 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning in Factored Action Spaces using Tensor Decompositions
Paper and Code
Oct 27, 2021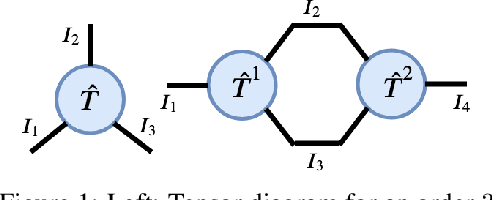
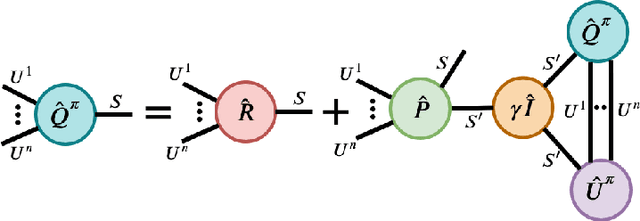
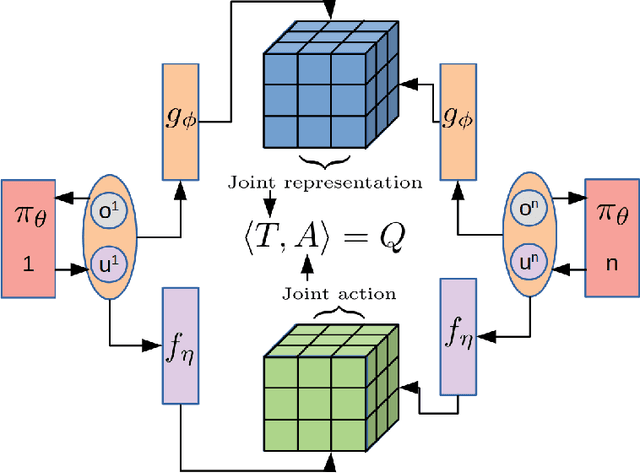
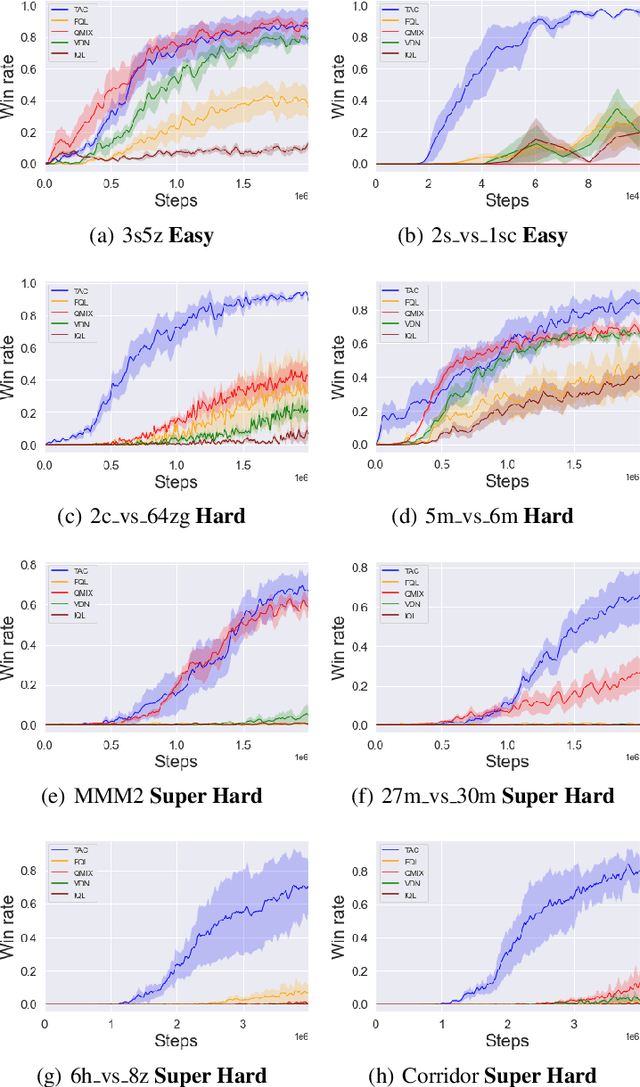
We present an extended abstract for the previously published work TESSERACT [Mahajan et al., 2021], which proposes a novel solution for Reinforcement Learning (RL) in large, factored action spaces using tensor decompositions. The goal of this abstract is twofold: (1) To garner greater interest amongst the tensor research community for creating methods and analysis for approximate RL, (2) To elucidate the generalised setting of factored action spaces where tensor decompositions can be used. We use cooperative multi-agent reinforcement learning scenario as the exemplary setting where the action space is naturally factored across agents and learning becomes intractable without resorting to approximation on the underlying hypothesis space for candidate solutions.