 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-Point Masked Generative Modeling
May 29, 2026Masked Generative Models (MGMs) enable parallel decoding and achieve strong performance across modalities, but require full-sequence bidirectional transformers at every step, making training costly and degrading quality under low sampling budgets. Existing work improves efficiency via better samplers or cheaper fixed-depth denoisers, but they still allocate a fixed amount of denoiser computation to each refinement step. We introduce Fixed-Point Masked Generative Models (FP-MGMs), which replace part of the denoiser with a fixed-point solver over shared attention layers to enable adaptive depth with fewer parameters. To make it more effective for masked generation, we first introduce a cross-step consistency loss, which aligns hidden representations at neighboring denoising steps and, second, three-state reuse (3SR) which warm-starts the solver using the previous solution by treating differently unchanged, still-masked, and newly revealed tokens respectively. Together, these components define our complete training-to-inference framework for fixed-point masked generation, \emph{CoFRe}. We also show that pre-trained MGMs can be converted into FP-MGMs with short fine-tuning, avoiding full retraining. Across modalities, CoFRe improves the quality and cost trade-off. On OpenWebText, CoFRe reduces parameters by 38.8\%, training time by 11.5\%, and VRAM by 16.9\%, while improving generative perplexity from 830.8 to 101.8 at a budget of $96$ transformer-block forward passes, compared to MDLM. In ImageNette, CoFRe reduces training time by 48.6\% and VRAM by 50.7\%, while improving FID in all sample budgets tested. Overall, CoFRe offers a practical framework for cheaper training and stronger low-budget masked generation.
No Representation, No Trust: Connecting Representation, Collapse, and Trust Issues in PPO
May 01, 2024

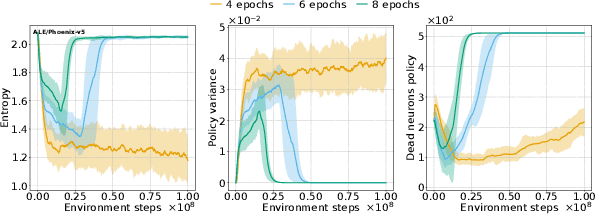

Reinforcement learning (RL) is inherently rife with non-stationarity since the states and rewards the agent observes during training depend on its changing policy. Therefore, networks in deep RL must be capable of adapting to new observations and fitting new targets. However, previous works have observed that networks in off-policy deep value-based methods exhibit a decrease in representation rank, often correlated with an inability to continue learning or a collapse in performance. Although this phenomenon has generally been attributed to neural network learning under non-stationarity, it has been overlooked in on-policy policy optimization methods which are often thought capable of training indefinitely. In this work, we empirically study representation dynamics in Proximal Policy Optimization (PPO) on the Atari and MuJoCo environments, revealing that PPO agents are also affected by feature rank deterioration and loss of plasticity. We show that this is aggravated with stronger non-stationarity, ultimately driving the actor's performance to collapse, regardless of the performance of the critic. We draw connections between representation collapse, performance collapse, and trust region issues in PPO, and present Proximal Feature Optimization (PFO), a novel auxiliary loss, that along with other interventions shows that regularizing the representation dynamics improves the performance of PPO agents.
FourCastNet: Accelerating Global High-Resolution Weather Forecasting using Adaptive Fourier Neural Operators
Aug 08, 2022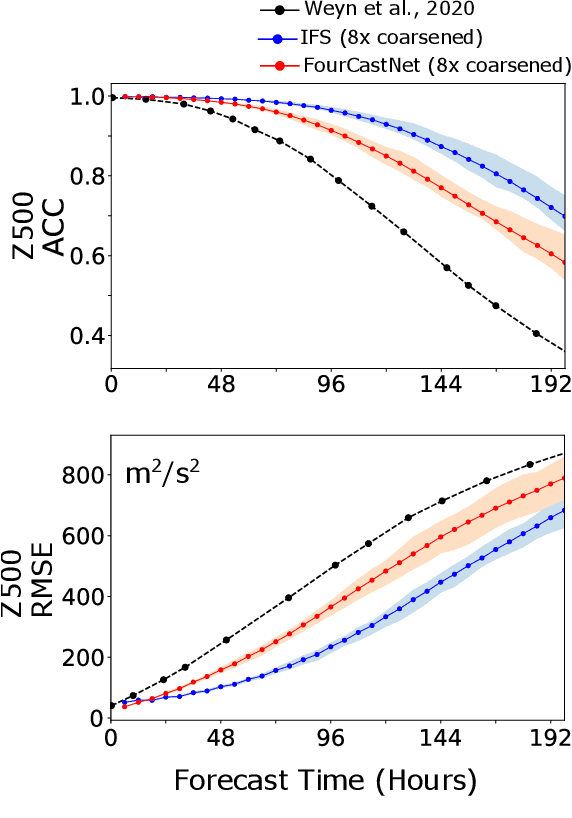
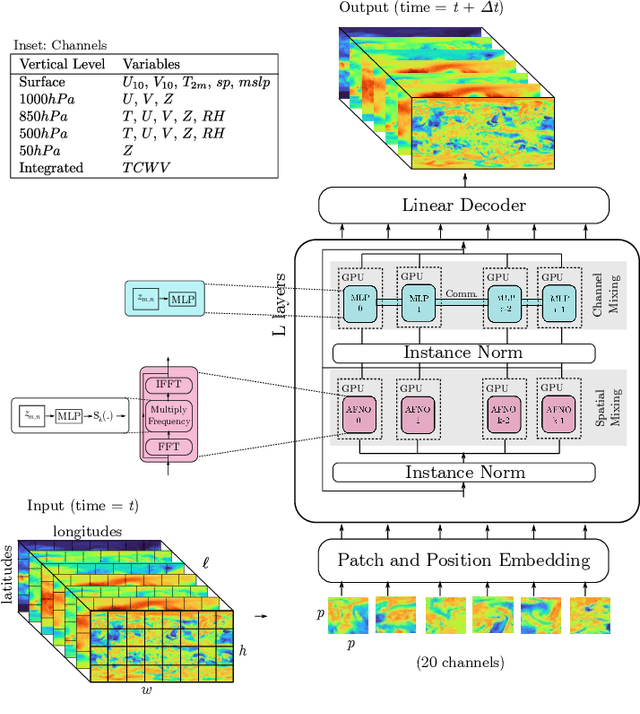
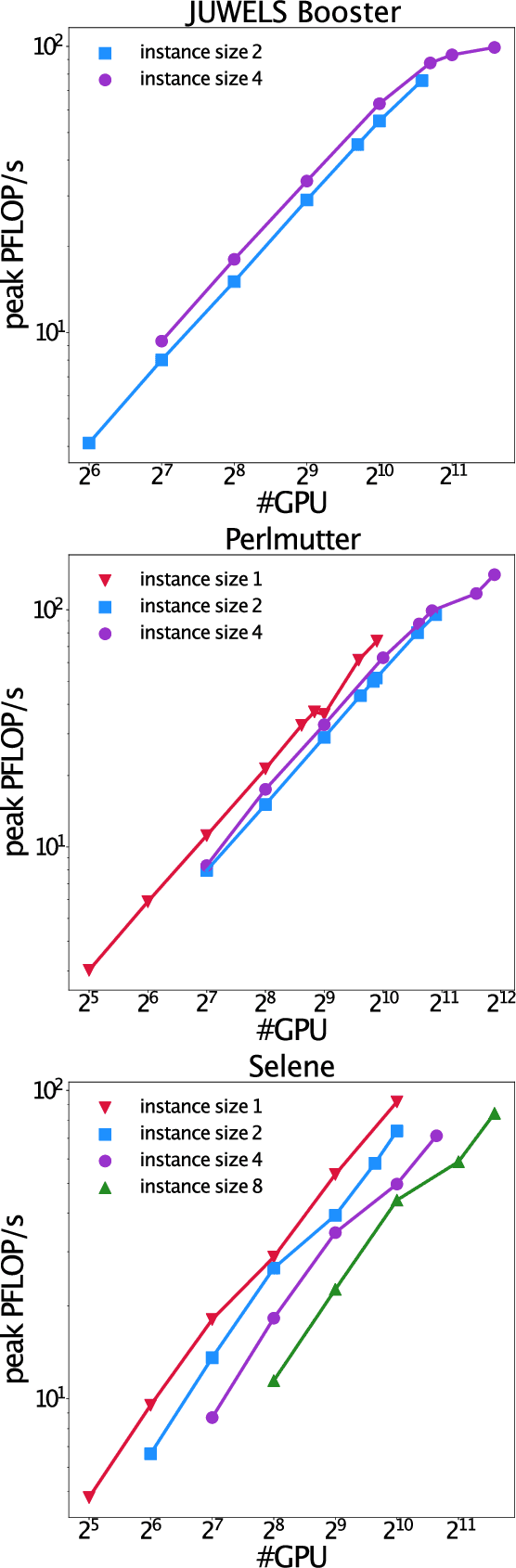
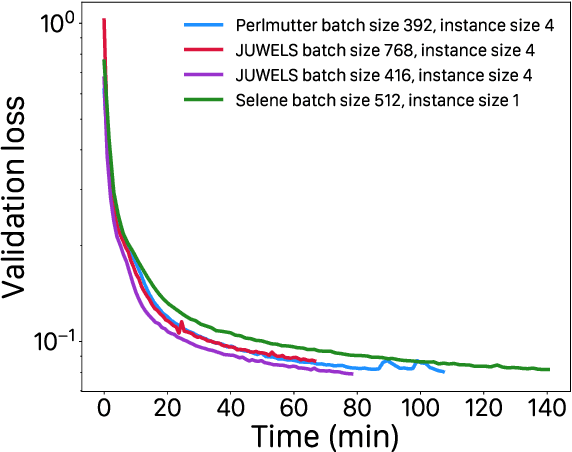
Extreme weather amplified by climate change is causing increasingly devastating impacts across the globe. The current use of physics-based numerical weather prediction (NWP) limits accuracy due to high computational cost and strict time-to-solution limits. We report that a data-driven deep learning Earth system emulator, FourCastNet, can predict global weather and generate medium-range forecasts five orders-of-magnitude faster than NWP while approaching state-of-the-art accuracy. FourCast-Net is optimized and scales efficiently on three supercomputing systems: Selene, Perlmutter, and JUWELS Booster up to 3,808 NVIDIA A100 GPUs, attaining 140.8 petaFLOPS in mixed precision (11.9%of peak at that scale). The time-to-solution for training FourCastNet measured on JUWELS Booster on 3,072GPUs is 67.4minutes, resulting in an 80,000times faster time-to-solution relative to state-of-the-art NWP, in inference. FourCastNet produces accurate instantaneous weather predictions for a week in advance, enables enormous ensembles that better capture weather extremes, and supports higher global forecast resolutions.