 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Improving Long-Range Navigation with Spatially-Enhanced Recurrent Memory via End-to-End Reinforcement Learning
Jun 06, 2025



Recent advancements in robot navigation, especially with end-to-end learning approaches like reinforcement learning (RL), have shown remarkable efficiency and effectiveness. Yet, successful navigation still relies on two key capabilities: mapping and planning, whether explicit or implicit. Classical approaches use explicit mapping pipelines to register ego-centric observations into a coherent map frame for the planner. In contrast, end-to-end learning achieves this implicitly, often through recurrent neural networks (RNNs) that fuse current and past observations into a latent space for planning. While architectures such as LSTM and GRU capture temporal dependencies, our findings reveal a key limitation: their inability to perform effective spatial memorization. This skill is essential for transforming and integrating sequential observations from varying perspectives to build spatial representations that support downstream planning. To address this, we propose Spatially-Enhanced Recurrent Units (SRUs), a simple yet effective modification to existing RNNs, designed to enhance spatial memorization capabilities. We introduce an attention-based architecture with SRUs, enabling long-range navigation using a single forward-facing stereo camera. Regularization techniques are employed to ensure robust end-to-end recurrent training via RL. Experimental results show our approach improves long-range navigation by 23.5% compared to existing RNNs. Furthermore, with SRU memory, our method outperforms the RL baseline with explicit mapping and memory modules, achieving a 29.6% improvement in diverse environments requiring long-horizon mapping and memorization. Finally, we address the sim-to-real gap by leveraging large-scale pretraining on synthetic depth data, enabling zero-shot transfer to diverse and complex real-world environments.
Learning Agile Locomotion on Risky Terrains
Nov 17, 2023



Quadruped robots have shown remarkable mobility on various terrains through reinforcement learning. Yet, in the presence of sparse footholds and risky terrains such as stepping stones and balance beams, which require precise foot placement to avoid falls, model-based approaches are often used. In this paper, we show that end-to-end reinforcement learning can also enable the robot to traverse risky terrains with dynamic motions. To this end, our approach involves training a generalist policy for agile locomotion on disorderly and sparse stepping stones before transferring its reusable knowledge to various more challenging terrains by finetuning specialist policies from it. Given that the robot needs to rapidly adapt its velocity on these terrains, we formulate the task as a navigation task instead of the commonly used velocity tracking which constrains the robot's behavior and propose an exploration strategy to overcome sparse rewards and achieve high robustness. We validate our proposed method through simulation and real-world experiments on an ANYmal-D robot achieving peak forward velocity of >= 2.5 m/s on sparse stepping stones and narrow balance beams. Video: youtu.be/Z5X0J8OH6z4
ANYmal Parkour: Learning Agile Navigation for Quadrupedal Robots
Jun 26, 2023Performing agile navigation with four-legged robots is a challenging task due to the highly dynamic motions, contacts with various parts of the robot, and the limited field of view of the perception sensors. In this paper, we propose a fully-learned approach to train such robots and conquer scenarios that are reminiscent of parkour challenges. The method involves training advanced locomotion skills for several types of obstacles, such as walking, jumping, climbing, and crouching, and then using a high-level policy to select and control those skills across the terrain. Thanks to our hierarchical formulation, the navigation policy is aware of the capabilities of each skill, and it will adapt its behavior depending on the scenario at hand. Additionally, a perception module is trained to reconstruct obstacles from highly occluded and noisy sensory data and endows the pipeline with scene understanding. Compared to previous attempts, our method can plan a path for challenging scenarios without expert demonstration, offline computation, a priori knowledge of the environment, or taking contacts explicitly into account. While these modules are trained from simulated data only, our real-world experiments demonstrate successful transfer on hardware, where the robot navigates and crosses consecutive challenging obstacles with speeds of up to two meters per second. The supplementary video can be found on the project website: https://sites.google.com/leggedrobotics.com/agile-navigation
ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
Jan 10, 2023



We present ORBIT, a unified and modular framework for robot learning powered by NVIDIA Isaac Sim. It offers a modular design to easily and efficiently create robotic environments with photo-realistic scenes and fast and accurate rigid and deformable body simulation. With ORBIT, we provide a suite of benchmark tasks of varying difficulty -- from single-stage cabinet opening and cloth folding to multi-stage tasks such as room reorganization. To support working with diverse observations and action spaces, we include fixed-arm and mobile manipulators with different physically-based sensors and motion generators. ORBIT allows training reinforcement learning policies and collecting large demonstration datasets from hand-crafted or expert solutions in a matter of minutes by leveraging GPU-based parallelization. In summary, we offer an open-sourced framework that readily comes with 16 robotic platforms, 4 sensor modalities, 10 motion generators, more than 20 benchmark tasks, and wrappers to 4 learning libraries. With this framework, we aim to support various research areas, including representation learning, reinforcement learning, imitation learning, and task and motion planning. We hope it helps establish interdisciplinary collaborations in these communities, and its modularity makes it easily extensible for more tasks and applications in the future. For videos, documentation, and code: https://isaac-orbit.github.io/.
Advanced Skills by Learning Locomotion and Local Navigation End-to-End
Sep 26, 2022


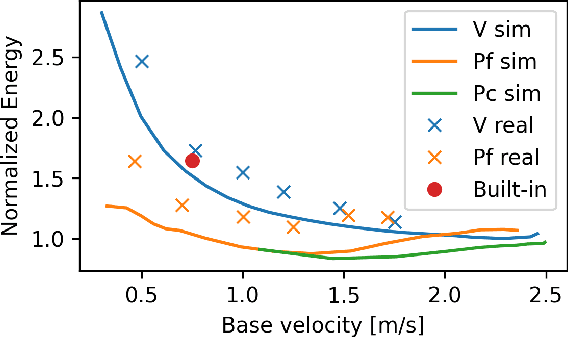
The common approach for local navigation on challenging environments with legged robots requires path planning, path following and locomotion, which usually requires a locomotion control policy that accurately tracks a commanded velocity. However, by breaking down the navigation problem into these sub-tasks, we limit the robot's capabilities since the individual tasks do not consider the full solution space. In this work, we propose to solve the complete problem by training an end-to-end policy with deep reinforcement learning. Instead of continuously tracking a precomputed path, the robot needs to reach a target position within a provided time. The task's success is only evaluated at the end of an episode, meaning that the policy does not need to reach the target as fast as possible. It is free to select its path and the locomotion gait. Training a policy in this way opens up a larger set of possible solutions, which allows the robot to learn more complex behaviors. We compare our approach to velocity tracking and additionally show that the time dependence of the task reward is critical to successfully learn these new behaviors. Finally, we demonstrate the successful deployment of policies on a real quadrupedal robot. The robot is able to cross challenging terrains, which were not possible previously, while using a more energy-efficient gait and achieving a higher success rate.
Neural Scene Representation for Locomotion on Structured Terrain
Jun 16, 2022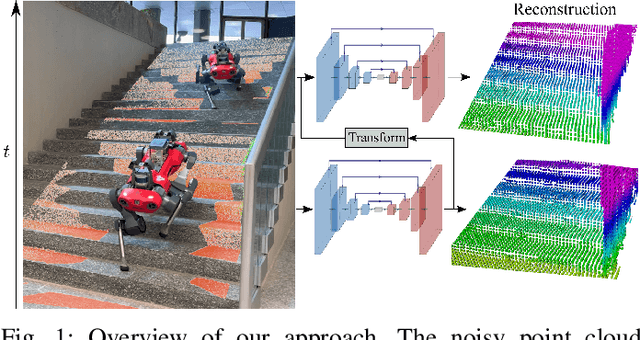
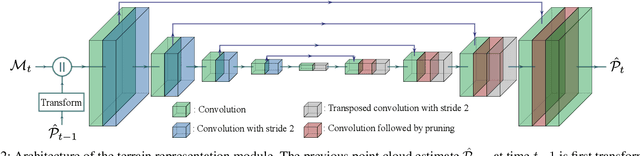

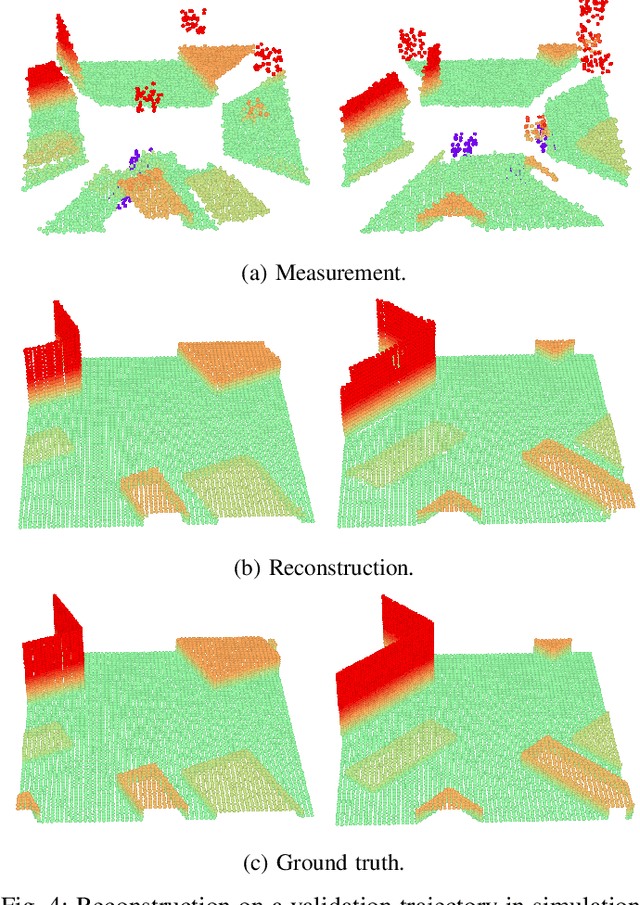
We propose a learning-based method to reconstruct the local terrain for locomotion with a mobile robot traversing urban environments. Using a stream of depth measurements from the onboard cameras and the robot's trajectory, the algorithm estimates the topography in the robot's vicinity. The raw measurements from these cameras are noisy and only provide partial and occluded observations that in many cases do not show the terrain the robot stands on. Therefore, we propose a 3D reconstruction model that faithfully reconstructs the scene, despite the noisy measurements and large amounts of missing data coming from the blind spots of the camera arrangement. The model consists of a 4D fully convolutional network on point clouds that learns the geometric priors to complete the scene from the context and an auto-regressive feedback to leverage spatio-temporal consistency and use evidence from the past. The network can be solely trained with synthetic data, and due to extensive augmentation, it is robust in the real world, as shown in the validation on a quadrupedal robot, ANYmal, traversing challenging settings. We run the pipeline on the robot's onboard low-power computer using an efficient sparse tensor implementation and show that the proposed method outperforms classical map representations.
Locomotion Policy Guided Traversability Learning using Volumetric Representations of Complex Environments
Mar 29, 2022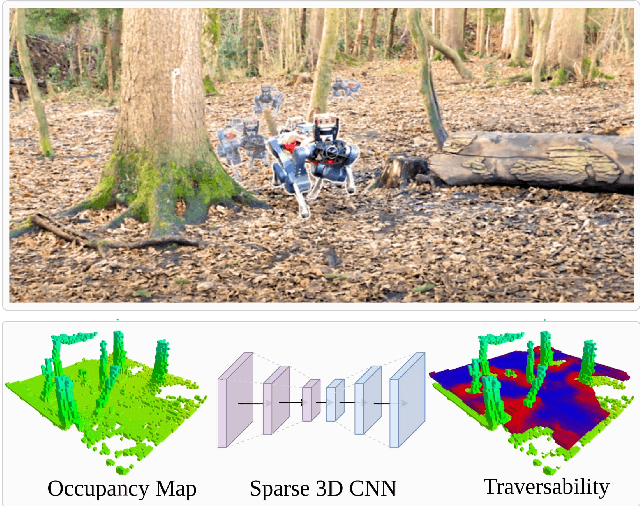


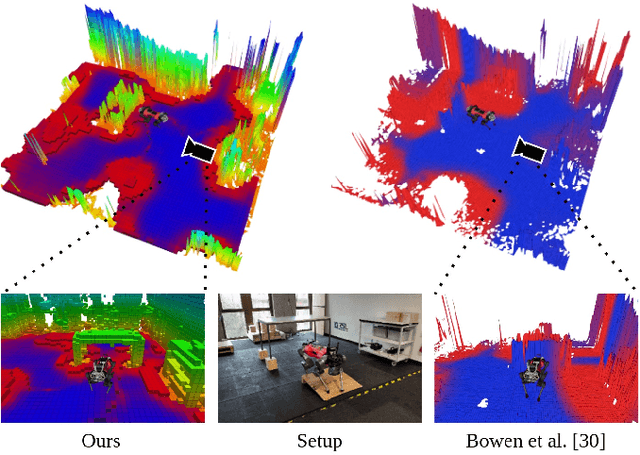
Despite the progress in legged robotic locomotion, autonomous navigation in unknown environments remains an open problem. Ideally, the navigation system utilizes the full potential of the robots' locomotion capabilities while operating within safety limits under uncertainty. The robot must sense and analyze the traversability of the surrounding terrain, which depends on the hardware, locomotion control, and terrain properties. It may contain information about the risk, energy, or time consumption needed to traverse the terrain. To avoid hand-crafted traversability cost functions we propose to collect traversability information about the robot and locomotion policy by simulating the traversal over randomly generated terrains using a physics simulator. Thousand of robots are simulated in parallel controlled by the same locomotion policy used in reality to acquire 57 years of real-world locomotion experience equivalent. For deployment on the real robot, a sparse convolutional network is trained to predict the simulated traversability cost, which is tailored to the deployed locomotion policy, from an entirely geometric representation of the environment in the form of a 3D voxel-occupancy map. This representation avoids the need for commonly used elevation maps, which are error-prone in the presence of overhanging obstacles and multi-floor or low-ceiling scenarios. The effectiveness of the proposed traversability prediction network is demonstrated for path planning for the legged robot ANYmal in various indoor and natural environments.
Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
Sep 24, 2021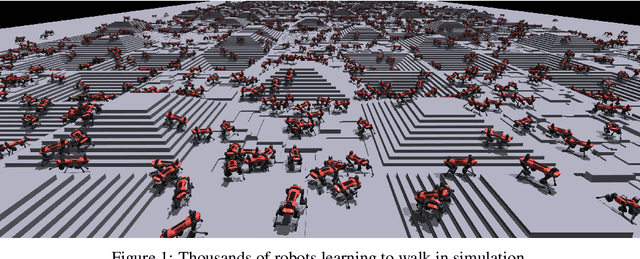



In this work, we present and study a training set-up that achieves fast policy generation for real-world robotic tasks by using massive parallelism on a single workstation GPU. We analyze and discuss the impact of different training algorithm components in the massively parallel regime on the final policy performance and training times. In addition, we present a novel game-inspired curriculum that is well suited for training with thousands of simulated robots in parallel. We evaluate the approach by training the quadrupedal robot ANYmal to walk on challenging terrain. The parallel approach allows training policies for flat terrain in under four minutes, and in twenty minutes for uneven terrain. This represents a speedup of multiple orders of magnitude compared to previous work. Finally, we transfer the policies to the real robot to validate the approach. We open-source our training code to help accelerate further research in the field of learned legged locomotion.
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Aug 25, 2021

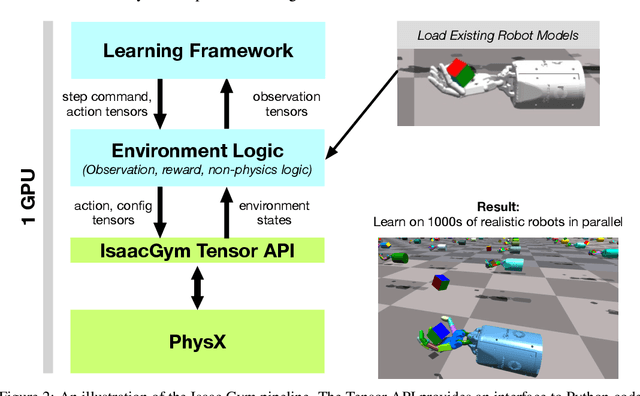

Isaac Gym offers a high performance learning platform to train policies for wide variety of robotics tasks directly on GPU. Both physics simulation and the neural network policy training reside on GPU and communicate by directly passing data from physics buffers to PyTorch tensors without ever going through any CPU bottlenecks. This leads to blazing fast training times for complex robotics tasks on a single GPU with 2-3 orders of magnitude improvements compared to conventional RL training that uses a CPU based simulator and GPU for neural networks. We host the results and videos at \url{https://sites.google.com/view/isaacgym-nvidia} and isaac gym can be downloaded at \url{https://developer.nvidia.com/isaac-gym}.