 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
Document Understanding Dataset and Evaluation (DUDE)
May 15, 2023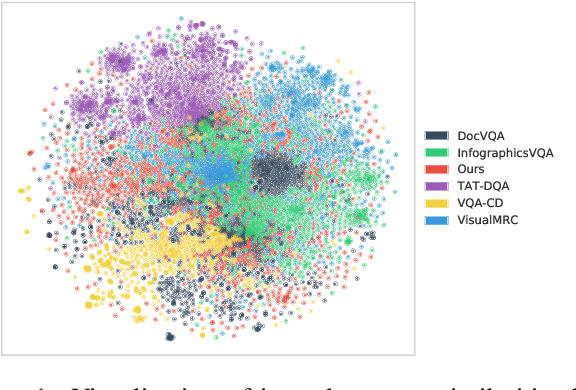
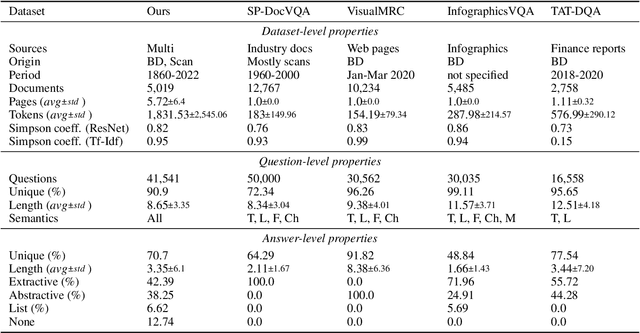
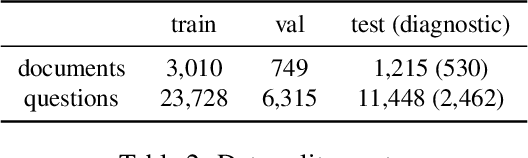
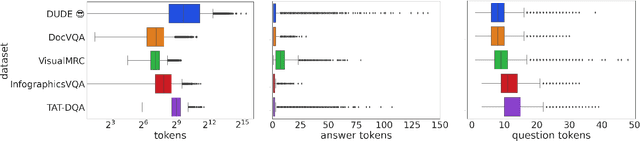
We call on the Document AI (DocAI) community to reevaluate current methodologies and embrace the challenge of creating more practically-oriented benchmarks. Document Understanding Dataset and Evaluation (DUDE) seeks to remediate the halted research progress in understanding visually-rich documents (VRDs). We present a new dataset with novelties related to types of questions, answers, and document layouts based on multi-industry, multi-domain, and multi-page VRDs of various origins, and dates. Moreover, we are pushing the boundaries of current methods by creating multi-task and multi-domain evaluation setups that more accurately simulate real-world situations where powerful generalization and adaptation under low-resource settings are desired. DUDE aims to set a new standard as a more practical, long-standing benchmark for the community, and we hope that it will lead to future extensions and contributions that address real-world challenges. Finally, our work illustrates the importance of finding more efficient ways to model language, images, and layout in DocAI.
STable: Table Generation Framework for Encoder-Decoder Models
Jun 08, 2022

The output structure of database-like tables, consisting of values structured in horizontal rows and vertical columns identifiable by name, can cover a wide range of NLP tasks. Following this constatation, we propose a framework for text-to-table neural models applicable to problems such as extraction of line items, joint entity and relation extraction, or knowledge base population. The permutation-based decoder of our proposal is a generalized sequential method that comprehends information from all cells in the table. The training maximizes the expected log-likelihood for a table's content across all random permutations of the factorization order. During the content inference, we exploit the model's ability to generate cells in any order by searching over possible orderings to maximize the model's confidence and avoid substantial error accumulation, which other sequential models are prone to. Experiments demonstrate a high practical value of the framework, which establishes state-of-the-art results on several challenging datasets, outperforming previous solutions by up to 15%.
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Mar 02, 2021We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
Dynamic Boundary Time Warping for Sub-sequence Matching with Few Examples
Oct 27, 2020
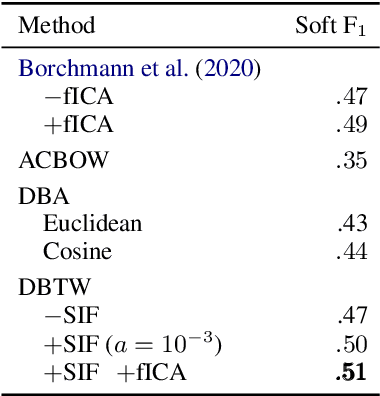
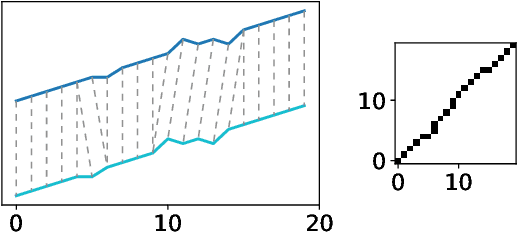

The paper presents a novel method of finding a fragment in a long temporal sequence similar to the set of shorter sequences. We are the first to propose an algorithm for such a search that does not rely on computing the average sequence from query examples. Instead, we use query examples as is, utilizing all of them simultaneously. The introduced method based on the Dynamic Time Warping (DTW) technique is suited explicitly for few-shot query-by-example retrieval tasks. We evaluate it on two different few-shot problems from the field of Natural Language Processing. The results show it either outperforms baselines and previous approaches or achieves comparable results when a low number of examples is available.
ApplicaAI at SemEval-2020 Task 11: On RoBERTa-CRF, Span CLS and Whether Self-Training Helps Them
May 16, 2020
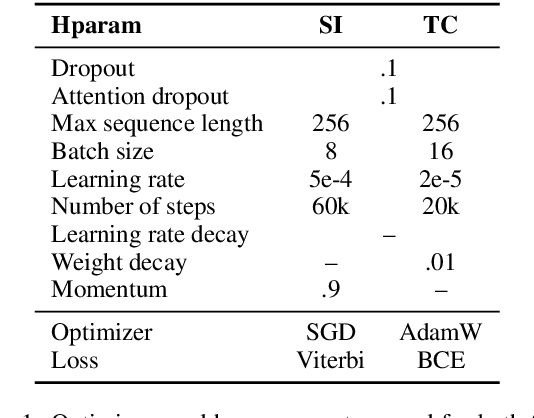

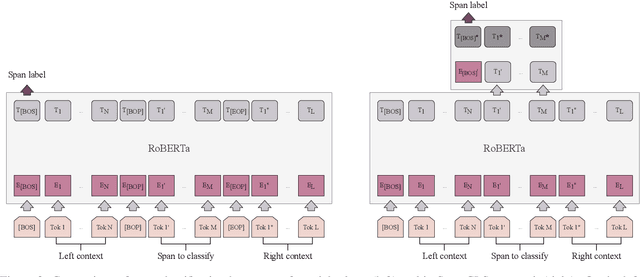
This paper presents the winning system for the propaganda Technique Classification (TC) task and the second-placed system for the propaganda Span Identification (SI) task. The purpose of TC task was to identify an applied propaganda technique given propaganda text fragment. The goal of SI task was to find specific text fragments which contain at least one propaganda technique. Both of the developed solutions used semi-supervised learning technique of self-training. Interestingly, although CRF is barely used with transformer-based language models, the SI task was approached with RoBERTa-CRF architecture. An ensemble of RoBERTa-based models was proposed for the TC task, with one of them making use of Span CLS layers we introduce in the present paper. In addition to describing the submitted systems, an impact of architectural decisions and training schemes is investigated along with remarks regarding training models of the same or better quality with lower computational budget. Finally, the results of error analysis are presented.
Searching for Legal Clauses by Analogy. Few-shot Semantic Retrieval Shared Task
Nov 10, 2019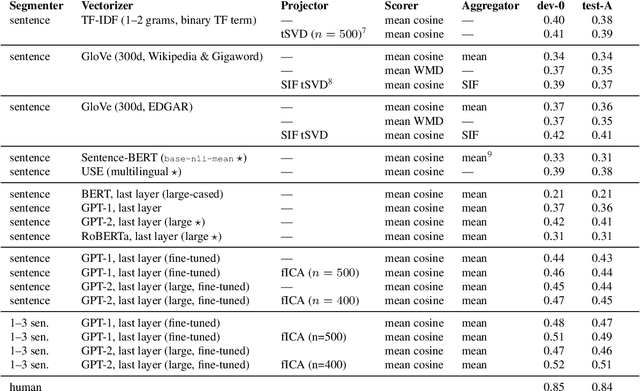
We introduce a novel shared task for semantic retrieval from legal texts, where one is expected to perform a so-called contract discovery -- extract specified legal clauses from documents given a few examples of similar clauses from other legal acts. The task differs substantially from conventional NLI and legal information extraction shared tasks. Its specification is followed with evaluation of multiple k-NN based solutions within the unified framework proposed for this branch of methods. It is shown that state-of-the-art pre-trained encoders fail to provide satisfactory results on the task proposed, whereas Language Model based solutions perform well, especially when unsupervised fine-tuning is applied. In addition to the ablation studies, the questions regarding relevant text fragments detection accuracy depending on number of examples available were addressed. In addition to dataset and reference results, legal-specialized LMs were made publicly available.