 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Dori: Memorization in Text-to-Image Diffusion Models Is Less Local Than Assumed
Jul 22, 2025Text-to-image diffusion models (DMs) have achieved remarkable success in image generation. However, concerns about data privacy and intellectual property remain due to their potential to inadvertently memorize and replicate training data. Recent mitigation efforts have focused on identifying and pruning weights responsible for triggering replication, based on the assumption that memorization can be localized. Our research assesses the robustness of these pruning-based approaches. We demonstrate that even after pruning, minor adjustments to text embeddings of input prompts are sufficient to re-trigger data replication, highlighting the fragility of these defenses. Furthermore, we challenge the fundamental assumption of memorization locality, by showing that replication can be triggered from diverse locations within the text embedding space, and follows different paths in the model. Our findings indicate that existing mitigation strategies are insufficient and underscore the need for methods that truly remove memorized content, rather than attempting to suppress its retrieval. As a first step in this direction, we introduce a novel adversarial fine-tuning method that iteratively searches for replication triggers and updates the model to increase robustness. Through our research, we provide fresh insights into the nature of memorization in text-to-image DMs and a foundation for building more trustworthy and compliant generative AI.
Implementing Adaptations for Vision AutoRegressive Model
Jul 15, 2025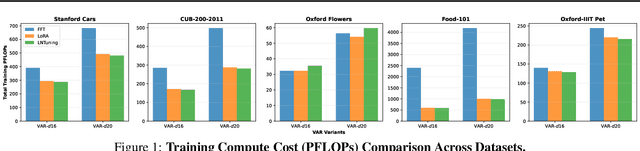

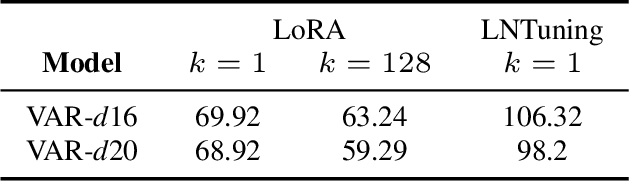
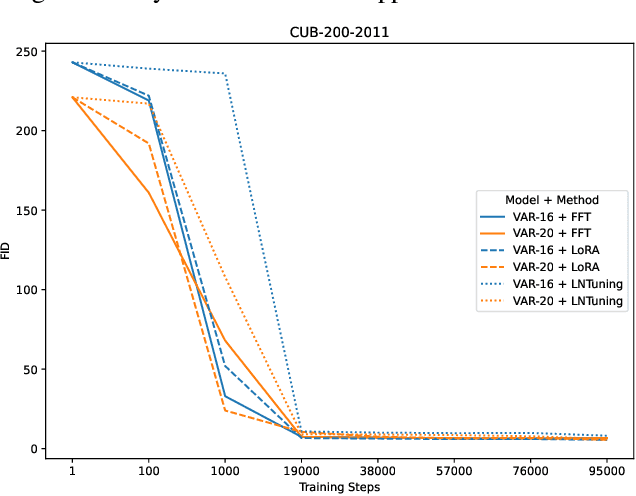
Vision AutoRegressive model (VAR) was recently introduced as an alternative to Diffusion Models (DMs) in image generation domain. In this work we focus on its adaptations, which aim to fine-tune pre-trained models to perform specific downstream tasks, like medical data generation. While for DMs there exist many techniques, adaptations for VAR remain underexplored. Similarly, differentially private (DP) adaptations-ones that aim to preserve privacy of the adaptation data-have been extensively studied for DMs, while VAR lacks such solutions. In our work, we implement and benchmark many strategies for VAR, and compare them to state-of-the-art DM adaptation strategies. We observe that VAR outperforms DMs for non-DP adaptations, however, the performance of DP suffers, which necessitates further research in private adaptations for VAR. Code is available at https://github.com/sprintml/finetuning_var_dp.
Privacy Attacks on Image AutoRegressive Models
Feb 04, 2025Image autoregressive (IAR) models have surpassed diffusion models (DMs) in both image quality (FID: 1.48 vs. 1.58) and generation speed. However, their privacy risks remain largely unexplored. To address this, we conduct a comprehensive privacy analysis comparing IARs to DMs. We develop a novel membership inference attack (MIA) that achieves a significantly higher success rate in detecting training images (TPR@FPR=1%: 86.38% for IARs vs. 4.91% for DMs). Using this MIA, we perform dataset inference (DI) and find that IARs require as few as six samples to detect dataset membership, compared to 200 for DMs, indicating higher information leakage. Additionally, we extract hundreds of training images from an IAR (e.g., 698 from VAR-d30). Our findings highlight a fundamental privacy-utility trade-off: while IARs excel in generation quality and speed, they are significantly more vulnerable to privacy attacks. This suggests that incorporating techniques from DMs, such as per-token probability modeling using diffusion, could help mitigate IARs' privacy risks. Our code is available at https://github.com/sprintml/privacy_attacks_against_iars.
CDI: Copyrighted Data Identification in Diffusion Models
Nov 19, 2024Diffusion Models (DMs) benefit from large and diverse datasets for their training. Since this data is often scraped from the Internet without permission from the data owners, this raises concerns about copyright and intellectual property protections. While (illicit) use of data is easily detected for training samples perfectly re-created by a DM at inference time, it is much harder for data owners to verify if their data was used for training when the outputs from the suspect DM are not close replicas. Conceptually, membership inference attacks (MIAs), which detect if a given data point was used during training, present themselves as a suitable tool to address this challenge. However, we demonstrate that existing MIAs are not strong enough to reliably determine the membership of individual images in large, state-of-the-art DMs. To overcome this limitation, we propose CDI, a framework for data owners to identify whether their dataset was used to train a given DM. CDI relies on dataset inference techniques, i.e., instead of using the membership signal from a single data point, CDI leverages the fact that most data owners, such as providers of stock photography, visual media companies, or even individual artists, own datasets with multiple publicly exposed data points which might all be included in the training of a given DM. By selectively aggregating signals from existing MIAs and using new handcrafted methods to extract features for these datasets, feeding them to a scoring model, and applying rigorous statistical testing, CDI allows data owners with as little as 70 data points to identify with a confidence of more than 99% whether their data was used to train a given DM. Thereby, CDI represents a valuable tool for data owners to claim illegitimate use of their copyrighted data.
Benchmarking Robust Self-Supervised Learning Across Diverse Downstream Tasks
Jul 18, 2024



Large-scale vision models have become integral in many applications due to their unprecedented performance and versatility across downstream tasks. However, the robustness of these foundation models has primarily been explored for a single task, namely image classification. The vulnerability of other common vision tasks, such as semantic segmentation and depth estimation, remains largely unknown. We present a comprehensive empirical evaluation of the adversarial robustness of self-supervised vision encoders across multiple downstream tasks. Our attacks operate in the encoder embedding space and at the downstream task output level. In both cases, current state-of-the-art adversarial fine-tuning techniques tested only for classification significantly degrade clean and robust performance on other tasks. Since the purpose of a foundation model is to cater to multiple applications at once, our findings reveal the need to enhance encoder robustness more broadly. Our code is available at ${github.com/layer6ai-labs/ssl-robustness}$.
Towards More Realistic Membership Inference Attacks on Large Diffusion Models
Jun 22, 2023Generative diffusion models, including Stable Diffusion and Midjourney, can generate visually appealing, diverse, and high-resolution images for various applications. These models are trained on billions of internet-sourced images, raising significant concerns about the potential unauthorized use of copyright-protected images. In this paper, we examine whether it is possible to determine if a specific image was used in the training set, a problem known in the cybersecurity community and referred to as a membership inference attack. Our focus is on Stable Diffusion, and we address the challenge of designing a fair evaluation framework to answer this membership question. We propose a methodology to establish a fair evaluation setup and apply it to Stable Diffusion, enabling potential extensions to other generative models. Utilizing this evaluation setup, we execute membership attacks (both known and newly introduced). Our research reveals that previously proposed evaluation setups do not provide a full understanding of the effectiveness of membership inference attacks. We conclude that the membership inference attack remains a significant challenge for large diffusion models (often deployed as black-box systems), indicating that related privacy and copyright issues will persist in the foreseeable future.