as the attacked module, but also provides some level of explainability to the cloned model due to the tree-like nature of the proposed architecture.
Patternless Adversarial Attacks on Video Recognition Networks
Feb 12, 2020

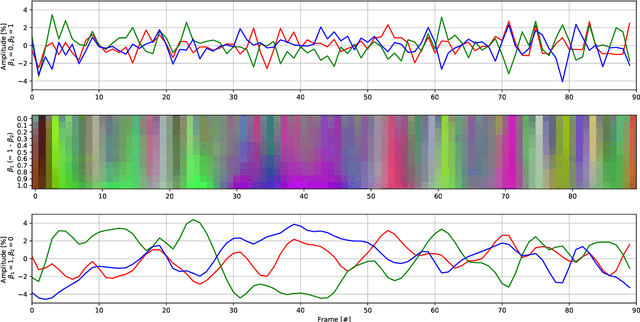
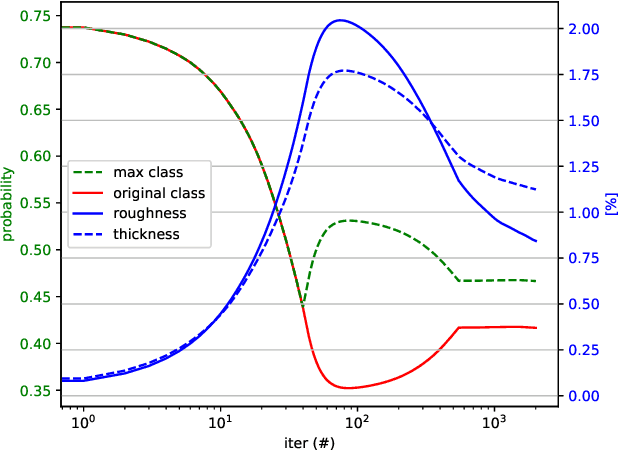
Deep neural networks for classification of videos, just like image classification networks, may be subjected to adversarial manipulation. The main difference between image classifiers and video classifiers is that the latter usually use temporal information contained within the video in the form of optical flow or implicitly by various differences between adjacent frames. In this work we present a manipulation scheme for fooling video classifiers by introducing a spatial patternless temporal perturbation that is practically unnoticed by human observers and undetectable by leading image adversarial pattern detection algorithms. After demonstrating the manipulation of action classification of single videos, we generalize the procedure to make adversarial patterns with temporal invariance that generalizes across different classes for both targeted and untargeted attacks.