 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
A Wiener process perspective on local intrinsic dimension estimation methods
Jun 24, 2024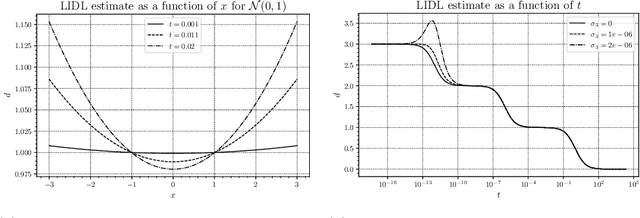
Local intrinsic dimension (LID) estimation methods have received a lot of attention in recent years thanks to the progress in deep neural networks and generative modeling. In opposition to old non-parametric methods, new methods use generative models to approximate diffused dataset density and scale the methods to high-dimensional datasets like images. In this paper, we investigate the recent state-of-the-art parametric LID estimation methods from the perspective of the Wiener process. We explore how these methods behave when their assumptions are not met. We give an extended mathematical description of those methods and their error as a function of the probability density of the data.
LIDL: Local Intrinsic Dimension Estimation Using Approximate Likelihood
Jun 29, 2022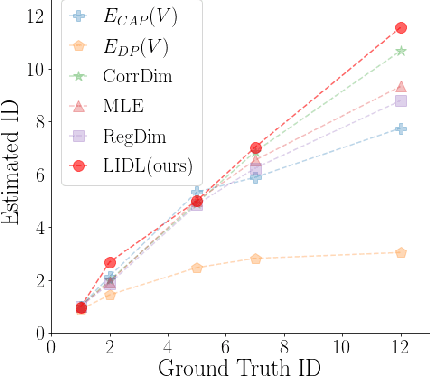

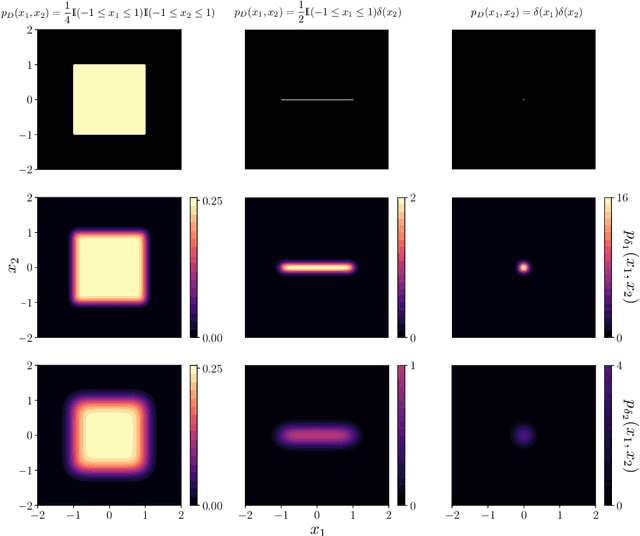
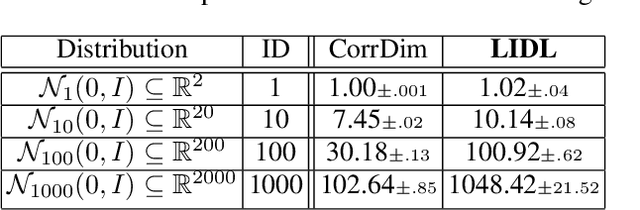
Most of the existing methods for estimating the local intrinsic dimension of a data distribution do not scale well to high-dimensional data. Many of them rely on a non-parametric nearest neighbors approach which suffers from the curse of dimensionality. We attempt to address that challenge by proposing a novel approach to the problem: Local Intrinsic Dimension estimation using approximate Likelihood (LIDL). Our method relies on an arbitrary density estimation method as its subroutine and hence tries to sidestep the dimensionality challenge by making use of the recent progress in parametric neural methods for likelihood estimation. We carefully investigate the empirical properties of the proposed method, compare them with our theoretical predictions, and show that LIDL yields competitive results on the standard benchmarks for this problem and that it scales to thousands of dimensions. What is more, we anticipate this approach to improve further with the continuing advances in the density estimation literature.
STable: Table Generation Framework for Encoder-Decoder Models
Jun 08, 2022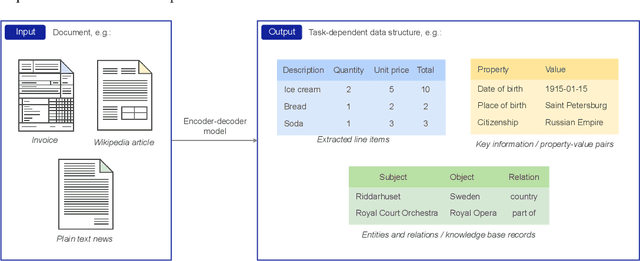
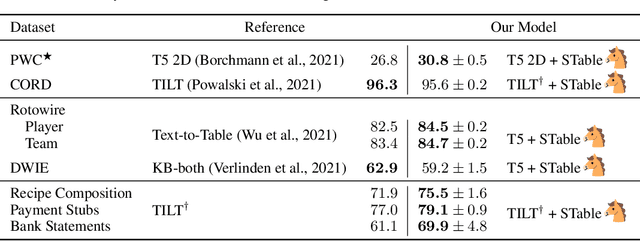

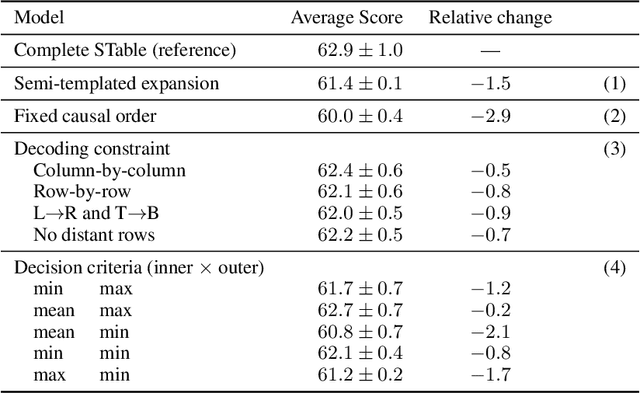
The output structure of database-like tables, consisting of values structured in horizontal rows and vertical columns identifiable by name, can cover a wide range of NLP tasks. Following this constatation, we propose a framework for text-to-table neural models applicable to problems such as extraction of line items, joint entity and relation extraction, or knowledge base population. The permutation-based decoder of our proposal is a generalized sequential method that comprehends information from all cells in the table. The training maximizes the expected log-likelihood for a table's content across all random permutations of the factorization order. During the content inference, we exploit the model's ability to generate cells in any order by searching over possible orderings to maximize the model's confidence and avoid substantial error accumulation, which other sequential models are prone to. Experiments demonstrate a high practical value of the framework, which establishes state-of-the-art results on several challenging datasets, outperforming previous solutions by up to 15%.
LAMBERT: Layout-Aware language Modeling using BERT for information extraction
Mar 06, 2020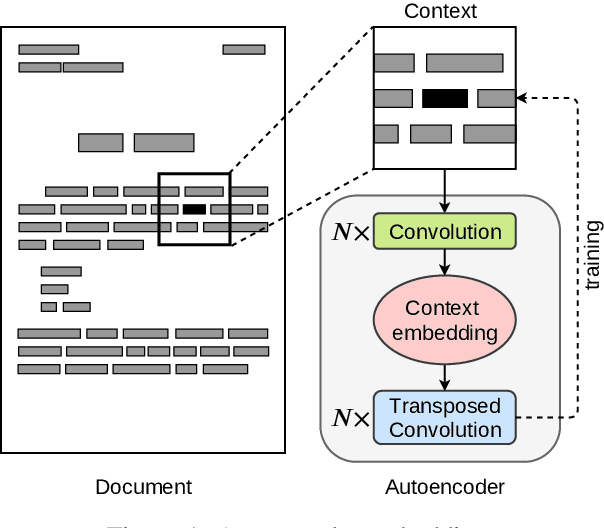
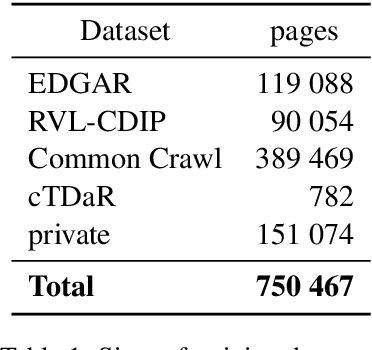
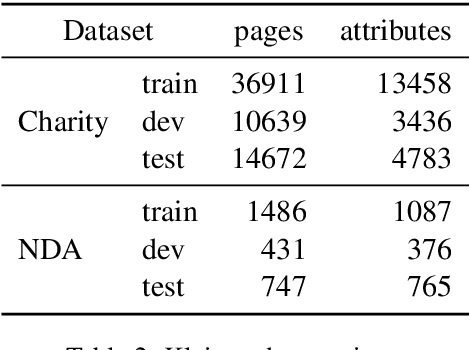
In this paper we introduce a novel approach to the problem of understanding documents where the local semantics is influenced by non-trivial layout. Namely, we modify the Transformer architecture in a way that allows it to use the graphical features defined by the layout, without the need to re-learn the language semantics from scratch, thanks to starting the training process from a model pretrained on classical language modeling tasks.