 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-to-Sim Robot Policy Evaluation with Gaussian Splatting Simulation of Soft-Body Interactions
Nov 06, 2025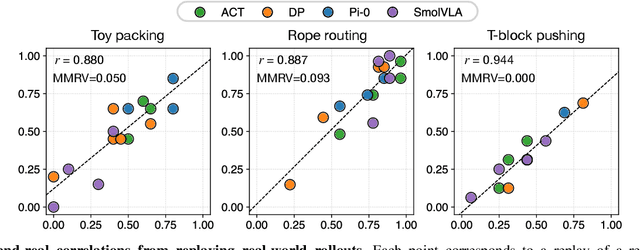

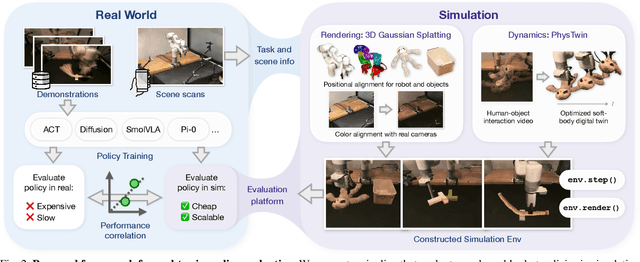
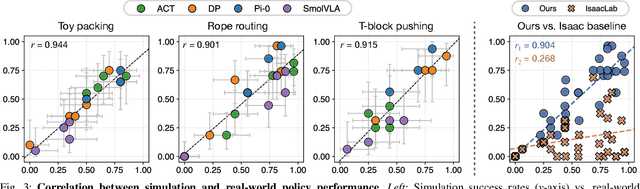
Robotic manipulation policies are advancing rapidly, but their direct evaluation in the real world remains costly, time-consuming, and difficult to reproduce, particularly for tasks involving deformable objects. Simulation provides a scalable and systematic alternative, yet existing simulators often fail to capture the coupled visual and physical complexity of soft-body interactions. We present a real-to-sim policy evaluation framework that constructs soft-body digital twins from real-world videos and renders robots, objects, and environments with photorealistic fidelity using 3D Gaussian Splatting. We validate our approach on representative deformable manipulation tasks, including plush toy packing, rope routing, and T-block pushing, demonstrating that simulated rollouts correlate strongly with real-world execution performance and reveal key behavioral patterns of learned policies. Our results suggest that combining physics-informed reconstruction with high-quality rendering enables reproducible, scalable, and accurate evaluation of robotic manipulation policies. Website: https://real2sim-eval.github.io/
PhysGen3D: Crafting a Miniature Interactive World from a Single Image
Mar 26, 2025Envisioning physically plausible outcomes from a single image requires a deep understanding of the world's dynamics. To address this, we introduce PhysGen3D, a novel framework that transforms a single image into an amodal, camera-centric, interactive 3D scene. By combining advanced image-based geometric and semantic understanding with physics-based simulation, PhysGen3D creates an interactive 3D world from a static image, enabling us to "imagine" and simulate future scenarios based on user input. At its core, PhysGen3D estimates 3D shapes, poses, physical and lighting properties of objects, thereby capturing essential physical attributes that drive realistic object interactions. This framework allows users to specify precise initial conditions, such as object speed or material properties, for enhanced control over generated video outcomes. We evaluate PhysGen3D's performance against closed-source state-of-the-art (SOTA) image-to-video models, including Pika, Kling, and Gen-3, showing PhysGen3D's capacity to generate videos with realistic physics while offering greater flexibility and fine-grained control. Our results show that PhysGen3D achieves a unique balance of photorealism, physical plausibility, and user-driven interactivity, opening new possibilities for generating dynamic, physics-grounded video from an image.
S2O: Static to Openable Enhancement for Articulated 3D Objects
Sep 27, 2024



Despite much progress in large 3D datasets there are currently few interactive 3D object datasets, and their scale is limited due to the manual effort required in their construction. We introduce the static to openable (S2O) task which creates interactive articulated 3D objects from static counterparts through openable part detection, motion prediction, and interior geometry completion. We formulate a unified framework to tackle this task, and curate a challenging dataset of openable 3D objects that serves as a test bed for systematic evaluation. Our experiments benchmark methods from prior work and simple yet effective heuristics for the S2O task. We find that turning static 3D objects into interactively openable counterparts is possible but that all methods struggle to generalize to realistic settings of the task, and we highlight promising future work directions.
RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation
Feb 23, 2024



Robots need to explore their surroundings to adapt to and tackle tasks in unknown environments. Prior work has proposed building scene graphs of the environment but typically assumes that the environment is static, omitting regions that require active interactions. This severely limits their ability to handle more complex tasks in household and office environments: before setting up a table, robots must explore drawers and cabinets to locate all utensils and condiments. In this work, we introduce the novel task of interactive scene exploration, wherein robots autonomously explore environments and produce an action-conditioned scene graph (ACSG) that captures the structure of the underlying environment. The ACSG accounts for both low-level information, such as geometry and semantics, and high-level information, such as the action-conditioned relationships between different entities in the scene. To this end, we present the Robotic Exploration (RoboEXP) system, which incorporates the Large Multimodal Model (LMM) and an explicit memory design to enhance our system's capabilities. The robot reasons about what and how to explore an object, accumulating new information through the interaction process and incrementally constructing the ACSG. We apply our system across various real-world settings in a zero-shot manner, demonstrating its effectiveness in exploring and modeling environments it has never seen before. Leveraging the constructed ACSG, we illustrate the effectiveness and efficiency of our RoboEXP system in facilitating a wide range of real-world manipulation tasks involving rigid, articulated objects, nested objects like Matryoshka dolls, and deformable objects like cloth.
Habitat Synthetic Scenes Dataset (HSSD-200): An Analysis of 3D Scene Scale and Realism Tradeoffs for ObjectGoal Navigation
Jun 21, 2023We contribute the Habitat Synthetic Scene Dataset, a dataset of 211 high-quality 3D scenes, and use it to test navigation agent generalization to realistic 3D environments. Our dataset represents real interiors and contains a diverse set of 18,656 models of real-world objects. We investigate the impact of synthetic 3D scene dataset scale and realism on the task of training embodied agents to find and navigate to objects (ObjectGoal navigation). By comparing to synthetic 3D scene datasets from prior work, we find that scale helps in generalization, but the benefits quickly saturate, making visual fidelity and correlation to real-world scenes more important. Our experiments show that agents trained on our smaller-scale dataset can match or outperform agents trained on much larger datasets. Surprisingly, we observe that agents trained on just 122 scenes from our dataset outperform agents trained on 10,000 scenes from the ProcTHOR-10K dataset in terms of zero-shot generalization in real-world scanned environments.
OPDMulti: Openable Part Detection for Multiple Objects
Mar 24, 2023Openable part detection is the task of detecting the openable parts of an object in a single-view image, and predicting corresponding motion parameters. Prior work investigated the unrealistic setting where all input images only contain a single openable object. We generalize this task to scenes with multiple objects each potentially possessing openable parts, and create a corresponding dataset based on real-world scenes. We then address this more challenging scenario with OPDFormer: a part-aware transformer architecture. Our experiments show that the OPDFormer architecture significantly outperforms prior work. The more realistic multiple-object scenarios we investigated remain challenging for all methods, indicating opportunities for future work.
Articulated 3D Human-Object Interactions from RGB Videos: An Empirical Analysis of Approaches and Challenges
Sep 12, 2022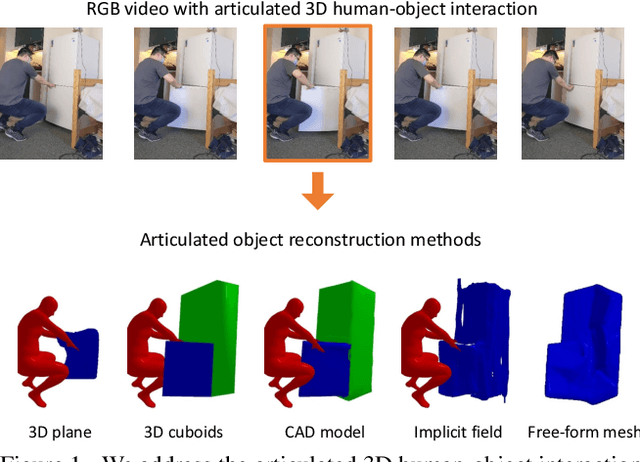
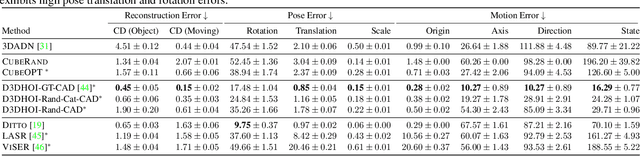
Human-object interactions with articulated objects are common in everyday life. Despite much progress in single-view 3D reconstruction, it is still challenging to infer an articulated 3D object model from an RGB video showing a person manipulating the object. We canonicalize the task of articulated 3D human-object interaction reconstruction from RGB video, and carry out a systematic benchmark of five families of methods for this task: 3D plane estimation, 3D cuboid estimation, CAD model fitting, implicit field fitting, and free-form mesh fitting. Our experiments show that all methods struggle to obtain high accuracy results even when provided ground truth information about the observed objects. We identify key factors which make the task challenging and suggest directions for future work on this challenging 3D computer vision task. Short video summary at https://www.youtube.com/watch?v=5tAlKBojZwc
OPD: Single-view 3D Openable Part Detection
Mar 30, 2022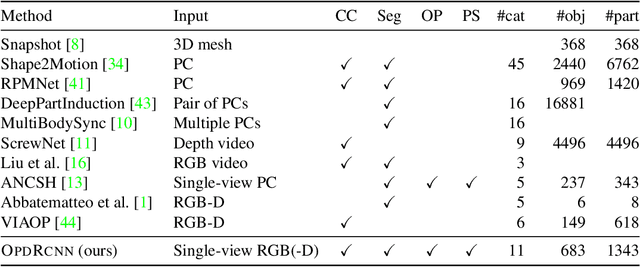

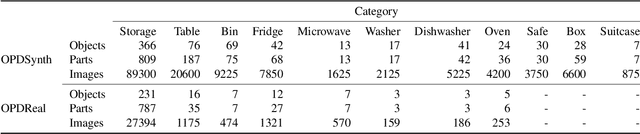
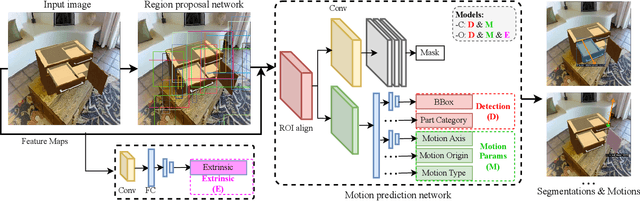
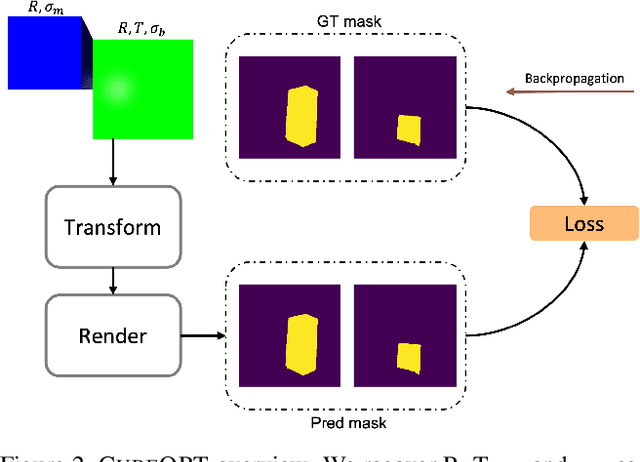
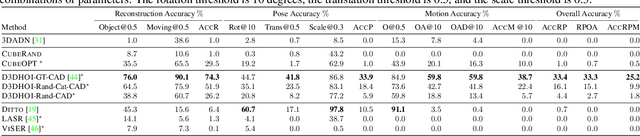
We address the task of predicting what parts of an object can open and how they move when they do so. The input is a single image of an object, and as output we detect what parts of the object can open, and the motion parameters describing the articulation of each openable part. To tackle this task, we create two datasets of 3D objects: OPDSynth based on existing synthetic objects, and OPDReal based on RGBD reconstructions of real objects. We then design OPDRCNN, a neural architecture that detects openable parts and predicts their motion parameters. Our experiments show that this is a challenging task especially when considering generalization across object categories, and the limited amount of information in a single image. Our architecture outperforms baselines and prior work especially for RGB image inputs. Short video summary at https://www.youtube.com/watch?v=P85iCaD0rfc
SAPIEN: A SimulAted Part-based Interactive ENvironment
Mar 19, 2020


Building home assistant robots has long been a pursuit for vision and robotics researchers. To achieve this task, a simulated environment with physically realistic simulation, sufficient articulated objects, and transferability to the real robot is indispensable. Existing environments achieve these requirements for robotics simulation with different levels of simplification and focus. We take one step further in constructing an environment that supports household tasks for training robot learning algorithm. Our work, SAPIEN, is a realistic and physics-rich simulated environment that hosts a large-scale set for articulated objects. Our SAPIEN enables various robotic vision and interaction tasks that require detailed part-level understanding.We evaluate state-of-the-art vision algorithms for part detection and motion attribute recognition as well as demonstrate robotic interaction tasks using heuristic approaches and reinforcement learning algorithms. We hope that our SAPIEN can open a lot of research directions yet to be explored, including learning cognition through interaction, part motion discovery, and construction of robotics-ready simulated game environment.