 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Diffusion models in Continual Learning
Nov 12, 2024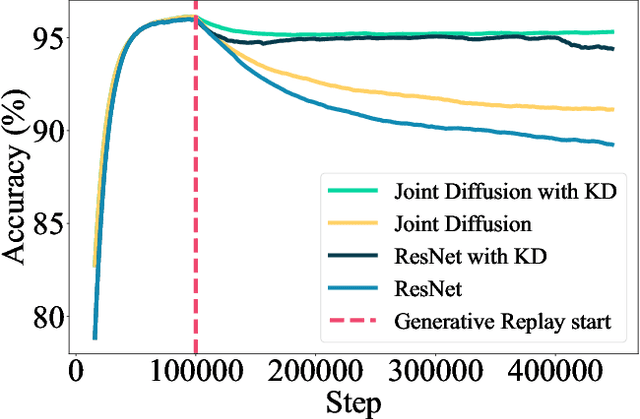
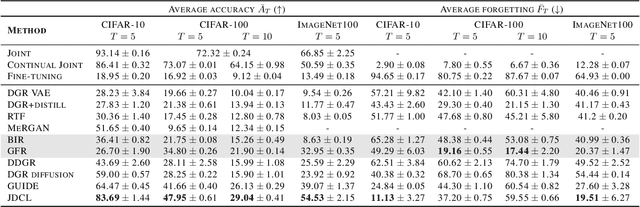
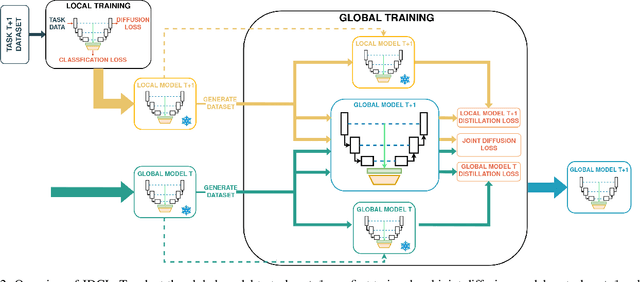
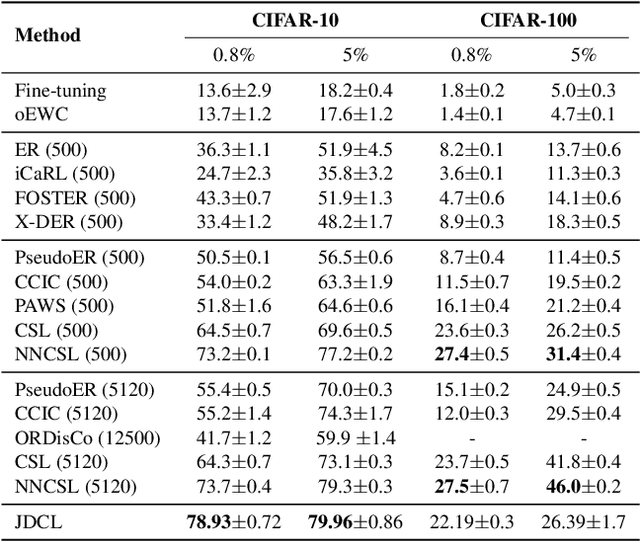
In this work, we introduce JDCL - a new method for continual learning with generative rehearsal based on joint diffusion models. Neural networks suffer from catastrophic forgetting defined as abrupt loss in the model's performance when retrained with additional data coming from a different distribution. Generative-replay-based continual learning methods try to mitigate this issue by retraining a model with a combination of new and rehearsal data sampled from a generative model. In this work, we propose to extend this idea by combining a continually trained classifier with a diffusion-based generative model into a single - jointly optimized neural network. We show that such shared parametrization, combined with the knowledge distillation technique allows for stable adaptation to new tasks without catastrophic forgetting. We evaluate our approach on several benchmarks, where it outperforms recent state-of-the-art generative replay techniques. Additionally, we extend our method to the semi-supervised continual learning setup, where it outperforms competing buffer-based replay techniques, and evaluate, in a self-supervised manner, the quality of trained representations.
Mediffusion: Joint Diffusion for Self-Explainable Semi-Supervised Classification and Medical Image Generation
Nov 12, 2024We introduce Mediffusion -- a new method for semi-supervised learning with explainable classification based on a joint diffusion model. The medical imaging domain faces unique challenges due to scarce data labelling -- insufficient for standard training, and critical nature of the applications that require high performance, confidence, and explainability of the models. In this work, we propose to tackle those challenges with a single model that combines standard classification with a diffusion-based generative task in a single shared parametrisation. By sharing representations, our model effectively learns from both labeled and unlabeled data while at the same time providing accurate explanations through counterfactual examples. In our experiments, we show that our Mediffusion achieves results comparable to recent semi-supervised methods while providing more reliable and precise explanations.
Symbotunes: unified hub for symbolic music generative models
Oct 27, 2024Implementations of popular symbolic music generative models often differ significantly in terms of the libraries utilized and overall project structure. Therefore, directly comparing the methods or becoming acquainted with them may present challenges. To mitigate this issue we introduce Symbotunes, an open-source unified hub for symbolic music generative models. Symbotunes contains modern Python implementations of well-known methods for symbolic music generation, as well as a unified pipeline for generating and training.