Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Multi-Property Extraction and Beyond
Paper and Code

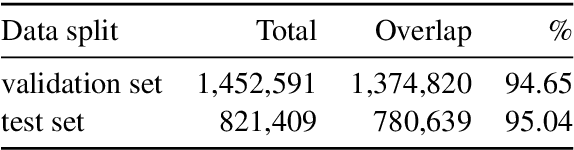


In this paper, we investigate the Dual-source Transformer architecture on the WikiReading information extraction and machine reading comprehension dataset. The proposed model outperforms the current state-of-the-art by a large margin. Next, we introduce WikiReading Recycled - a newly developed public dataset, supporting the task of multiple property extraction. It keeps the spirit of the original WikiReading but does not inherit the identified disadvantages of its predecessor.
* 5 pages
View paper on