 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Multi-Object Render-and-Compare
Paper and Code
Oct 17, 2023
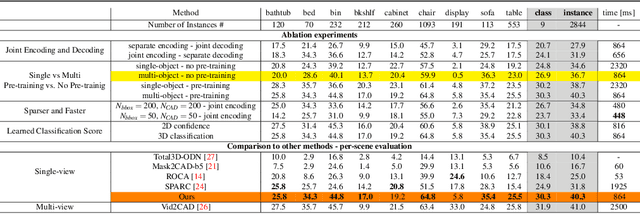
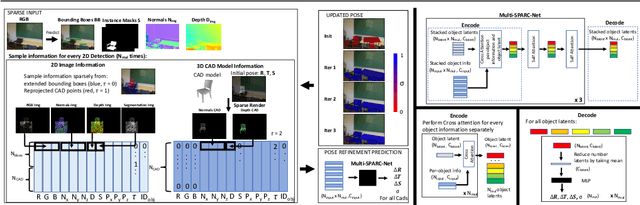

Reconstructing 3D shape and pose of static objects from a single image is an essential task for various industries, including robotics, augmented reality, and digital content creation. This can be done by directly predicting 3D shape in various representations or by retrieving CAD models from a database and predicting their alignments. Directly predicting 3D shapes often produces unrealistic, overly smoothed or tessellated shapes. Retrieving CAD models ensures realistic shapes but requires robust and accurate alignment. Learning to directly predict CAD model poses from image features is challenging and inaccurate. Works, such as ROCA, compute poses from predicted normalised object coordinates which can be more accurate but are susceptible to systematic failure. SPARC demonstrates that following a ''render-and-compare'' approach where a network iteratively improves upon its own predictions achieves accurate alignments. Nevertheless, it performs individual CAD alignment for every object detected in an image. This approach is slow when applied to many objects as the time complexity increases linearly with the number of objects and can not learn inter-object relations. Introducing a new network architecture Multi-SPARC we learn to perform CAD model alignments for multiple detected objects jointly. Compared to other single-view methods we achieve state-of-the-art performance on the challenging real-world dataset ScanNet. By improving the instance alignment accuracy from 31.8% to 40.3% we perform similar to state-of-the-art multi-view methods.