 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatternless Adversarial Attacks on Video Recognition Networks
Paper and Code


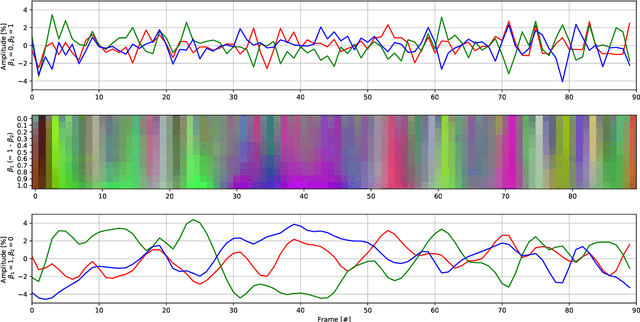
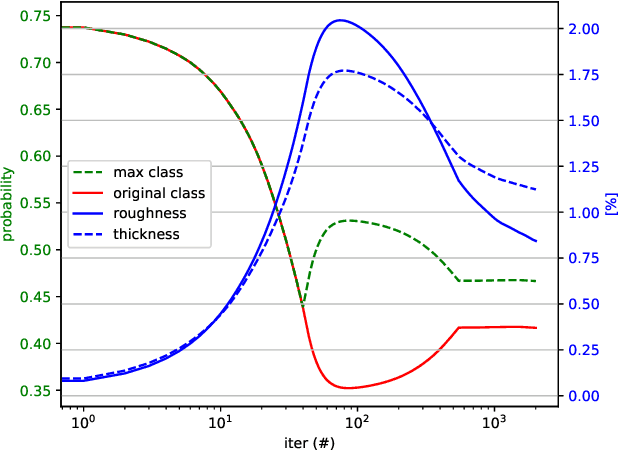
Deep neural networks for classification of videos, just like image classification networks, may be subjected to adversarial manipulation. The main difference between image classifiers and video classifiers is that the latter usually use temporal information contained within the video in the form of optical flow or implicitly by various differences between adjacent frames. In this work we present a manipulation scheme for fooling video classifiers by introducing a spatial patternless temporal perturbation that is practically unnoticed by human observers and undetectable by leading image adversarial pattern detection algorithms. After demonstrating the manipulation of action classification of single videos, we generalize the procedure to make adversarial patterns with temporal invariance that generalizes across different classes for both targeted and untargeted attacks.