 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Budbreak Prediction
Jan 04, 2023Grapevine budbreak is a key phenological stage of seasonal development, which serves as a signal for the onset of active growth. This is also when grape plants are most vulnerable to damage from freezing temperatures. Hence, it is important for winegrowers to anticipate the day of budbreak occurrence to protect their vineyards from late spring frost events. This work investigates deep learning for budbreak prediction using data collected for multiple grape cultivars. While some cultivars have over 30 seasons of data others have as little as 4 seasons, which can adversely impact prediction accuracy. To address this issue, we investigate multi-task learning, which combines data across all cultivars to make predictions for individual cultivars. Our main result shows that several variants of multi-task learning are all able to significantly improve prediction accuracy compared to learning for each cultivar independently.
Grape Cold Hardiness Prediction via Multi-Task Learning
Sep 23, 2022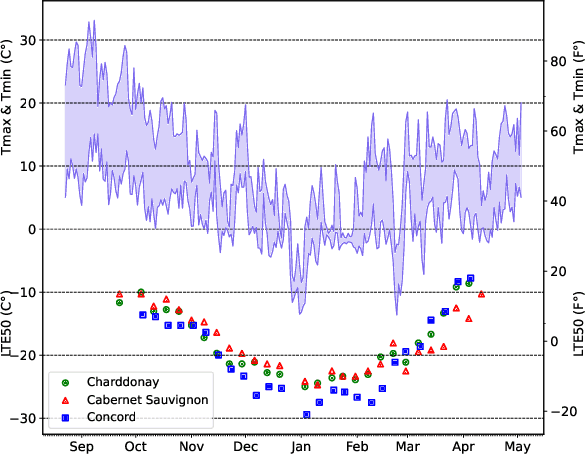
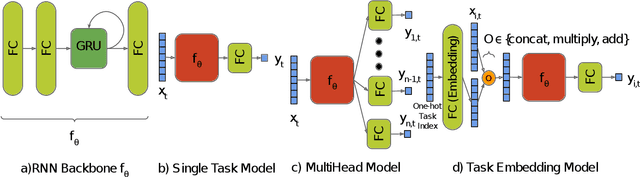
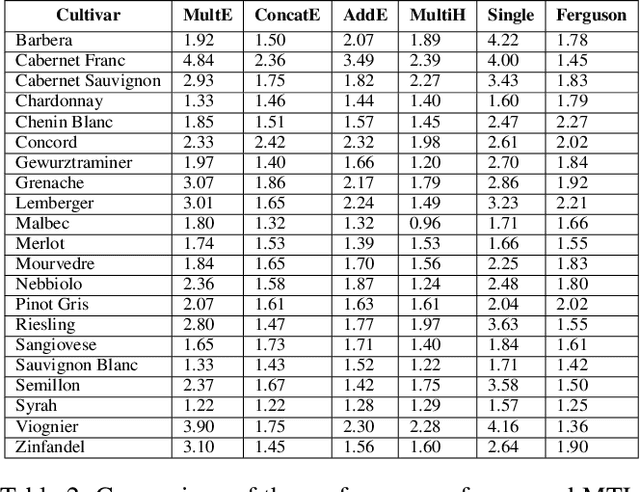
Cold temperatures during fall and spring have the potential to cause frost damage to grapevines and other fruit plants, which can significantly decrease harvest yields. To help prevent these losses, farmers deploy expensive frost mitigation measures, such as, sprinklers, heaters, and wind machines, when they judge that damage may occur. This judgment, however, is challenging because the cold hardiness of plants changes throughout the dormancy period and it is difficult to directly measure. This has led scientists to develop cold hardiness prediction models that can be tuned to different grape cultivars based on laborious field measurement data. In this paper, we study whether deep-learning models can improve cold hardiness prediction for grapes based on data that has been collected over a 30-year time period. A key challenge is that the amount of data per cultivar is highly variable, with some cultivars having only a small amount. For this purpose, we investigate the use of multi-task learning to leverage data across cultivars in order to improve prediction performance for individual cultivars. We evaluate a number of multi-task learning approaches and show that the highest performing approach is able to significantly improve over learning for single cultivars and outperforms the current state-of-the-art scientific model for most cultivars.
Formalizing the Problem of Side Effect Regularization
Jun 24, 2022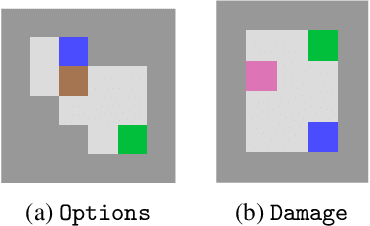
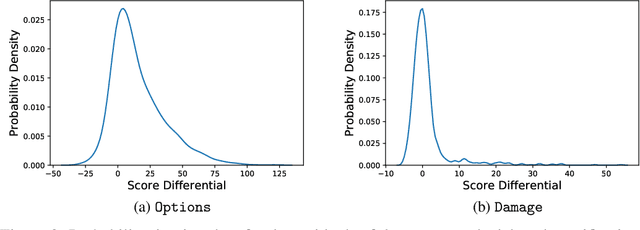
AI objectives are often hard to specify properly. Some approaches tackle this problem by regularizing the AI's side effects: Agents must weigh off "how much of a mess they make" with an imperfectly specified proxy objective. We propose a formal criterion for side effect regularization via the assistance game framework. In these games, the agent solves a partially observable Markov decision process (POMDP) representing its uncertainty about the objective function it should optimize. We consider the setting where the true objective is revealed to the agent at a later time step. We show that this POMDP is solved by trading off the proxy reward with the agent's ability to achieve a range of future tasks. We empirically demonstrate the reasonableness of our problem formalization via ground-truth evaluation in two gridworld environments.
Sim-to-Real Learning of Footstep-Constrained Bipedal Dynamic Walking
Mar 15, 2022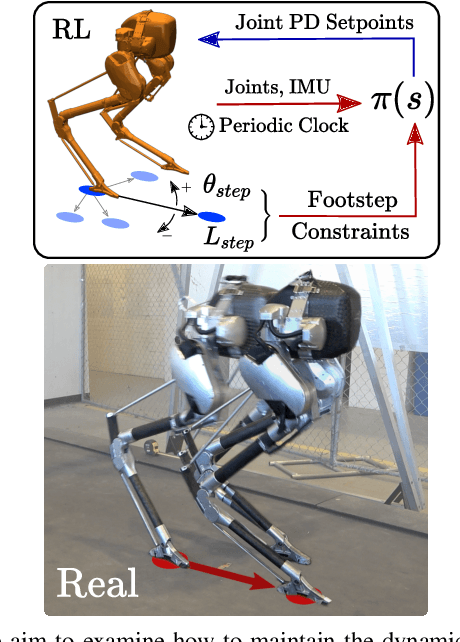
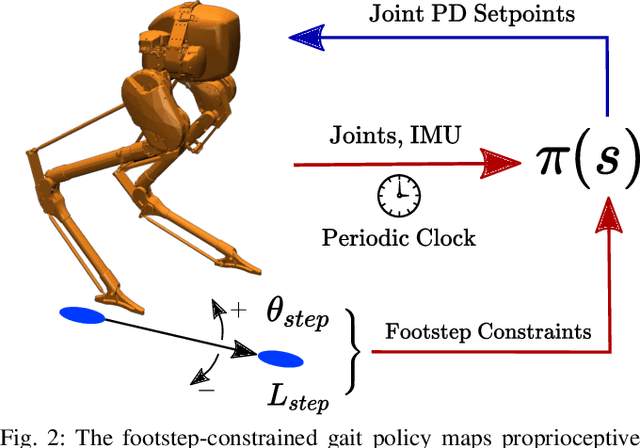
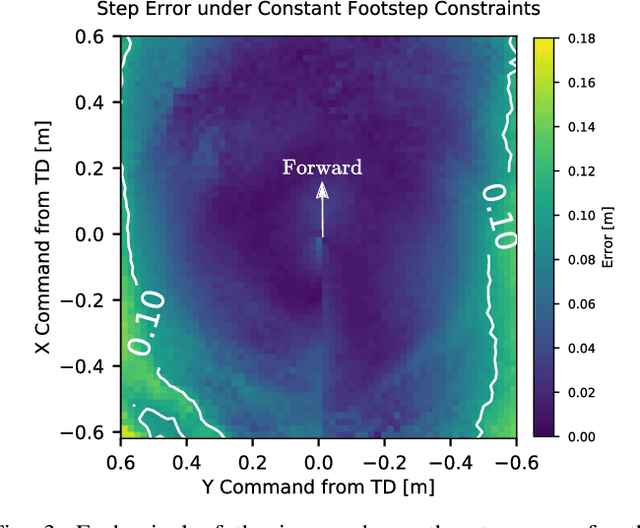
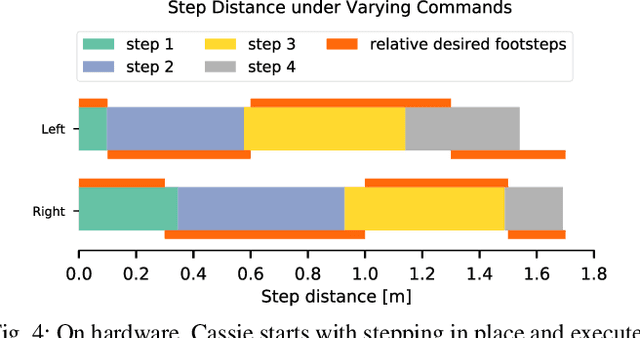
Recently, work on reinforcement learning (RL) for bipedal robots has successfully learned controllers for a variety of dynamic gaits with robust sim-to-real demonstrations. In order to maintain balance, the learned controllers have full freedom of where to place the feet, resulting in highly robust gaits. In the real world however, the environment will often impose constraints on the feasible footstep locations, typically identified by perception systems. Unfortunately, most demonstrated RL controllers on bipedal robots do not allow for specifying and responding to such constraints. This missing control interface greatly limits the real-world application of current RL controllers. In this paper, we aim to maintain the robust and dynamic nature of learned gaits while also respecting footstep constraints imposed externally. We develop an RL formulation for training dynamic gait controllers that can respond to specified touchdown locations. We then successfully demonstrate simulation and sim-to-real performance on the bipedal robot Cassie. In addition, we use supervised learning to induce a transition model for accurately predicting the next touchdown locations that the controller can achieve given the robot's proprioceptive observations. This model paves the way for integrating the learned controller into a full-order robot locomotion planner that robustly satisfies both balance and environmental constraints.
LeTS-Drive: Driving in a Crowd by Learning from Tree Search
May 29, 2019



Autonomous driving in a crowded environment, e.g., a busy traffic intersection, is an unsolved challenge for robotics. The robot vehicle must contend with a dynamic and partially observable environment, noisy sensors, and many agents. A principled approach is to formalize it as a Partially Observable Markov Decision Process (POMDP) and solve it through online belief-tree search. To handle a large crowd and achieve real-time performance in this very challenging setting, we propose LeTS-Drive, which integrates online POMDP planning and deep learning. It consists of two phases. In the offline phase, we learn a policy and the corresponding value function by imitating the belief tree search. In the online phase, the learned policy and value function guide the belief tree search. LeTS-Drive leverages the robustness of planning and the runtime efficiency of learning to enhance the performance of both. Experimental results in simulation show that LeTS-Drive outperforms either planning or imitation learning alone and develops sophisticated driving skills.
Exploring Convolutional Networks for End-to-End Visual Servoing
Jun 10, 2017



Present image based visual servoing approaches rely on extracting hand crafted visual features from an image. Choosing the right set of features is important as it directly affects the performance of any approach. Motivated by recent breakthroughs in performance of data driven methods on recognition and localization tasks, we aim to learn visual feature representations suitable for servoing tasks in unstructured and unknown environments. In this paper, we present an end-to-end learning based approach for visual servoing in diverse scenes where the knowledge of camera parameters and scene geometry is not available a priori. This is achieved by training a convolutional neural network over color images with synchronised camera poses. Through experiments performed in simulation and on a quadrotor, we demonstrate the efficacy and robustness of our approach for a wide range of camera poses in both indoor as well as outdoor environments.