 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the design space of deep-learning-based weather forecasting systems
Paper and Code
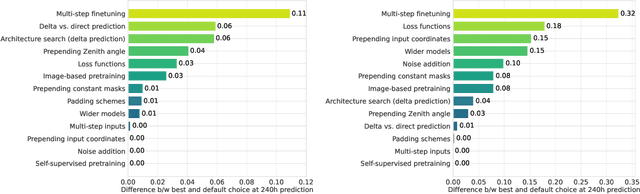

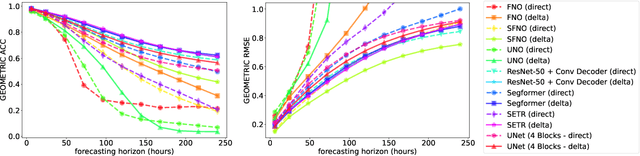
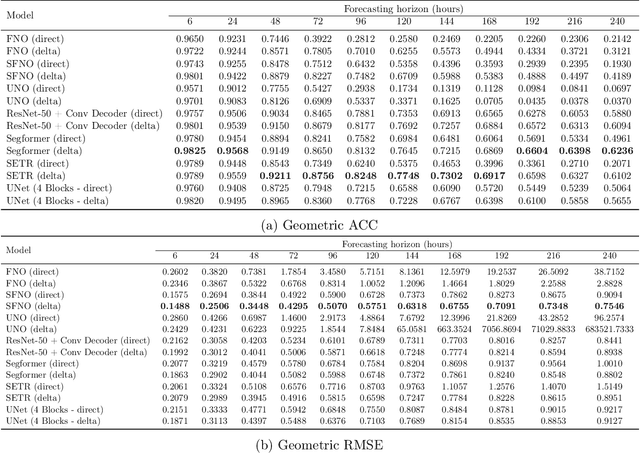
Despite tremendous progress in developing deep-learning-based weather forecasting systems, their design space, including the impact of different design choices, is yet to be well understood. This paper aims to fill this knowledge gap by systematically analyzing these choices including architecture, problem formulation, pretraining scheme, use of image-based pretrained models, loss functions, noise injection, multi-step inputs, additional static masks, multi-step finetuning (including larger stride models), as well as training on a larger dataset. We study fixed-grid architectures such as UNet, fully convolutional architectures, and transformer-based models, along with grid-invariant architectures, including graph-based and operator-based models. Our results show that fixed-grid architectures outperform grid-invariant architectures, indicating a need for further architectural developments in grid-invariant models such as neural operators. We therefore propose a hybrid system that combines the strong performance of fixed-grid models with the flexibility of grid-invariant architectures. We further show that multi-step fine-tuning is essential for most deep-learning models to work well in practice, which has been a common practice in the past. Pretraining objectives degrade performance in comparison to supervised training, while image-based pretrained models provide useful inductive biases in some cases in comparison to training the model from scratch. Interestingly, we see a strong positive effect of using a larger dataset when training a smaller model as compared to training on a smaller dataset for longer. Larger models, on the other hand, primarily benefit from just an increase in the computational budget. We believe that these results will aid in the design of better weather forecasting systems in the future.