 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtiverse: A Diverse and Physically Grounded Dataset for Articulated Objects
May 23, 2026We present Artiverse, a diverse and physically grounded dataset of high-quality articulated 3D objects designed for realistic functional modeling and simulation. Artiverse contains 5.4K human-authored objects across a broad range of 88 categories, aggregated from multiple 3D static repositories. Objects are annotated with functional parts, interior structures, realistic kinematic relationships and articulated joints including multi-DoF joints, and physical attributes such as metric scale, material, and mass. We develop a semi-automated annotation pipeline that combines few-shot segmentation, geometric reasoning, and multi-stage human verification to achieve high-quality and efficient annotation, reducing manual annotation time by over 30%. We demonstrate the value of Artiverse on tasks of part mobility analysis, articulated object generation, and physics-based interaction. Artiverse provides a data resource to advance functional understanding for articulated objects.
EgoFun3D: Modeling Interactive Objects from Egocentric Videos using Function Templates
Apr 13, 2026We present EgoFun3D, a coordinated task formulation, dataset, and benchmark for modeling interactive 3D objects from egocentric videos. Interactive objects are of high interest for embodied AI but scarce, making modeling from readily available real-world videos valuable. Our task focuses on obtaining simulation-ready interactive 3D objects from egocentric video input. While prior work largely focuses on articulations, we capture general cross-part functional mappings (e.g., rotation of stove knob controls stove burner temperature) through function templates, a structured computational representation. Function templates enable precise evaluation and direct compilation into executable code across simulation platforms. To enable comprehensive benchmarking, we introduce a dataset of 271 egocentric videos featuring challenging real-world interactions with paired 3D geometry, segmentation over 2D and 3D, articulation and function template annotations. To tackle the task, we propose a 4-stage pipeline consisting of: 2D part segmentation, reconstruction, articulation estimation, and function template inference. Comprehensive benchmarking shows that the task is challenging for off-the-shelf methods, highlighting avenues for future work.
Diorama: Unleashing Zero-shot Single-view 3D Scene Modeling
Nov 29, 2024



Reconstructing structured 3D scenes from RGB images using CAD objects unlocks efficient and compact scene representations that maintain compositionality and interactability. Existing works propose training-heavy methods relying on either expensive yet inaccurate real-world annotations or controllable yet monotonous synthetic data that do not generalize well to unseen objects or domains. We present Diorama, the first zero-shot open-world system that holistically models 3D scenes from single-view RGB observations without requiring end-to-end training or human annotations. We show the feasibility of our approach by decomposing the problem into subtasks and introduce robust, generalizable solutions to each: architecture reconstruction, 3D shape retrieval, object pose estimation, and scene layout optimization. We evaluate our system on both synthetic and real-world data to show we significantly outperform baselines from prior work. We also demonstrate generalization to internet images and the text-to-scene task.
SINGAPO: Single Image Controlled Generation of Articulated Parts in Object
Oct 21, 2024
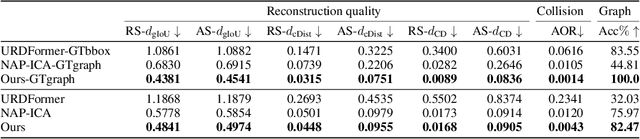


We address the challenge of creating 3D assets for household articulated objects from a single image. Prior work on articulated object creation either requires multi-view multi-state input, or only allows coarse control over the generation process. These limitations hinder the scalability and practicality for articulated object modeling. In this work, we propose a method to generate articulated objects from a single image. Observing the object in resting state from an arbitrary view, our method generates an articulated object that is visually consistent with the input image. To capture the ambiguity in part shape and motion posed by a single view of the object, we design a diffusion model that learns the plausible variations of objects in terms of geometry and kinematics. To tackle the complexity of generating structured data with attributes in multiple domains, we design a pipeline that produces articulated objects from high-level structure to geometric details in a coarse-to-fine manner, where we use a part connectivity graph and part abstraction as proxies. Our experiments show that our method outperforms the state-of-the-art in articulated object creation by a large margin in terms of the generated object realism, resemblance to the input image, and reconstruction quality.
S2O: Static to Openable Enhancement for Articulated 3D Objects
Sep 27, 2024



Despite much progress in large 3D datasets there are currently few interactive 3D object datasets, and their scale is limited due to the manual effort required in their construction. We introduce the static to openable (S2O) task which creates interactive articulated 3D objects from static counterparts through openable part detection, motion prediction, and interior geometry completion. We formulate a unified framework to tackle this task, and curate a challenging dataset of openable 3D objects that serves as a test bed for systematic evaluation. Our experiments benchmark methods from prior work and simple yet effective heuristics for the S2O task. We find that turning static 3D objects into interactively openable counterparts is possible but that all methods struggle to generalize to realistic settings of the task, and we highlight promising future work directions.