 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Model Language
Oct 14, 2025Linguistic commentary on LLMs, heavily influenced by the theoretical frameworks of de Saussure and Chomsky, is often speculative and unproductive. Critics challenge whether LLMs can legitimately model language, citing the need for "deep structure" or "grounding" to achieve an idealized linguistic "competence." We argue for a radical shift in perspective towards the empiricist principles of Witold Ma\'nczak, a prominent general and historical linguist. He defines language not as a "system of signs" or a "computational system of the brain" but as the totality of all that is said and written. Above all, he identifies frequency of use of particular language elements as language's primary governing principle. Using his framework, we challenge prior critiques of LLMs and provide a constructive guide for designing, evaluating, and interpreting language models.
Unchecked and Overlooked: Addressing the Checkbox Blind Spot in Large Language Models with CheckboxQA
Apr 15, 2025



Checkboxes are critical in real-world document processing where the presence or absence of ticks directly informs data extraction and decision-making processes. Yet, despite the strong performance of Large Vision and Language Models across a wide range of tasks, they struggle with interpreting checkable content. This challenge becomes particularly pressing in industries where a single overlooked checkbox may lead to costly regulatory or contractual oversights. To address this gap, we introduce the CheckboxQA dataset, a targeted resource designed to evaluate and improve model performance on checkbox-related tasks. It reveals the limitations of current models and serves as a valuable tool for advancing document comprehension systems, with significant implications for applications in sectors such as legal tech and finance. The dataset is publicly available at: https://github.com/Snowflake-Labs/CheckboxQA
Query and Conquer: Execution-Guided SQL Generation
Mar 31, 2025We propose a novel approach for generating complex outputs that significantly improves accuracy in text-to-SQL tasks. Our method leverages execution results to select the most semantically consistent query from multiple candidates, enabling smaller, cost-effective models to surpass computationally intensive reasoning methods such as o1, o3-mini, and DeepSeek R1 while reducing inference cost by as much as 30 times. It integrates effortlessly with existing models, offering a practical and scalable pathway to state-of-the-art SQL generation.
In Case You Missed It: ARC 'Challenge' Is Not That Challenging
Dec 23, 2024ARC Challenge appears more difficult than ARC Easy for modern LLMs primarily due to an evaluation setup that prevents direct comparison of answer choices rather than inherent complexity. Although some researchers have quietly shifted to a more appropriate scheme over the last year, the implications of this change have yet to be widely acknowledged. We highlight this overlooked shift, show how similar evaluation practices falsely imply reasoning deficits in other benchmarks, and demonstrate that fairer methods dramatically reduce performance gaps (e.g. on SIQA) and even yield superhuman results (OpenBookQA). In doing so, we reveal how evaluation shapes perceived difficulty and offer guidelines to ensure that multiple-choice evaluations accurately reflect actual model capabilities.
Tackling prediction tasks in relational databases with LLMs
Nov 18, 2024



Though large language models (LLMs) have demonstrated exceptional performance across numerous problems, their application to predictive tasks in relational databases remains largely unexplored. In this work, we address the notion that LLMs cannot yield satisfactory results on relational databases due to their interconnected tables, complex relationships, and heterogeneous data types. Using the recently introduced RelBench benchmark, we demonstrate that even a straightforward application of LLMs achieves competitive performance on these tasks. These findings establish LLMs as a promising new baseline for ML on relational databases and encourage further research in this direction.
Can Models Help Us Create Better Models? Evaluating LLMs as Data Scientists
Oct 30, 2024We present a benchmark for large language models designed to tackle one of the most knowledge-intensive tasks in data science: writing feature engineering code, which requires domain knowledge in addition to a deep understanding of the underlying problem and data structure. The model is provided with a dataset description in a prompt and asked to generate code transforming it. The evaluation score is derived from the improvement achieved by an XGBoost model fit on the modified dataset compared to the original data. By an extensive evaluation of state-of-the-art models and comparison to well-established benchmarks, we demonstrate that the FeatEng of our proposal can cheaply and efficiently assess the broad capabilities of LLMs, in contrast to the existing methods.
Arctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
Notes on Applicability of GPT-4 to Document Understanding
May 28, 2024We perform a missing, reproducible evaluation of all publicly available GPT-4 family models concerning the Document Understanding field, where it is frequently required to comprehend text spacial arrangement and visual clues in addition to textual semantics. Benchmark results indicate that though it is hard to achieve satisfactory results with text-only models, GPT-4 Vision Turbo performs well when one provides both text recognized by an external OCR engine and document images on the input. Evaluation is followed by analyses that suggest possible contamination of textual GPT-4 models and indicate the significant performance drop for lengthy documents.
Document Understanding Dataset and Evaluation (DUDE)
May 15, 2023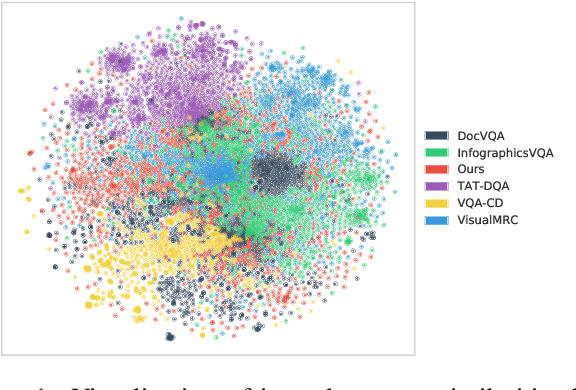
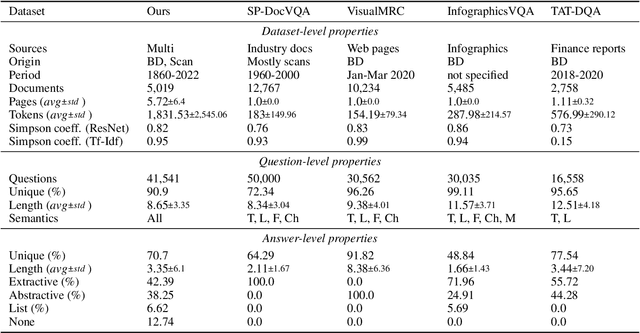
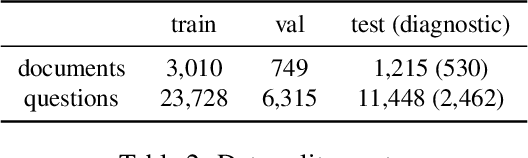
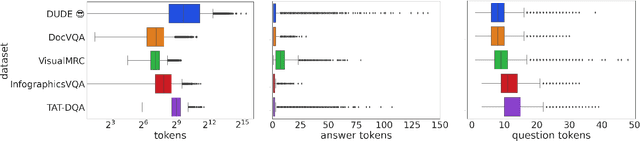
We call on the Document AI (DocAI) community to reevaluate current methodologies and embrace the challenge of creating more practically-oriented benchmarks. Document Understanding Dataset and Evaluation (DUDE) seeks to remediate the halted research progress in understanding visually-rich documents (VRDs). We present a new dataset with novelties related to types of questions, answers, and document layouts based on multi-industry, multi-domain, and multi-page VRDs of various origins, and dates. Moreover, we are pushing the boundaries of current methods by creating multi-task and multi-domain evaluation setups that more accurately simulate real-world situations where powerful generalization and adaptation under low-resource settings are desired. DUDE aims to set a new standard as a more practical, long-standing benchmark for the community, and we hope that it will lead to future extensions and contributions that address real-world challenges. Finally, our work illustrates the importance of finding more efficient ways to model language, images, and layout in DocAI.
STable: Table Generation Framework for Encoder-Decoder Models
Jun 08, 2022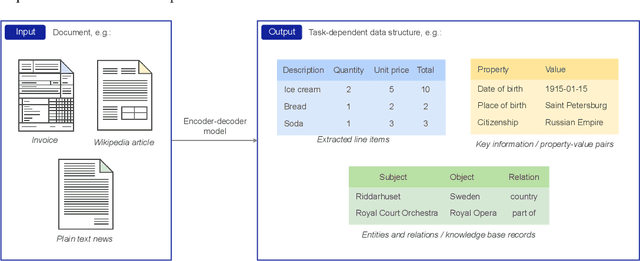
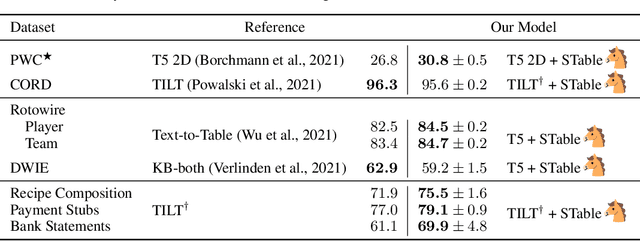

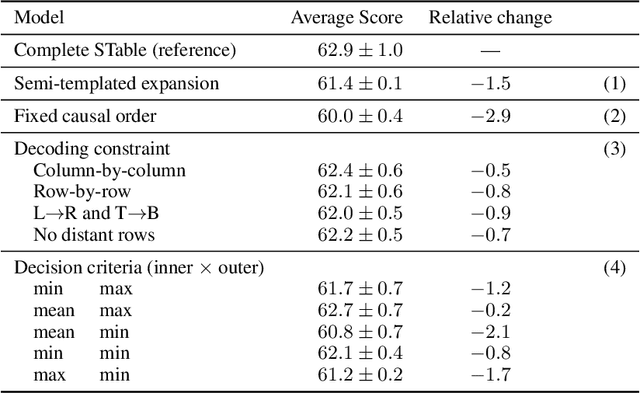
The output structure of database-like tables, consisting of values structured in horizontal rows and vertical columns identifiable by name, can cover a wide range of NLP tasks. Following this constatation, we propose a framework for text-to-table neural models applicable to problems such as extraction of line items, joint entity and relation extraction, or knowledge base population. The permutation-based decoder of our proposal is a generalized sequential method that comprehends information from all cells in the table. The training maximizes the expected log-likelihood for a table's content across all random permutations of the factorization order. During the content inference, we exploit the model's ability to generate cells in any order by searching over possible orderings to maximize the model's confidence and avoid substantial error accumulation, which other sequential models are prone to. Experiments demonstrate a high practical value of the framework, which establishes state-of-the-art results on several challenging datasets, outperforming previous solutions by up to 15%.