 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Bipedal Maneuvers through Sim-to-Real Reinforcement Learning
Jul 16, 2022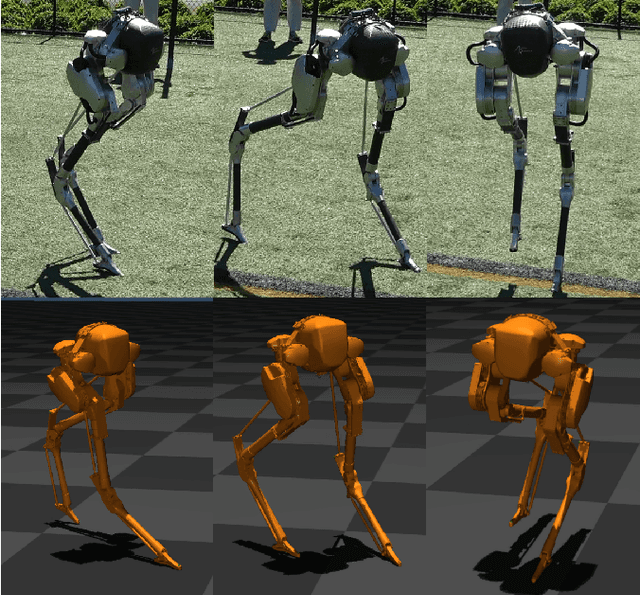
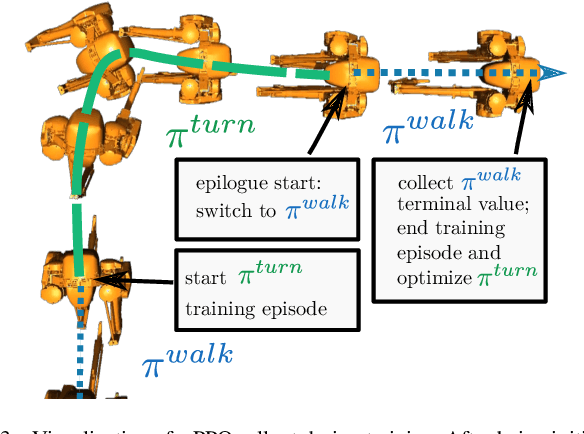
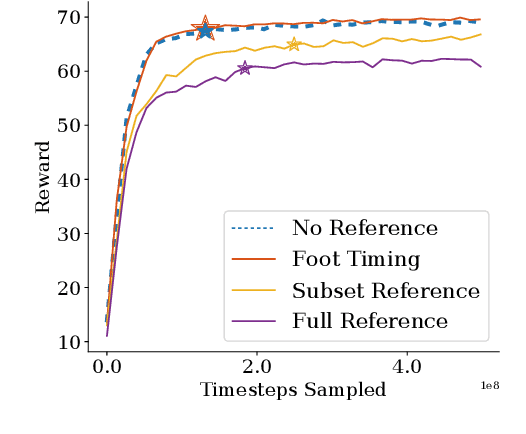
For legged robots to match the athletic capabilities of humans and animals, they must not only produce robust periodic walking and running, but also seamlessly switch between nominal locomotion gaits and more specialized transient maneuvers. Despite recent advancements in controls of bipedal robots, there has been little focus on producing highly dynamic behaviors. Recent work utilizing reinforcement learning to produce policies for control of legged robots have demonstrated success in producing robust walking behaviors. However, these learned policies have difficulty expressing a multitude of different behaviors on a single network. Inspired by conventional optimization-based control techniques for legged robots, this work applies a recurrent policy to execute four-step, 90 degree turns trained using reference data generated from optimized single rigid body model trajectories. We present a novel training framework using epilogue terminal rewards for learning specific behaviors from pre-computed trajectory data and demonstrate a successful transfer to hardware on the bipedal robot Cassie.
Optimizing Bipedal Maneuvers of Single Rigid-Body Models for Reinforcement Learning
Jul 09, 2022

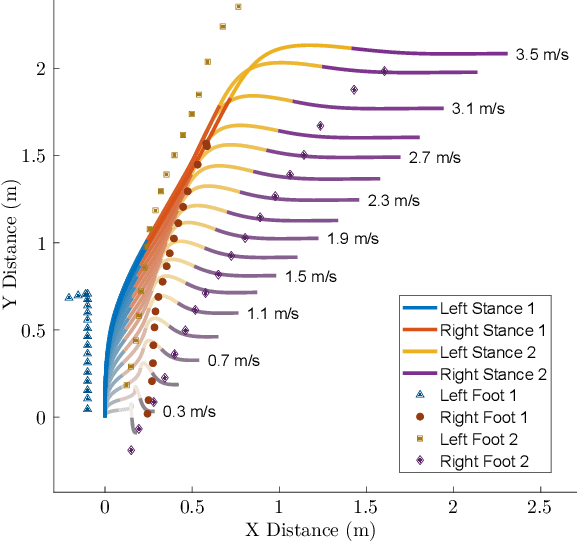
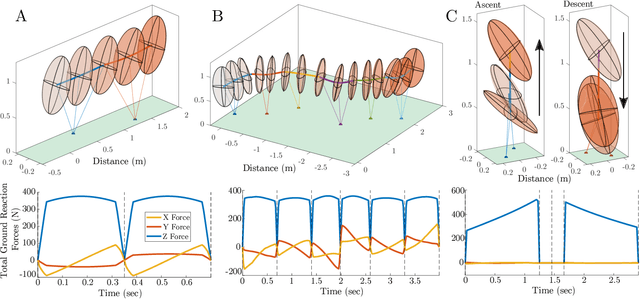
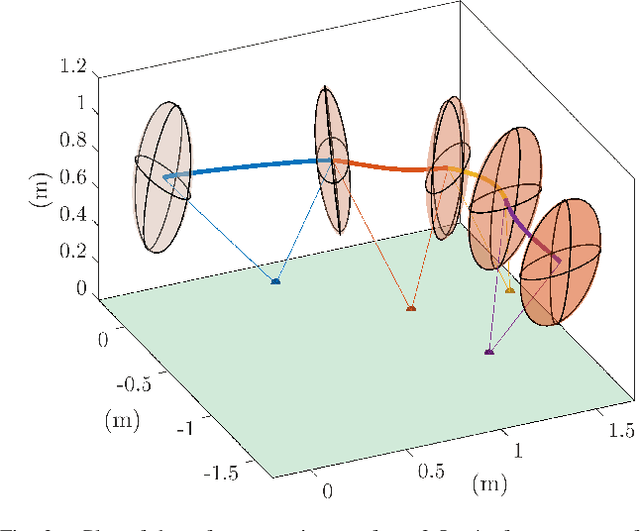
In this work, we propose a method to generate reduced-order model reference trajectories for general classes of highly dynamic maneuvers for bipedal robots for use in sim-to-real reinforcement learning. Our approach is to utilize a single rigid-body model (SRBM) to optimize libraries of trajectories offline to be used as expert references in the reward function of a learned policy. This method translates the model's dynamically rich rotational and translational behaviour to a full-order robot model and successfully transfers to real hardware. The SRBM's simplicity allows for fast iteration and refinement of behaviors, while the robustness of learning-based controllers allows for highly dynamic motions to be transferred to hardware. % Within this work we introduce a set of transferability constraints that amend the SRBM dynamics to actual bipedal robot hardware, our framework for creating optimal trajectories for dynamic stepping, turning maneuvers and jumps as well as our approach to integrating reference trajectories to a reinforcement learning policy. Within this work we introduce a set of transferability constraints that amend the SRBM dynamics to actual bipedal robot hardware, our framework for creating optimal trajectories for a variety of highly dynamic maneuvers as well as our approach to integrating reference trajectories for a high-speed running reinforcement learning policy. We validate our methods on the bipedal robot Cassie on which we were successfully able to demonstrate highly dynamic grounded running gaits up to 3.0 m/s.
Sim-to-Real Learning for Bipedal Locomotion Under Unsensed Dynamic Loads
Apr 09, 2022



Recent work on sim-to-real learning for bipedal locomotion has demonstrated new levels of robustness and agility over a variety of terrains. However, that work, and most prior bipedal locomotion work, have not considered locomotion under a variety of external loads that can significantly influence the overall system dynamics. In many applications, robots will need to maintain robust locomotion under a wide range of potential dynamic loads, such as pulling a cart or carrying a large container of sloshing liquid, ideally without requiring additional load-sensing capabilities. In this work, we explore the capabilities of reinforcement learning (RL) and sim-to-real transfer for bipedal locomotion under dynamic loads using only proprioceptive feedback. We show that prior RL policies trained for unloaded locomotion fail for some loads and that simply training in the context of loads is enough to result in successful and improved policies. We also compare training specialized policies for each load versus a single policy for all considered loads and analyze how the resulting gaits change to accommodate different loads. Finally, we demonstrate sim-to-real transfer, which is successful but shows a wider sim-to-real gap than prior unloaded work, which points to interesting future research.
Motion Planning for Agile Legged Locomotion using Failure Margin Constraints
Mar 28, 2022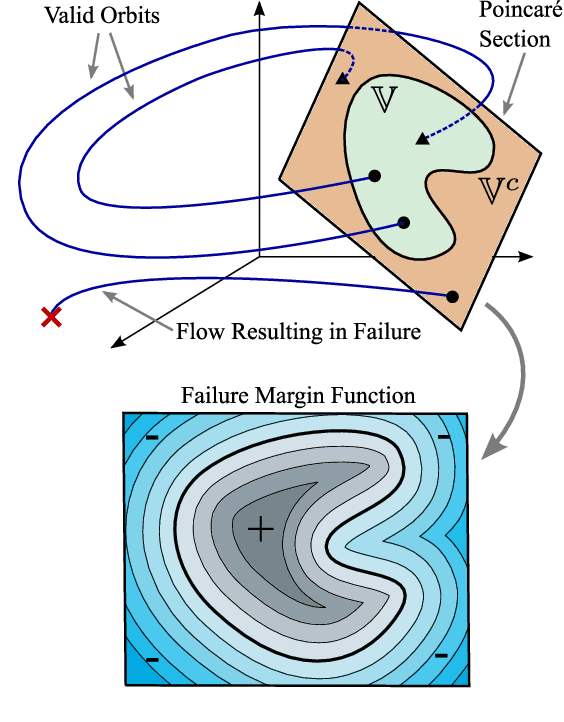
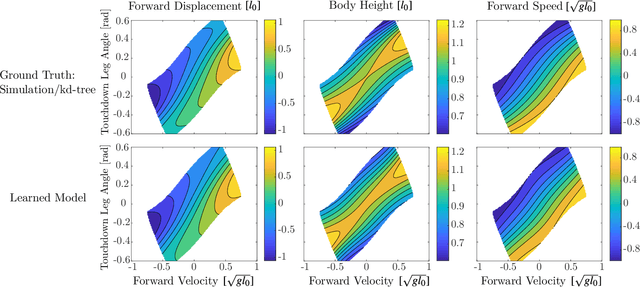
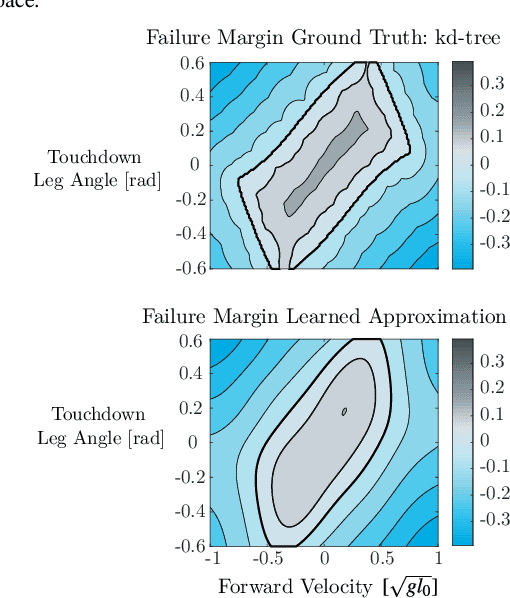
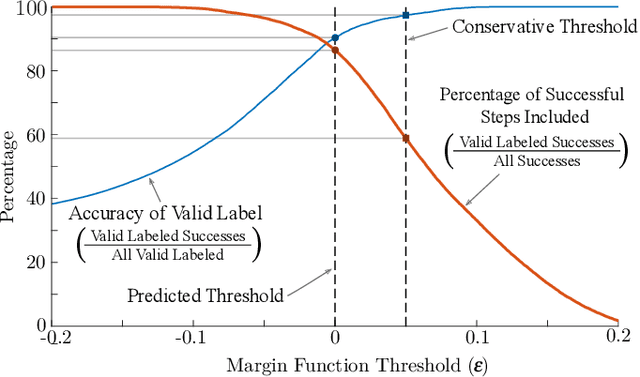
The complex dynamics of agile robotic legged locomotion requires motion planning to intelligently adjust footstep locations. Often, bipedal footstep and motion planning use mathematically simple models such as the linear inverted pendulum, instead of dynamically-rich models that do not have closed-form solutions. We propose a real-time optimization method to plan for dynamical models that do not have closed form solutions and experience irrecoverable failure. Our method uses a data-driven approximation of the step-to-step dynamics and of a failure margin function. This failure margin function is an oriented distance function in state-action space where it describes the signed distance to success or failure. The motion planning problem is formed as a nonlinear program with constraints that enforce the approximated forward dynamics and the validity of state-action pairs. For illustration, this method is applied to create a planner for an actuated spring-loaded inverted pendulum model. In an ablation study, the failure margin constraints decreased the number of invalid solutions by between 24 and 47 percentage points across different objectives and horizon lengths. While we demonstrate the method on a canonical model of locomotion, we also discuss how this can be applied to data-driven models and full-order robot models.
Sim-to-Real Learning of Footstep-Constrained Bipedal Dynamic Walking
Mar 15, 2022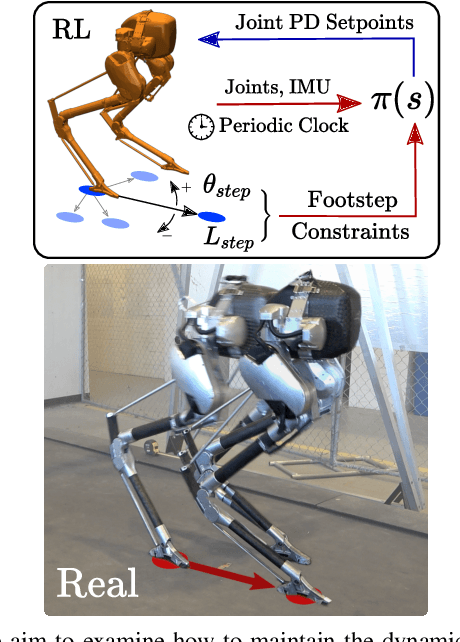
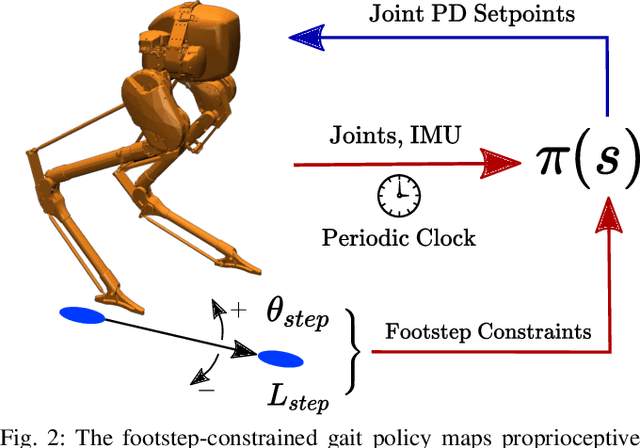
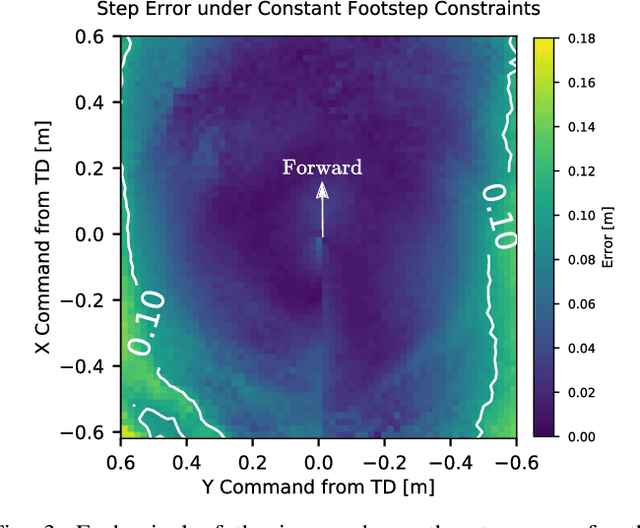
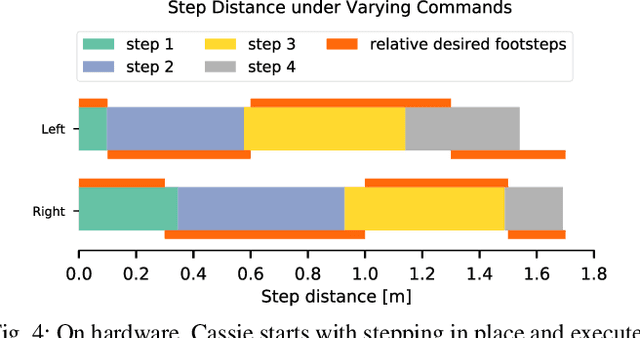
Recently, work on reinforcement learning (RL) for bipedal robots has successfully learned controllers for a variety of dynamic gaits with robust sim-to-real demonstrations. In order to maintain balance, the learned controllers have full freedom of where to place the feet, resulting in highly robust gaits. In the real world however, the environment will often impose constraints on the feasible footstep locations, typically identified by perception systems. Unfortunately, most demonstrated RL controllers on bipedal robots do not allow for specifying and responding to such constraints. This missing control interface greatly limits the real-world application of current RL controllers. In this paper, we aim to maintain the robust and dynamic nature of learned gaits while also respecting footstep constraints imposed externally. We develop an RL formulation for training dynamic gait controllers that can respond to specified touchdown locations. We then successfully demonstrate simulation and sim-to-real performance on the bipedal robot Cassie. In addition, we use supervised learning to induce a transition model for accurately predicting the next touchdown locations that the controller can achieve given the robot's proprioceptive observations. This model paves the way for integrating the learned controller into a full-order robot locomotion planner that robustly satisfies both balance and environmental constraints.
Ankle Torque During Mid-Stance Does Not Lower Energy Requirements of Steady Gaits
Nov 29, 2021



In this paper, we investigate whether applying ankle torques during mid-stance can be a more effective way to reduce energetic cost of locomotion than actuating leg length alone. Ankles are useful in human gaits for many reasons including static balancing. In this work, we specifically avoid the heel-strike and toe-off benefits to investigate whether the progression of the center of pressure from heel-to-toe during mid-stance, or some other approach, is beneficial in and of itself. We use an "Ankle Actuated Spring Loaded Inverted Pendulum" model to simulate the shifting center of pressure dynamics, and trajectory optimization is applied to find limit cycles that minimize cost of transport. The results show that, for the vast majority of gaits, ankle torques do not affect cost of transport. Ankles reduce the cost of transport during a narrow band of gaits at the transition from grounded running to aerial running. This suggests that applying ankle torque during mid-stance of a steady gait is not a directly beneficial strategy, but is most likely a path between beneficial heel-strikes and toe-offs.
Design and Control of a Recovery System for Legged Robots
Nov 29, 2021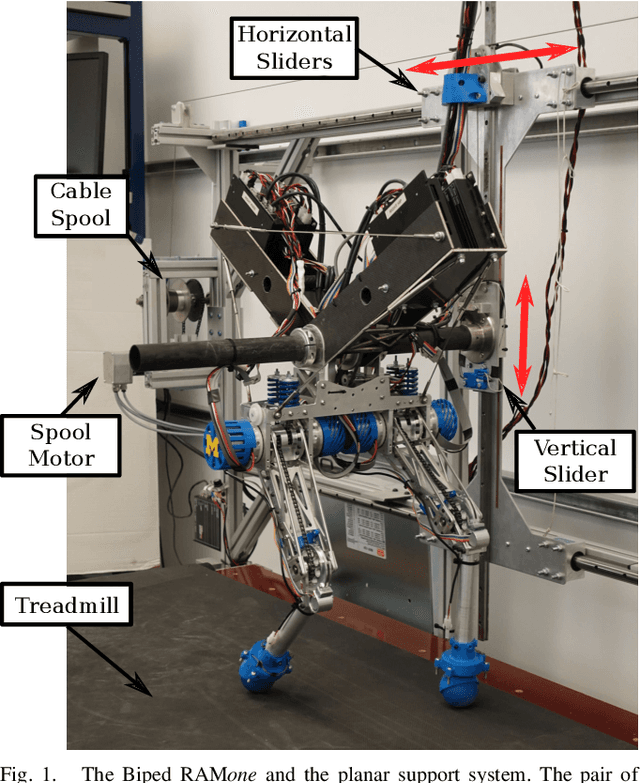
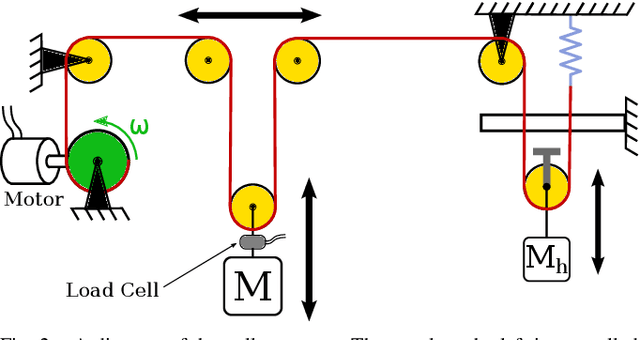
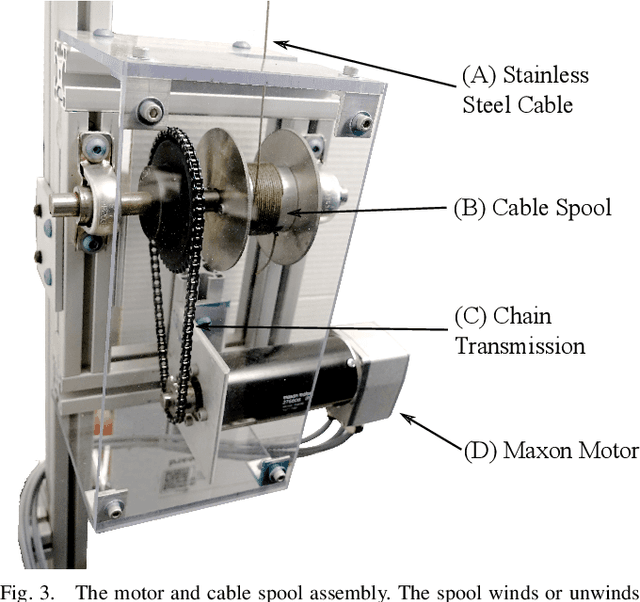

This paper describes the design and control of a support and recovery system for use with planar legged robots. The system operates in three modes. First, it can be operated in a fully transparent mode where no forces are applied to the robot. In this mode, the system follows the robot closely to be able to quickly catch the robot if needed. Second, it can provide a vertical supportive force to assist a robot during operation. Third, it can catch the robot and pull it away from the ground after a failure to avoid falls and the associated damages. In this mode, the system automatically resets the robot after a trial allowing for multiple consecutive trials to be run without manual intervention. The supportive forces are applied to the robot through an actuated cable and pulley system that uses series elastic actuation with a unidirectional spring to enable truly transparent operation. The nonlinear nature of this system necessitates careful design of controllers to ensure predictable, safe behaviors. In this paper we introduce the mechatronic design of the recovery system, develop suitable controllers, and evaluate the system's performance on the bipedal robot RAMone.
Blind Bipedal Stair Traversal via Sim-to-Real Reinforcement Learning
May 18, 2021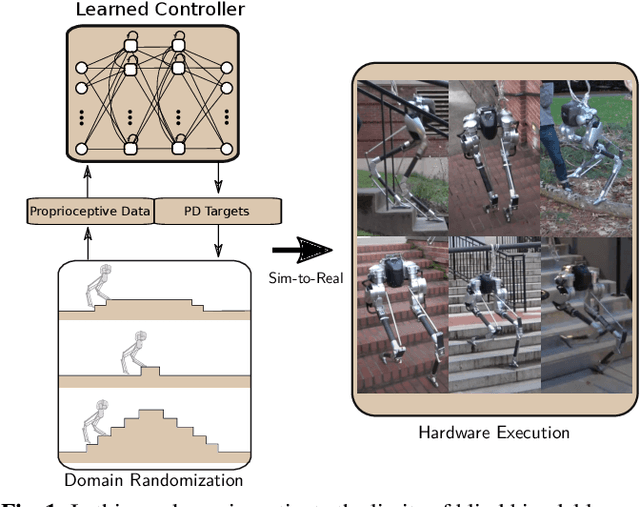
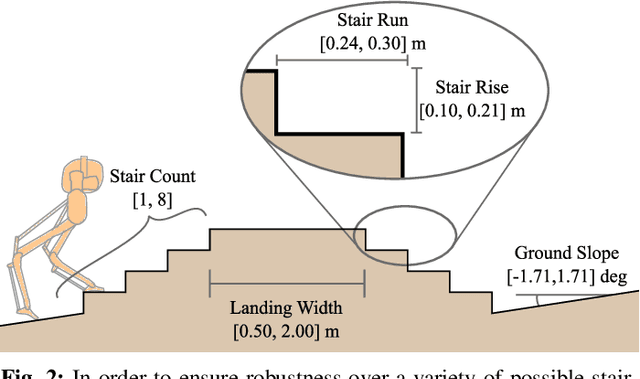

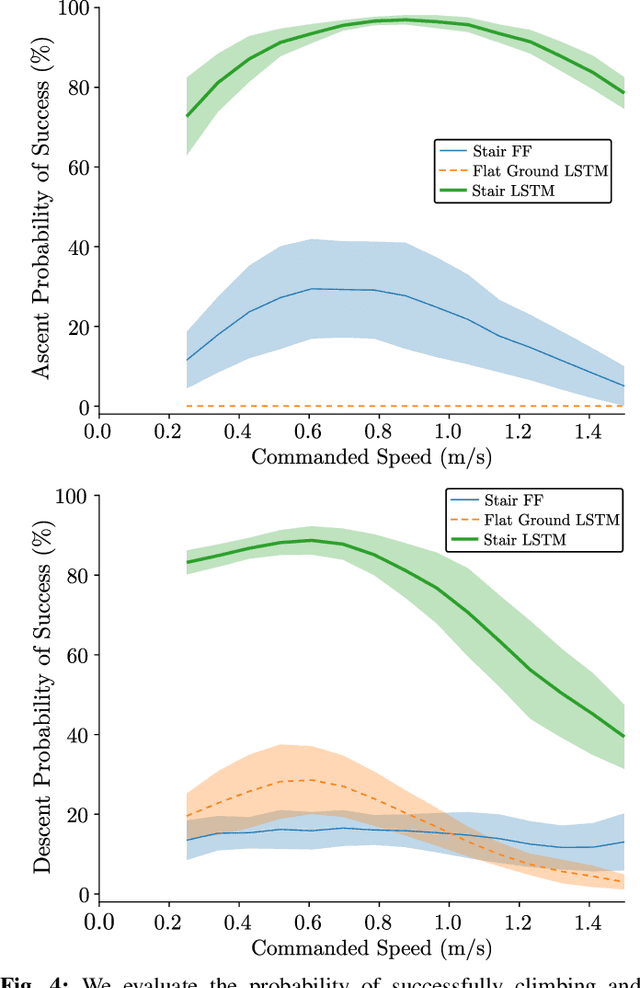
Accurate and precise terrain estimation is a difficult problem for robot locomotion in real-world environments. Thus, it is useful to have systems that do not depend on accurate estimation to the point of fragility. In this paper, we explore the limits of such an approach by investigating the problem of traversing stair-like terrain without any external perception or terrain models on a bipedal robot. For such blind bipedal platforms, the problem appears difficult (even for humans) due to the surprise elevation changes. Our main contribution is to show that sim-to-real reinforcement learning (RL) can achieve robust locomotion over stair-like terrain on the bipedal robot Cassie using only proprioceptive feedback. Importantly, this only requires modifying an existing flat-terrain training RL framework to include stair-like terrain randomization, without any changes in reward function. To our knowledge, this is the first controller for a bipedal, human-scale robot capable of reliably traversing a variety of real-world stairs and other stair-like disturbances using only proprioception.
Learning Task Space Actions for Bipedal Locomotion
Nov 09, 2020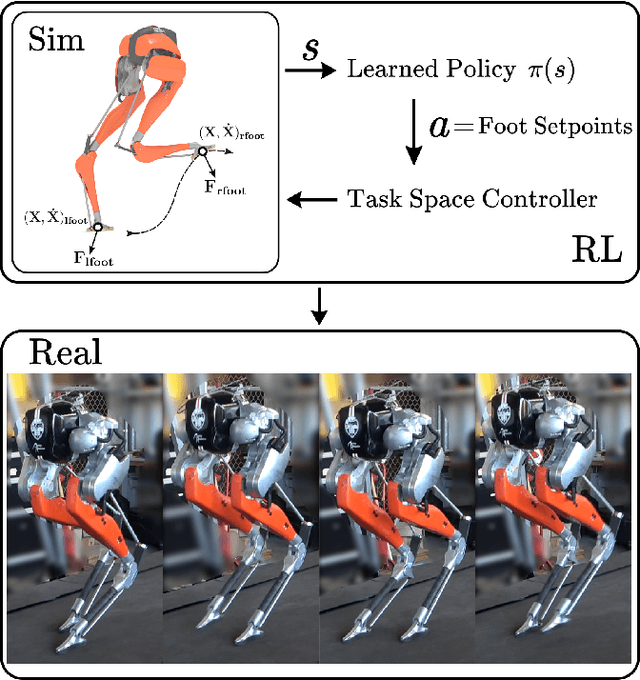
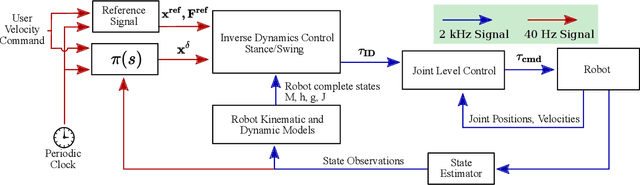
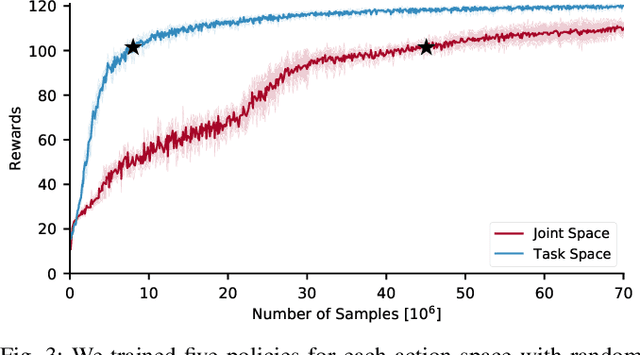
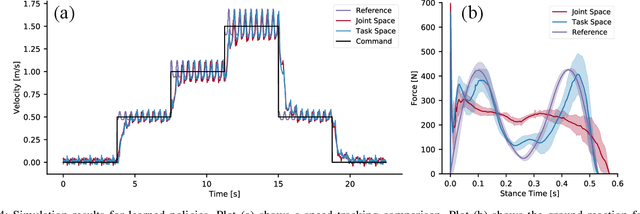
Recent work has demonstrated the success of reinforcement learning (RL) for training bipedal locomotion policies for real robots. This prior work, however, has focused on learning joint-coordination controllers based on an objective of following joint trajectories produced by already available controllers. As such, it is difficult to train these approaches to achieve higher-level goals of legged locomotion, such as simply specifying the desired end-effector foot movement or ground reaction forces. In this work, we propose an approach for integrating knowledge of the robot system into RL to allow for learning at the level of task space actions in terms of feet setpoints. In particular, we integrate learning a task space policy with a model-based inverse dynamics controller, which translates task space actions into joint-level controls. With this natural action space for learning locomotion, the approach is more sample efficient and produces desired task space dynamics compared to learning purely joint space actions. We demonstrate the approach in simulation and also show that the learned policies are able to transfer to the real bipedal robot Cassie. This result encourages further research towards incorporating bipedal control techniques into the structure of the learning process to enable dynamic behaviors.
Learning Spring Mass Locomotion: Guiding Policies with a Reduced-Order Model
Oct 21, 2020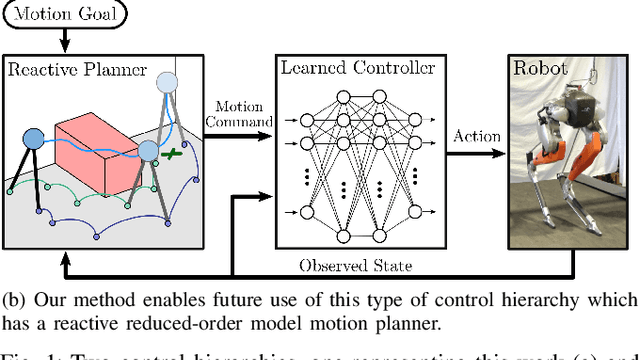
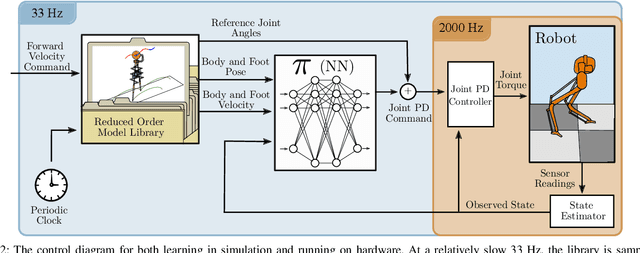
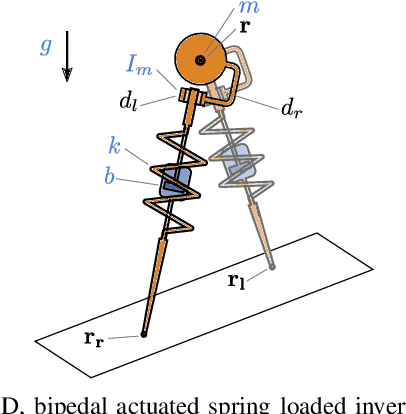
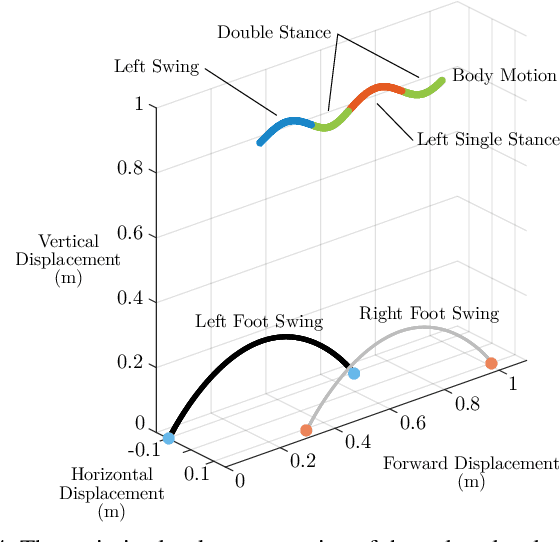
In this paper, we describe an approach to achieve dynamic legged locomotion on physical robots which combines existing methods for control with reinforcement learning. Specifically, our goal is a control hierarchy in which highest-level behaviors are planned through reduced-order models, which describe the fundamental physics of legged locomotion, and lower level controllers utilize a learned policy that can bridge the gap between the idealized, simple model and the complex, full order robot. The high-level planner can use a model of the environment and be task specific, while the low-level learned controller can execute a wide range of motions so that it applies to many different tasks. In this letter we describe this learned dynamic walking controller and show that a range of walking motions from reduced-order models can be used as the command and primary training signal for learned policies. The resulting policies do not attempt to naively track the motion (as a traditional trajectory tracking controller would) but instead balance immediate motion tracking with long term stability. The resulting controller is demonstrated on a human scale, unconstrained, untethered bipedal robot at speeds up to 1.2 m/s. This letter builds the foundation of a generic, dynamic learned walking controller that can be applied to many different tasks.