 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
LAMBERT: Layout-Aware language Modeling using BERT for information extraction
Mar 06, 2020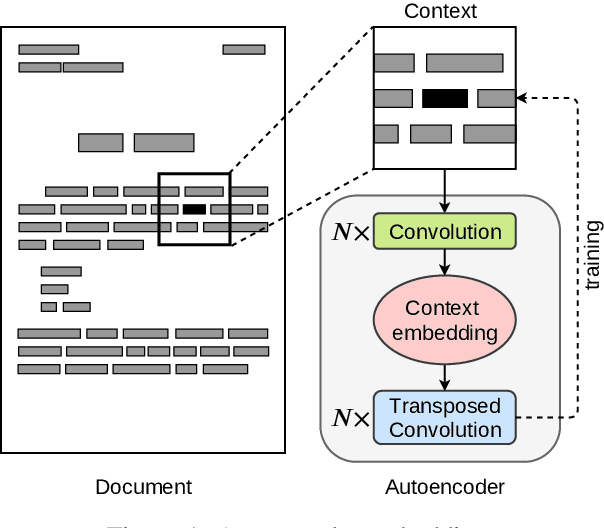
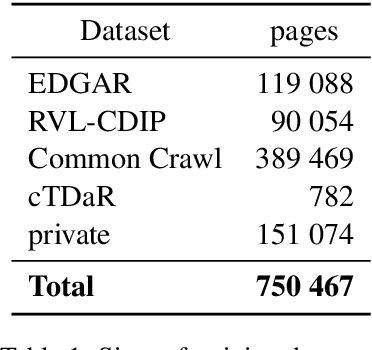
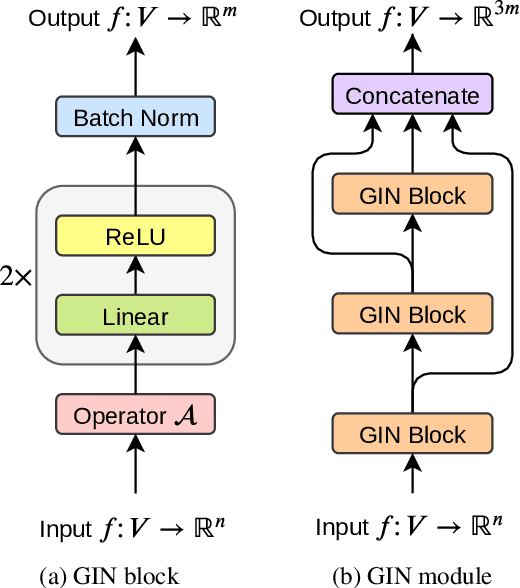
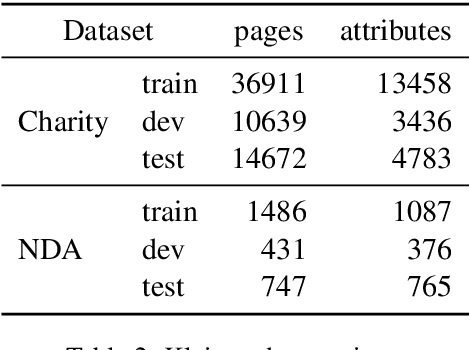
In this paper we introduce a novel approach to the problem of understanding documents where the local semantics is influenced by non-trivial layout. Namely, we modify the Transformer architecture in a way that allows it to use the graphical features defined by the layout, without the need to re-learn the language semantics from scratch, thanks to starting the training process from a model pretrained on classical language modeling tasks.