 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-to-Real Learning of Footstep-Constrained Bipedal Dynamic Walking
Mar 15, 2022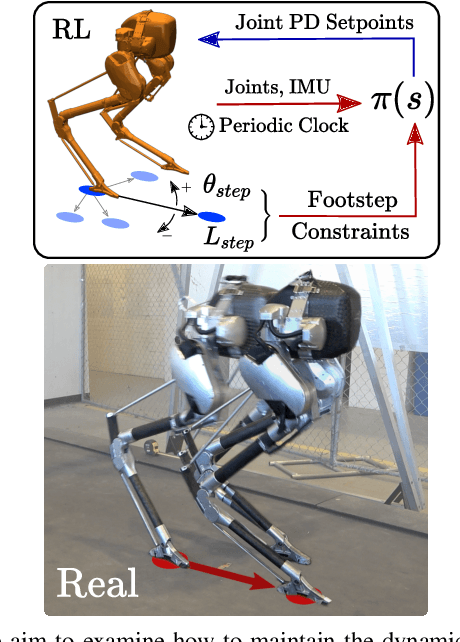
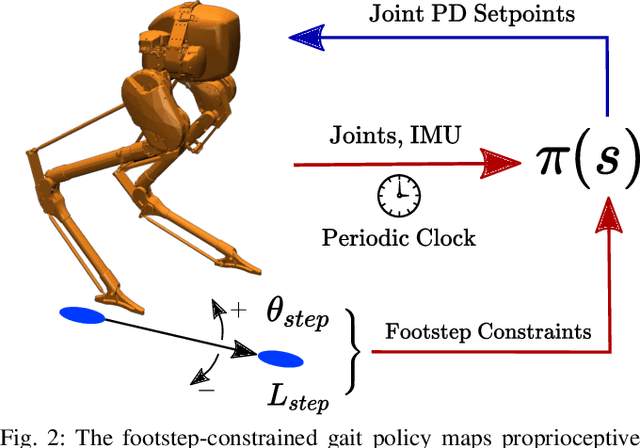
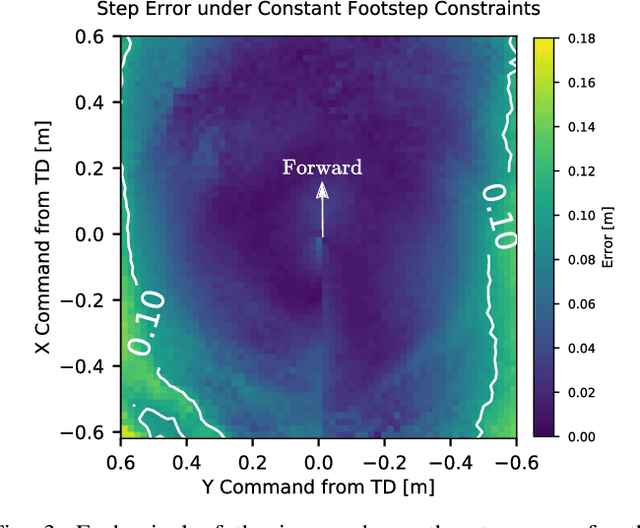
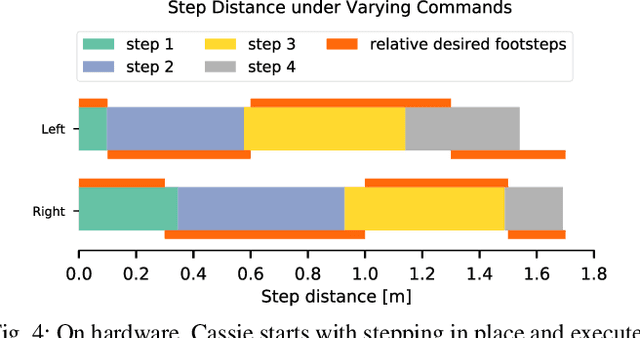
Recently, work on reinforcement learning (RL) for bipedal robots has successfully learned controllers for a variety of dynamic gaits with robust sim-to-real demonstrations. In order to maintain balance, the learned controllers have full freedom of where to place the feet, resulting in highly robust gaits. In the real world however, the environment will often impose constraints on the feasible footstep locations, typically identified by perception systems. Unfortunately, most demonstrated RL controllers on bipedal robots do not allow for specifying and responding to such constraints. This missing control interface greatly limits the real-world application of current RL controllers. In this paper, we aim to maintain the robust and dynamic nature of learned gaits while also respecting footstep constraints imposed externally. We develop an RL formulation for training dynamic gait controllers that can respond to specified touchdown locations. We then successfully demonstrate simulation and sim-to-real performance on the bipedal robot Cassie. In addition, we use supervised learning to induce a transition model for accurately predicting the next touchdown locations that the controller can achieve given the robot's proprioceptive observations. This model paves the way for integrating the learned controller into a full-order robot locomotion planner that robustly satisfies both balance and environmental constraints.
Blind Bipedal Stair Traversal via Sim-to-Real Reinforcement Learning
May 18, 2021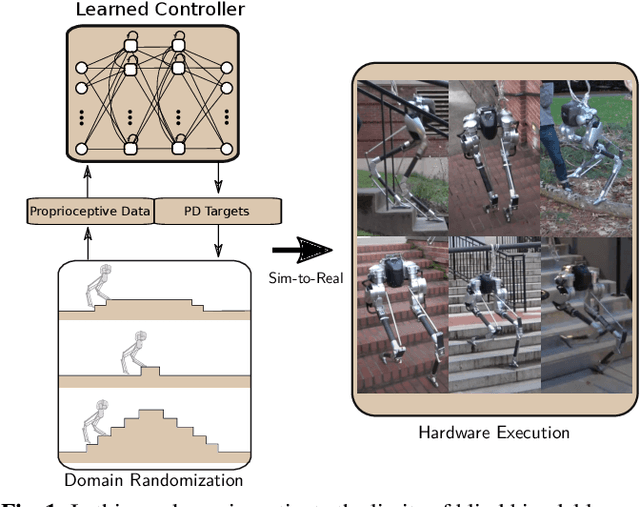
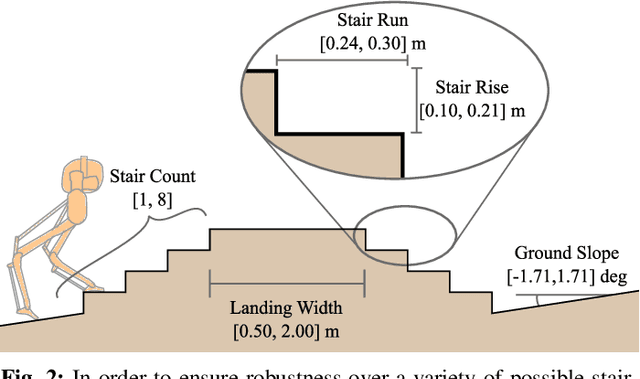

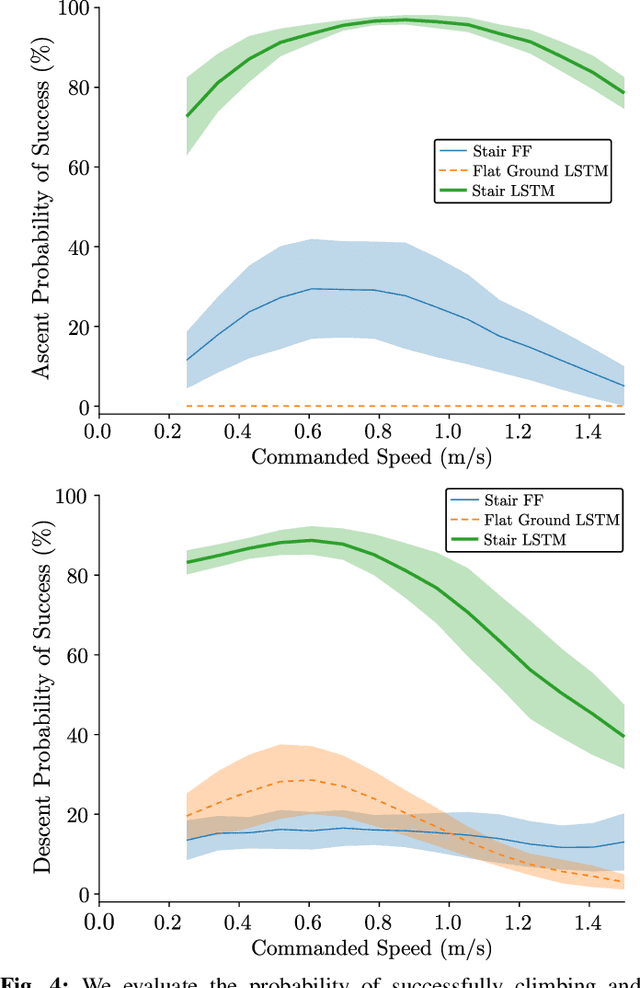
Accurate and precise terrain estimation is a difficult problem for robot locomotion in real-world environments. Thus, it is useful to have systems that do not depend on accurate estimation to the point of fragility. In this paper, we explore the limits of such an approach by investigating the problem of traversing stair-like terrain without any external perception or terrain models on a bipedal robot. For such blind bipedal platforms, the problem appears difficult (even for humans) due to the surprise elevation changes. Our main contribution is to show that sim-to-real reinforcement learning (RL) can achieve robust locomotion over stair-like terrain on the bipedal robot Cassie using only proprioceptive feedback. Importantly, this only requires modifying an existing flat-terrain training RL framework to include stair-like terrain randomization, without any changes in reward function. To our knowledge, this is the first controller for a bipedal, human-scale robot capable of reliably traversing a variety of real-world stairs and other stair-like disturbances using only proprioception.
Sim-to-Real Learning of All Common Bipedal Gaits via Periodic Reward Composition
Nov 02, 2020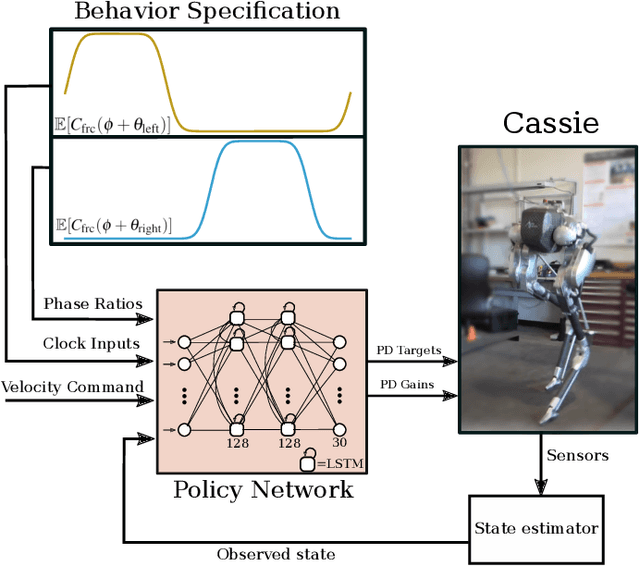
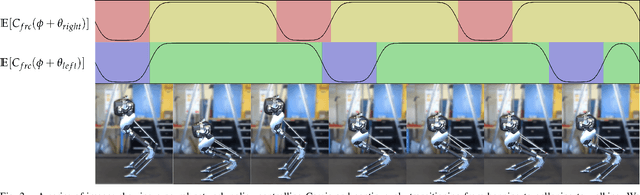
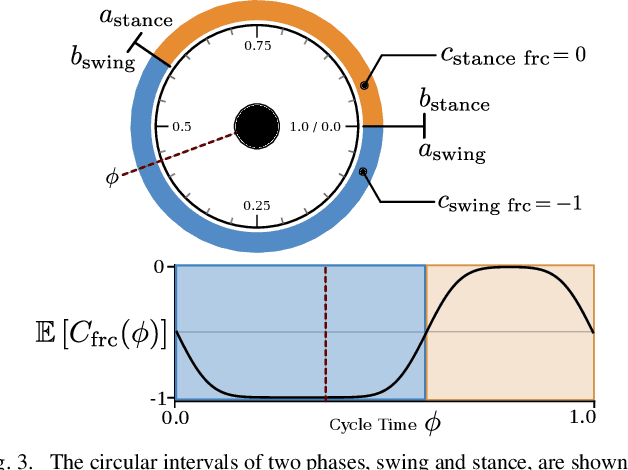
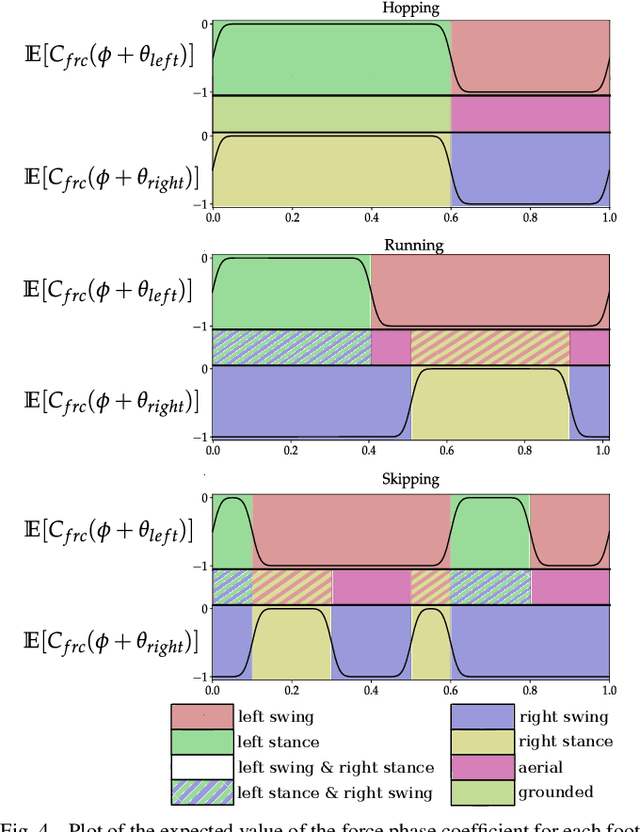
We study the problem of realizing the full spectrum of bipedal locomotion on a real robot with sim-to-real reinforcement learning (RL). A key challenge of learning legged locomotion is describing different gaits, via reward functions, in a way that is intuitive for the designer and specific enough to reliably learn the gait across different initial random seeds or hyperparameters. A common approach is to use reference motions (e.g. trajectories of joint positions) to guide learning. However, finding high-quality reference motions can be difficult and the trajectories themselves narrowly constrain the space of learned motion. At the other extreme, reference-free reward functions are often underspecified (e.g. move forward) leading to massive variance in policy behavior, or are the product of significant reward-shaping via trial-and-error, making them exclusive to specific gaits. In this work, we propose a reward-specification framework based on composing simple probabilistic periodic costs on basic forces and velocities. We instantiate this framework to define a parametric reward function with intuitive settings for all common bipedal gaits - standing, walking, hopping, running, and skipping. Using this function we demonstrate successful sim-to-real transfer of the learned gaits to the bipedal robot Cassie, as well as a generic policy that can transition between all of the two-beat gaits.
Learning Memory-Based Control for Human-Scale Bipedal Locomotion
Jun 03, 2020
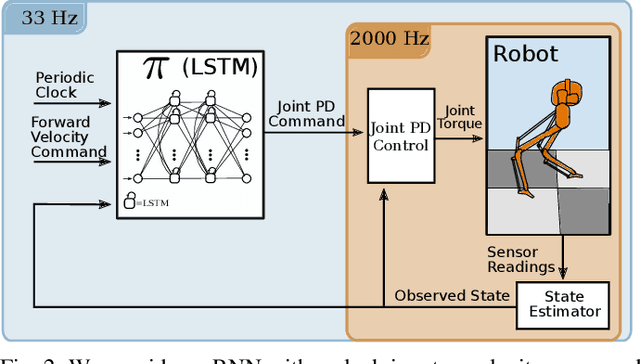
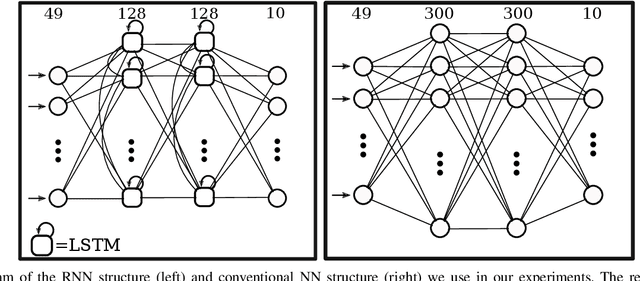

Controlling a non-statically stable biped is a difficult problem largely due to the complex hybrid dynamics involved. Recent work has demonstrated the effectiveness of reinforcement learning (RL) for simulation-based training of neural network controllers that successfully transfer to real bipeds. The existing work, however, has primarily used simple memoryless network architectures, even though more sophisticated architectures, such as those including memory, often yield superior performance in other RL domains. In this work, we consider recurrent neural networks (RNNs) for sim-to-real biped locomotion, allowing for policies that learn to use internal memory to model important physical properties. We show that while RNNs are able to significantly outperform memoryless policies in simulation, they do not exhibit superior behavior on the real biped due to overfitting to the simulation physics unless trained using dynamics randomization to prevent overfitting; this leads to consistently better sim-to-real transfer. We also show that RNNs could use their learned memory states to perform online system identification by encoding parameters of the dynamics into memory.