 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioned Activation Transport for T2I Safety Steering
Mar 03, 2026Despite their impressive capabilities, current Text-to-Image (T2I) models remain prone to generating unsafe and toxic content. While activation steering offers a promising inference-time intervention, we observe that linear activation steering frequently degrades image quality when applied to benign prompts. To address this trade-off, we first construct SafeSteerDataset, a contrastive dataset containing 2300 safe and unsafe prompt pairs with high cosine similarity. Leveraging this data, we propose Conditioned Activation Transport (CAT), a framework that employs a geometry-based conditioning mechanism and nonlinear transport maps. By conditioning transport maps to activate only within unsafe activation regions, we minimize interference with benign queries. We validate our approach on two state-of-the-art architectures: Z-Image and Infinity. Experiments demonstrate that CAT generalizes effectively across these backbones, significantly reducing Attack Success Rate while maintaining image fidelity compared to unsteered generations. Warning: This paper contains potentially offensive text and images.
On Stealing Graph Neural Network Models
Nov 13, 2025Current graph neural network (GNN) model-stealing methods rely heavily on queries to the victim model, assuming no hard query limits. However, in reality, the number of allowed queries can be severely limited. In this paper, we demonstrate how an adversary can extract a GNN with very limited interactions with the model. Our approach first enables the adversary to obtain the model backbone without making direct queries to the victim model and then to strategically utilize a fixed query limit to extract the most informative data. The experiments on eight real-world datasets demonstrate the effectiveness of the attack, even under a very restricted query limit and under defense against model extraction in place. Our findings underscore the need for robust defenses against GNN model extraction threats.
Backdoor Vectors: a Task Arithmetic View on Backdoor Attacks and Defenses
Oct 09, 2025Model merging (MM) recently emerged as an effective method for combining large deep learning models. However, it poses significant security risks. Recent research shows that it is highly susceptible to backdoor attacks, which introduce a hidden trigger into a single fine-tuned model instance that allows the adversary to control the output of the final merged model at inference time. In this work, we propose a simple framework for understanding backdoor attacks by treating the attack itself as a task vector. $Backdoor\ Vector\ (BV)$ is calculated as the difference between the weights of a fine-tuned backdoored model and fine-tuned clean model. BVs reveal new insights into attacks understanding and a more effective framework to measure their similarity and transferability. Furthermore, we propose a novel method that enhances backdoor resilience through merging dubbed $Sparse\ Backdoor\ Vector\ (SBV)$ that combines multiple attacks into a single one. We identify the core vulnerability behind backdoor threats in MM: $inherent\ triggers$ that exploit adversarial weaknesses in the base model. To counter this, we propose $Injection\ BV\ Subtraction\ (IBVS)$ - an assumption-free defense against backdoors in MM. Our results show that SBVs surpass prior attacks and is the first method to leverage merging to improve backdoor effectiveness. At the same time, IBVS provides a lightweight, general defense that remains effective even when the backdoor threat is entirely unknown.
ExpertSim: Fast Particle Detector Simulation Using Mixture-of-Generative-Experts
Aug 28, 2025



Simulating detector responses is a crucial part of understanding the inner workings of particle collisions in the Large Hadron Collider at CERN. Such simulations are currently performed with statistical Monte Carlo methods, which are computationally expensive and put a significant strain on CERN's computational grid. Therefore, recent proposals advocate for generative machine learning methods to enable more efficient simulations. However, the distribution of the data varies significantly across the simulations, which is hard to capture with out-of-the-box methods. In this study, we present ExpertSim - a deep learning simulation approach tailored for the Zero Degree Calorimeter in the ALICE experiment. Our method utilizes a Mixture-of-Generative-Experts architecture, where each expert specializes in simulating a different subset of the data. This allows for a more precise and efficient generation process, as each expert focuses on a specific aspect of the calorimeter response. ExpertSim not only improves accuracy, but also provides a significant speedup compared to the traditional Monte-Carlo methods, offering a promising solution for high-efficiency detector simulations in particle physics experiments at CERN. We make the code available at https://github.com/patrick-bedkowski/expertsim-mix-of-generative-experts.
Learning Graph Representation of Agent Diffusers
May 15, 2025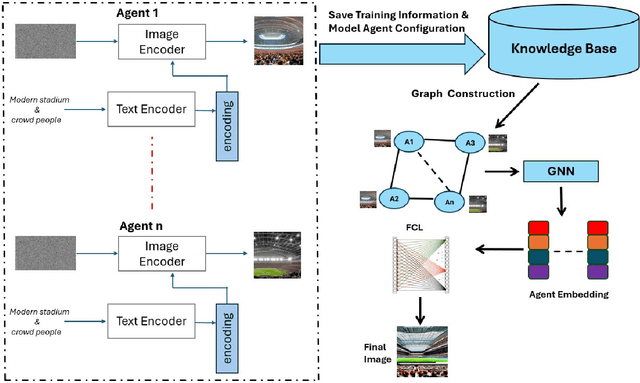
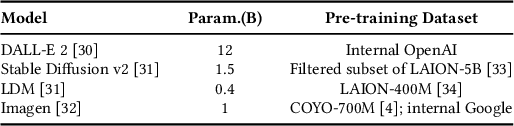
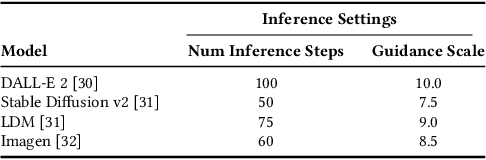

Diffusion-based generative models have significantly advanced text-to-image synthesis, demonstrating impressive text comprehension and zero-shot generalization. These models refine images from random noise based on textual prompts, with initial reliance on text input shifting towards enhanced visual fidelity over time. This transition suggests that static model parameters might not optimally address the distinct phases of generation. We introduce LGR-AD (Learning Graph Representation of Agent Diffusers), a novel multi-agent system designed to improve adaptability in dynamic computer vision tasks. LGR-AD models the generation process as a distributed system of interacting agents, each representing an expert sub-model. These agents dynamically adapt to varying conditions and collaborate through a graph neural network that encodes their relationships and performance metrics. Our approach employs a coordination mechanism based on top-$k$ maximum spanning trees, optimizing the generation process. Each agent's decision-making is guided by a meta-model that minimizes a novel loss function, balancing accuracy and diversity. Theoretical analysis and extensive empirical evaluations show that LGR-AD outperforms traditional diffusion models across various benchmarks, highlighting its potential for scalable and flexible solutions in complex image generation tasks. Code is available at: https://github.com/YousIA/LGR_AD
Maybe I Should Not Answer That, but... Do LLMs Understand The Safety of Their Inputs?
Feb 22, 2025



Ensuring the safety of the Large Language Model (LLM) is critical, but currently used methods in most cases sacrifice the model performance to obtain increased safety or perform poorly on data outside of their adaptation distribution. We investigate existing methods for such generalization and find them insufficient. Surprisingly, while even plain LLMs recognize unsafe prompts, they may still generate unsafe responses. To avoid performance degradation and preserve safe performance, we advocate for a two-step framework, where we first identify unsafe prompts via a lightweight classifier, and apply a "safe" model only to such prompts. In particular, we explore the design of the safety detector in more detail, investigating the use of different classifier architectures and prompting techniques. Interestingly, we find that the final hidden state for the last token is enough to provide robust performance, minimizing false positives on benign data while performing well on malicious prompt detection. Additionally, we show that classifiers trained on the representations from different model layers perform comparably on the latest model layers, indicating that safety representation is present in the LLMs' hidden states at most model stages. Our work is a step towards efficient, representation-based safety mechanisms for LLMs.
Privacy Attacks on Image AutoRegressive Models
Feb 04, 2025



Image autoregressive (IAR) models have surpassed diffusion models (DMs) in both image quality (FID: 1.48 vs. 1.58) and generation speed. However, their privacy risks remain largely unexplored. To address this, we conduct a comprehensive privacy analysis comparing IARs to DMs. We develop a novel membership inference attack (MIA) that achieves a significantly higher success rate in detecting training images (TPR@FPR=1%: 86.38% for IARs vs. 4.91% for DMs). Using this MIA, we perform dataset inference (DI) and find that IARs require as few as six samples to detect dataset membership, compared to 200 for DMs, indicating higher information leakage. Additionally, we extract hundreds of training images from an IAR (e.g., 698 from VAR-d30). Our findings highlight a fundamental privacy-utility trade-off: while IARs excel in generation quality and speed, they are significantly more vulnerable to privacy attacks. This suggests that incorporating techniques from DMs, such as per-token probability modeling using diffusion, could help mitigate IARs' privacy risks. Our code is available at https://github.com/sprintml/privacy_attacks_against_iars.
CDI: Copyrighted Data Identification in Diffusion Models
Nov 19, 2024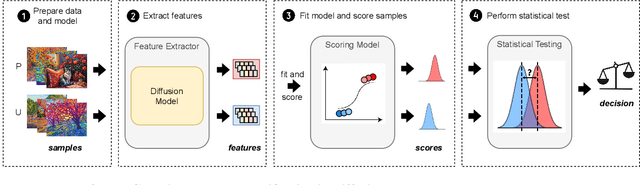

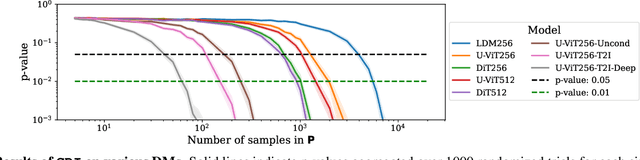
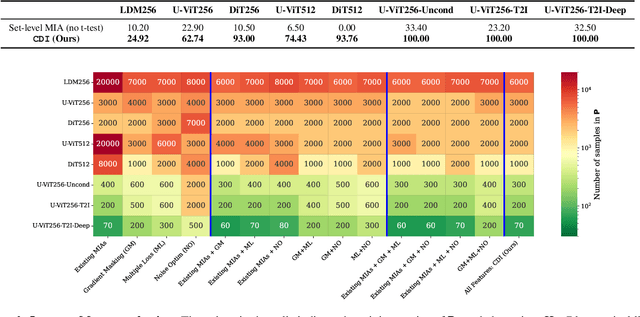
Diffusion Models (DMs) benefit from large and diverse datasets for their training. Since this data is often scraped from the Internet without permission from the data owners, this raises concerns about copyright and intellectual property protections. While (illicit) use of data is easily detected for training samples perfectly re-created by a DM at inference time, it is much harder for data owners to verify if their data was used for training when the outputs from the suspect DM are not close replicas. Conceptually, membership inference attacks (MIAs), which detect if a given data point was used during training, present themselves as a suitable tool to address this challenge. However, we demonstrate that existing MIAs are not strong enough to reliably determine the membership of individual images in large, state-of-the-art DMs. To overcome this limitation, we propose CDI, a framework for data owners to identify whether their dataset was used to train a given DM. CDI relies on dataset inference techniques, i.e., instead of using the membership signal from a single data point, CDI leverages the fact that most data owners, such as providers of stock photography, visual media companies, or even individual artists, own datasets with multiple publicly exposed data points which might all be included in the training of a given DM. By selectively aggregating signals from existing MIAs and using new handcrafted methods to extract features for these datasets, feeding them to a scoring model, and applying rigorous statistical testing, CDI allows data owners with as little as 70 data points to identify with a confidence of more than 99% whether their data was used to train a given DM. Thereby, CDI represents a valuable tool for data owners to claim illegitimate use of their copyrighted data.
Mediffusion: Joint Diffusion for Self-Explainable Semi-Supervised Classification and Medical Image Generation
Nov 12, 2024We introduce Mediffusion -- a new method for semi-supervised learning with explainable classification based on a joint diffusion model. The medical imaging domain faces unique challenges due to scarce data labelling -- insufficient for standard training, and critical nature of the applications that require high performance, confidence, and explainability of the models. In this work, we propose to tackle those challenges with a single model that combines standard classification with a diffusion-based generative task in a single shared parametrisation. By sharing representations, our model effectively learns from both labeled and unlabeled data while at the same time providing accurate explanations through counterfactual examples. In our experiments, we show that our Mediffusion achieves results comparable to recent semi-supervised methods while providing more reliable and precise explanations.
Benchmarking Robust Self-Supervised Learning Across Diverse Downstream Tasks
Jul 18, 2024



Large-scale vision models have become integral in many applications due to their unprecedented performance and versatility across downstream tasks. However, the robustness of these foundation models has primarily been explored for a single task, namely image classification. The vulnerability of other common vision tasks, such as semantic segmentation and depth estimation, remains largely unknown. We present a comprehensive empirical evaluation of the adversarial robustness of self-supervised vision encoders across multiple downstream tasks. Our attacks operate in the encoder embedding space and at the downstream task output level. In both cases, current state-of-the-art adversarial fine-tuning techniques tested only for classification significantly degrade clean and robust performance on other tasks. Since the purpose of a foundation model is to cater to multiple applications at once, our findings reveal the need to enhance encoder robustness more broadly. Our code is available at ${github.com/layer6ai-labs/ssl-robustness}$.