 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFVS: Deep Flow Guided Scene Agnostic Image Based Visual Servoing
Mar 08, 2020

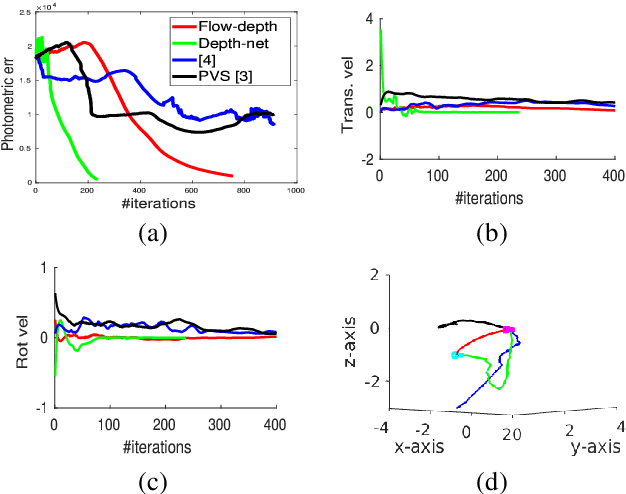
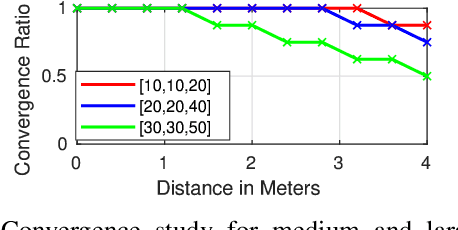
Existing deep learning based visual servoing approaches regress the relative camera pose between a pair of images. Therefore, they require a huge amount of training data and sometimes fine-tuning for adaptation to a novel scene. Furthermore, current approaches do not consider underlying geometry of the scene and rely on direct estimation of camera pose. Thus, inaccuracies in prediction of the camera pose, especially for distant goals, lead to a degradation in the servoing performance. In this paper, we propose a two-fold solution: (i) We consider optical flow as our visual features, which are predicted using a deep neural network. (ii) These flow features are then systematically integrated with depth estimates provided by another neural network using interaction matrix. We further present an extensive benchmark in a photo-realistic 3D simulation across diverse scenes to study the convergence and generalisation of visual servoing approaches. We show convergence for over 3m and 40 degrees while maintaining precise positioning of under 2cm and 1 degree on our challenging benchmark where the existing approaches that are unable to converge for majority of scenarios for over 1.5m and 20 degrees. Furthermore, we also evaluate our approach for a real scenario on an aerial robot. Our approach generalizes to novel scenarios producing precise and robust servoing performance for 6 degrees of freedom positioning tasks with even large camera transformations without any retraining or fine-tuning.
Object Parsing in Sequences Using CoordConv Gated Recurrent Networks
Oct 02, 2019


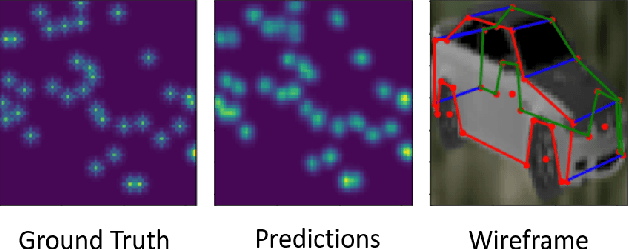
We present a monocular object parsing framework for consistent keypoint localization by capturing temporal correlation on sequential data. In this paper, we propose a novel recurrent network based architecture to model long-range dependencies between intermediate features which are highly useful in tasks like keypoint localization and tracking. We leverage the expressiveness of the popular stacked hourglass architecture and augment it by adopting memory units between intermediate layers of the network with weights shared across stages for video frames. We observe that this weight sharing scheme not only enables us to frame hourglass architecture as a recurrent network but also prove to be highly effective in producing increasingly refined estimates for sequential tasks. Furthermore, we propose a new memory cell, we call CoordConvGRU which learns to selectively preserve spatio-temporal correlation and showcase our results on the keypoint localization task. The experiments show that our approach is able to model the motion dynamics between the frames and significantly outperforms the baseline hourglass network. Even though our network is trained on a synthetically rendered dataset, we observe that with minimal fine tuning on 300 real images we are able to achieve performance at par with various state-of-the-art methods trained with the same level of supervisory inputs. By using a simpler architecture than other methods enables us to run it in real time on a standard GPU which is desirable for such applications. Finally, we make our architectures and 524 annotated sequences of cars from KITTI dataset publicly available.
Exploring Convolutional Networks for End-to-End Visual Servoing
Jun 10, 2017



Present image based visual servoing approaches rely on extracting hand crafted visual features from an image. Choosing the right set of features is important as it directly affects the performance of any approach. Motivated by recent breakthroughs in performance of data driven methods on recognition and localization tasks, we aim to learn visual feature representations suitable for servoing tasks in unstructured and unknown environments. In this paper, we present an end-to-end learning based approach for visual servoing in diverse scenes where the knowledge of camera parameters and scene geometry is not available a priori. This is achieved by training a convolutional neural network over color images with synchronised camera poses. Through experiments performed in simulation and on a quadrotor, we demonstrate the efficacy and robustness of our approach for a wide range of camera poses in both indoor as well as outdoor environments.