 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Models Help Us Create Better Models? Evaluating LLMs as Data Scientists
Oct 30, 2024We present a benchmark for large language models designed to tackle one of the most knowledge-intensive tasks in data science: writing feature engineering code, which requires domain knowledge in addition to a deep understanding of the underlying problem and data structure. The model is provided with a dataset description in a prompt and asked to generate code transforming it. The evaluation score is derived from the improvement achieved by an XGBoost model fit on the modified dataset compared to the original data. By an extensive evaluation of state-of-the-art models and comparison to well-established benchmarks, we demonstrate that the FeatEng of our proposal can cheaply and efficiently assess the broad capabilities of LLMs, in contrast to the existing methods.
Towards More Realistic Membership Inference Attacks on Large Diffusion Models
Jun 22, 2023Generative diffusion models, including Stable Diffusion and Midjourney, can generate visually appealing, diverse, and high-resolution images for various applications. These models are trained on billions of internet-sourced images, raising significant concerns about the potential unauthorized use of copyright-protected images. In this paper, we examine whether it is possible to determine if a specific image was used in the training set, a problem known in the cybersecurity community and referred to as a membership inference attack. Our focus is on Stable Diffusion, and we address the challenge of designing a fair evaluation framework to answer this membership question. We propose a methodology to establish a fair evaluation setup and apply it to Stable Diffusion, enabling potential extensions to other generative models. Utilizing this evaluation setup, we execute membership attacks (both known and newly introduced). Our research reveals that previously proposed evaluation setups do not provide a full understanding of the effectiveness of membership inference attacks. We conclude that the membership inference attack remains a significant challenge for large diffusion models (often deployed as black-box systems), indicating that related privacy and copyright issues will persist in the foreseeable future.
Continual Learning with Guarantees via Weight Interval Constraints
Jun 16, 2022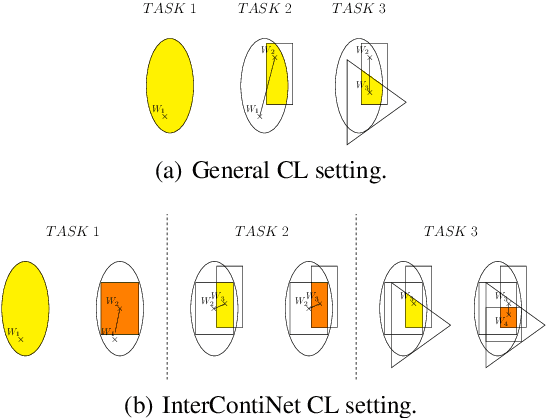



We introduce a new training paradigm that enforces interval constraints on neural network parameter space to control forgetting. Contemporary Continual Learning (CL) methods focus on training neural networks efficiently from a stream of data, while reducing the negative impact of catastrophic forgetting, yet they do not provide any firm guarantees that network performance will not deteriorate uncontrollably over time. In this work, we show how to put bounds on forgetting by reformulating continual learning of a model as a continual contraction of its parameter space. To that end, we propose Hyperrectangle Training, a new training methodology where each task is represented by a hyperrectangle in the parameter space, fully contained in the hyperrectangles of the previous tasks. This formulation reduces the NP-hard CL problem back to polynomial time while providing full resilience against forgetting. We validate our claim by developing InterContiNet (Interval Continual Learning) algorithm which leverages interval arithmetic to effectively model parameter regions as hyperrectangles. Through experimental results, we show that our approach performs well in a continual learning setup without storing data from previous tasks.
Adversarial Examples Detection and Analysis with Layer-wise Autoencoders
Jun 17, 2020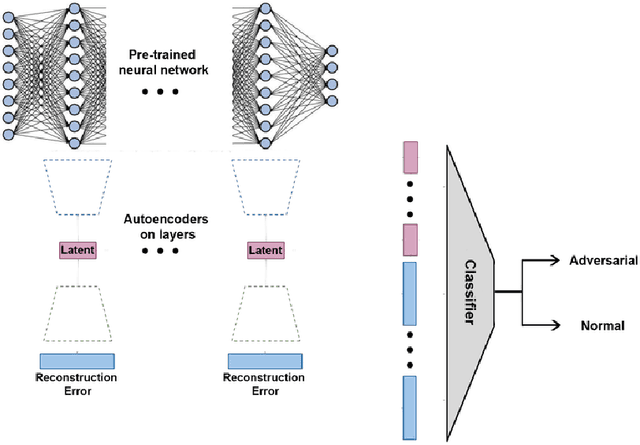



We present a mechanism for detecting adversarial examples based on data representations taken from the hidden layers of the target network. For this purpose, we train individual autoencoders at intermediate layers of the target network. This allows us to describe the manifold of true data and, in consequence, decide whether a given example has the same characteristics as true data. It also gives us insight into the behavior of adversarial examples and their flow through the layers of a deep neural network. Experimental results show that our method outperforms the state of the art in supervised and unsupervised settings.
Fast and Stable Interval Bounds Propagation for Training Verifiably Robust Models
Jun 03, 2019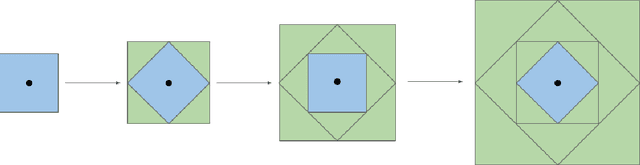



We present an efficient technique, which allows to train classification networks which are verifiably robust against norm-bounded adversarial attacks. This framework is built upon the work of Gowal et al., who applies the interval arithmetic to bound the activations at each layer and keeps the prediction invariant to the input perturbation. While that method is faster than competitive approaches, it requires careful tuning of hyper-parameters and a large number of epochs to converge. To speed up and stabilize training, we supply the cost function with an additional term, which encourages the model to keep the interval bounds at hidden layers small. Experimental results demonstrate that we can achieve comparable (or even better) results using a smaller number of training iterations, in a more stable fashion. Moreover, the proposed model is not so sensitive to the exact specification of the training process, which makes it easier to use by practitioners.