 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Parsing in Sequences Using CoordConv Gated Recurrent Networks
Paper and Code



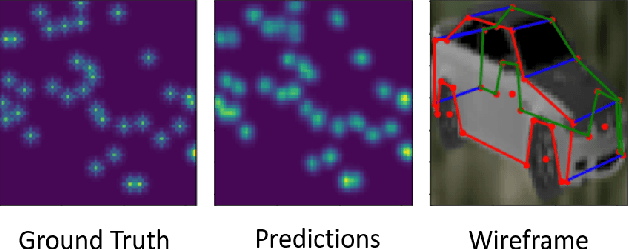
We present a monocular object parsing framework for consistent keypoint localization by capturing temporal correlation on sequential data. In this paper, we propose a novel recurrent network based architecture to model long-range dependencies between intermediate features which are highly useful in tasks like keypoint localization and tracking. We leverage the expressiveness of the popular stacked hourglass architecture and augment it by adopting memory units between intermediate layers of the network with weights shared across stages for video frames. We observe that this weight sharing scheme not only enables us to frame hourglass architecture as a recurrent network but also prove to be highly effective in producing increasingly refined estimates for sequential tasks. Furthermore, we propose a new memory cell, we call CoordConvGRU which learns to selectively preserve spatio-temporal correlation and showcase our results on the keypoint localization task. The experiments show that our approach is able to model the motion dynamics between the frames and significantly outperforms the baseline hourglass network. Even though our network is trained on a synthetically rendered dataset, we observe that with minimal fine tuning on 300 real images we are able to achieve performance at par with various state-of-the-art methods trained with the same level of supervisory inputs. By using a simpler architecture than other methods enables us to run it in real time on a standard GPU which is desirable for such applications. Finally, we make our architectures and 524 annotated sequences of cars from KITTI dataset publicly available.