 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTable: Table Generation Framework for Encoder-Decoder Models
Jun 08, 2022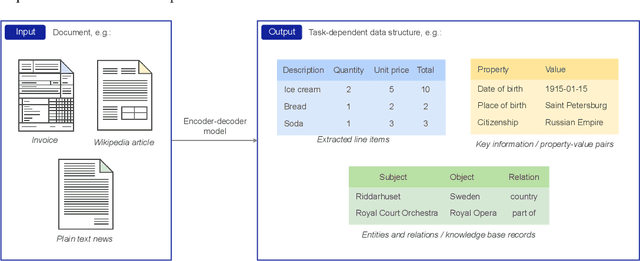
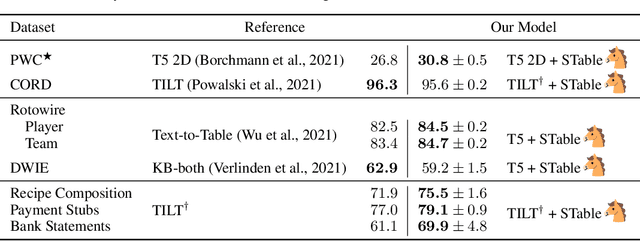

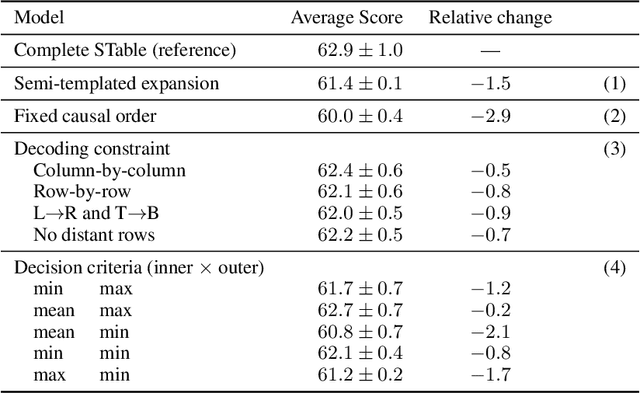
The output structure of database-like tables, consisting of values structured in horizontal rows and vertical columns identifiable by name, can cover a wide range of NLP tasks. Following this constatation, we propose a framework for text-to-table neural models applicable to problems such as extraction of line items, joint entity and relation extraction, or knowledge base population. The permutation-based decoder of our proposal is a generalized sequential method that comprehends information from all cells in the table. The training maximizes the expected log-likelihood for a table's content across all random permutations of the factorization order. During the content inference, we exploit the model's ability to generate cells in any order by searching over possible orderings to maximize the model's confidence and avoid substantial error accumulation, which other sequential models are prone to. Experiments demonstrate a high practical value of the framework, which establishes state-of-the-art results on several challenging datasets, outperforming previous solutions by up to 15%.
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Mar 02, 2021We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
From Dataset Recycling to Multi-Property Extraction and Beyond
Nov 06, 2020



This paper investigates various Transformer architectures on the WikiReading Information Extraction and Machine Reading Comprehension dataset. The proposed dual-source model outperforms the current state-of-the-art by a large margin. Next, we introduce WikiReading Recycled-a newly developed public dataset and the task of multiple property extraction. It uses the same data as WikiReading but does not inherit its predecessor's identified disadvantages. In addition, we provide a human-annotated test set with diagnostic subsets for a detailed analysis of model performance.
On the Multi-Property Extraction and Beyond
Jun 15, 2020


In this paper, we investigate the Dual-source Transformer architecture on the WikiReading information extraction and machine reading comprehension dataset. The proposed model outperforms the current state-of-the-art by a large margin. Next, we introduce WikiReading Recycled - a newly developed public dataset, supporting the task of multiple property extraction. It keeps the spirit of the original WikiReading but does not inherit the identified disadvantages of its predecessor.
Fast Neural Machine Translation Implementation
Jun 07, 2018
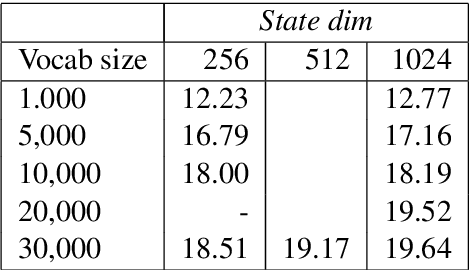
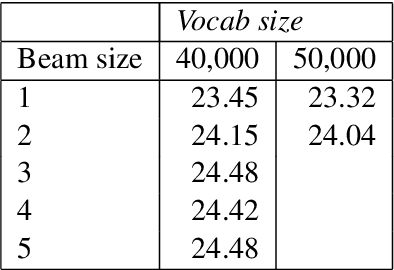
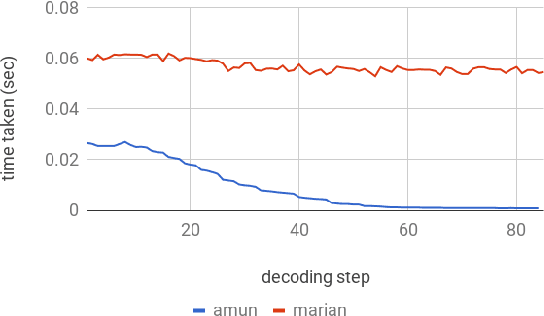
This paper describes the submissions to the efficiency track for GPUs at the Workshop for Neural Machine Translation and Generation by members of the University of Edinburgh, Adam Mickiewicz University, Tilde and University of Alicante. We focus on efficient implementation of the recurrent deep-learning model as implemented in Amun, the fast inference engine for neural machine translation. We improve the performance with an efficient mini-batching algorithm, and by fusing the softmax operation with the k-best extraction algorithm. Submissions using Amun were first, second and third fastest in the GPU efficiency track.
Marian: Fast Neural Machine Translation in C++
Apr 04, 2018



We present Marian, an efficient and self-contained Neural Machine Translation framework with an integrated automatic differentiation engine based on dynamic computation graphs. Marian is written entirely in C++. We describe the design of the encoder-decoder framework and demonstrate that a research-friendly toolkit can achieve high training and translation speed.
Predicting Target Language CCG Supertags Improves Neural Machine Translation
Jul 18, 2017
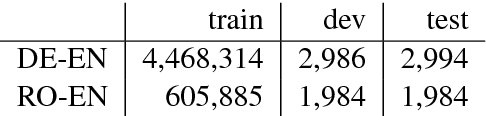
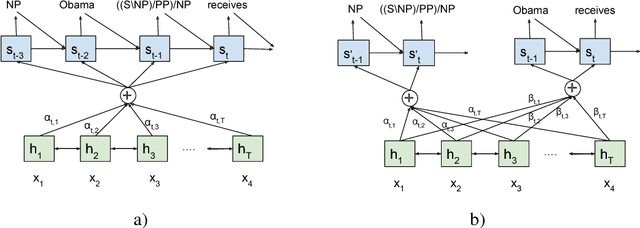
Neural machine translation (NMT) models are able to partially learn syntactic information from sequential lexical information. Still, some complex syntactic phenomena such as prepositional phrase attachment are poorly modeled. This work aims to answer two questions: 1) Does explicitly modeling target language syntax help NMT? 2) Is tight integration of words and syntax better than multitask training? We introduce syntactic information in the form of CCG supertags in the decoder, by interleaving the target supertags with the word sequence. Our results on WMT data show that explicitly modeling target-syntax improves machine translation quality for German->English, a high-resource pair, and for Romanian->English, a low-resource pair and also several syntactic phenomena including prepositional phrase attachment. Furthermore, a tight coupling of words and syntax improves translation quality more than multitask training. By combining target-syntax with adding source-side dependency labels in the embedding layer, we obtain a total improvement of 0.9 BLEU for German->English and 1.2 BLEU for Romanian->English.
Is Neural Machine Translation Ready for Deployment? A Case Study on 30 Translation Directions
Nov 30, 2016



In this paper we provide the largest published comparison of translation quality for phrase-based SMT and neural machine translation across 30 translation directions. For ten directions we also include hierarchical phrase-based MT. Experiments are performed for the recently published United Nations Parallel Corpus v1.0 and its large six-way sentence-aligned subcorpus. In the second part of the paper we investigate aspects of translation speed, introducing AmuNMT, our efficient neural machine translation decoder. We demonstrate that current neural machine translation could already be used for in-production systems when comparing words-per-second ratios.
The AMU-UEDIN Submission to the WMT16 News Translation Task: Attention-based NMT Models as Feature Functions in Phrase-based SMT
Jun 23, 2016



This paper describes the AMU-UEDIN submissions to the WMT 2016 shared task on news translation. We explore methods of decode-time integration of attention-based neural translation models with phrase-based statistical machine translation. Efficient batch-algorithms for GPU-querying are proposed and implemented. For English-Russian, our system stays behind the state-of-the-art pure neural models in terms of BLEU. Among restricted systems, manual evaluation places it in the first cluster tied with the pure neural model. For the Russian-English task, our submission achieves the top BLEU result, outperforming the best pure neural system by 1.1 BLEU points and our own phrase-based baseline by 1.6 BLEU. After manual evaluation, this system is the best restricted system in its own cluster. In follow-up experiments we improve results by additional 0.8 BLEU.