 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
Paper and Code
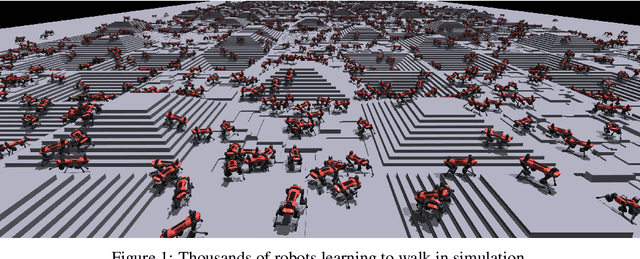



In this work, we present and study a training set-up that achieves fast policy generation for real-world robotic tasks by using massive parallelism on a single workstation GPU. We analyze and discuss the impact of different training algorithm components in the massively parallel regime on the final policy performance and training times. In addition, we present a novel game-inspired curriculum that is well suited for training with thousands of simulated robots in parallel. We evaluate the approach by training the quadrupedal robot ANYmal to walk on challenging terrain. The parallel approach allows training policies for flat terrain in under four minutes, and in twenty minutes for uneven terrain. This represents a speedup of multiple orders of magnitude compared to previous work. Finally, we transfer the policies to the real robot to validate the approach. We open-source our training code to help accelerate further research in the field of learned legged locomotion.