 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Affect Analysis: Predicting Emotions of Image Viewers with Vision-Language Models
Jan 27, 2026Vision-language models (VLMs) show promise as tools for inferring affect from visual stimuli at scale; it is not yet clear how closely their outputs align with human affective ratings. We benchmarked nine VLMs, ranging from state-of-the-art proprietary models to open-source models, on three psycho-metrically validated affective image datasets: the International Affective Picture System, the Nencki Affective Picture System, and the Library of AI-Generated Affective Images. The models performed two tasks in the zero-shot setting: (i) top-emotion classification (selecting the strongest discrete emotion elicited by an image) and (ii) continuous prediction of human ratings on 1-7/9 Likert scales for discrete emotion categories and affective dimensions. We also evaluated the impact of rater-conditioned prompting on the LAI-GAI dataset using de-identified participant metadata. The results show good performance in discrete emotion classification, with accuracies typically ranging from 60% to 80% on six-emotion labels and from 60% to 75% on a more challenging 12-category task. The predictions of anger and surprise had the lowest accuracy in all datasets. For continuous rating prediction, models showed moderate to strong alignment with humans (r > 0.75) but also exhibited consistent biases, notably weaker performance on arousal, and a tendency to overestimate response strength. Rater-conditioned prompting resulted in only small, inconsistent changes in predictions. Overall, VLMs capture broad affective trends but lack the nuance found in validated psychological ratings, highlighting their potential and current limitations for affective computing and mental health-related applications.
Two new approaches to multiple canonical correlation analysis for repeated measures data
Oct 06, 2025In classical canonical correlation analysis (CCA), the goal is to determine the linear transformations of two random vectors into two new random variables that are most strongly correlated. Canonical variables are pairs of these new random variables, while canonical correlations are correlations between these pairs. In this paper, we propose and study two generalizations of this classical method: (1) Instead of two random vectors we study more complex data structures that appear in important applications. In these structures, there are $L$ features, each described by $p_l$ scalars, $1 \le l \le L$. We observe $n$ such objects over $T$ time points. We derive a suitable analog of the CCA for such data. Our approach relies on embeddings into Reproducing Kernel Hilbert Spaces, and covers several related data structures as well. (2) We develop an analogous approach for multidimensional random processes. In this case, the experimental units are multivariate continuous, square-integrable functions over a given interval. These functions are modeled as elements of a Hilbert space, so in this case, we define the multiple functional canonical correlation analysis, MFCCA. We justify our approaches by their application to two data sets and suitable large sample theory. We derive consistency rates for the related transformation and correlation estimators, and show that it is possible to relax two common assumptions on the compactness of the underlying cross-covariance operators and the independence of the data.
Job recommendations: benchmarking of collaborative filtering methods for classifieds
Jan 19, 2023



Classifieds provide many challenges for recommendation methods, due to the limited information regarding users and items. In this paper, we explore recommendation methods for classifieds using the example of OLX Jobs. The goal of the paper is to benchmark different recommendation methods for jobs classifieds in order to improve advertisements' conversion rate and user satisfaction. In our research, we implemented methods that are scalable and represent different approaches to recommendation, namely ALS, LightFM, Prod2Vec, RP3beta, and SLIM. We performed a laboratory comparison of methods with regard to accuracy, diversity, and scalability (memory and time consumption during training and in prediction). Online A/B tests were also carried out by sending millions of messages with recommendations to evaluate models in a real-world setting. In addition, we have published the dataset that we created for the needs of our research. To the best of our knowledge, this is the first dataset of this kind. The dataset contains 65,502,201 events performed on OLX Jobs by 3,295,942 users, who interacted with (displayed, replied to, or bookmarked) 185,395 job ads in two weeks of 2020. We demonstrate that RP3beta, SLIM, and ALS perform significantly better than Prod2Vec and LightFM when tested in a laboratory setting. Online A/B tests also demonstrated that sending messages with recommendations generated by the ALS and RP3beta models increases the number of users contacting advertisers. Additionally, RP3beta had a 20% greater impact on this metric than ALS.
Dynamic Boundary Time Warping for Sub-sequence Matching with Few Examples
Oct 27, 2020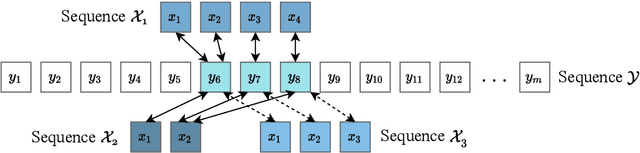
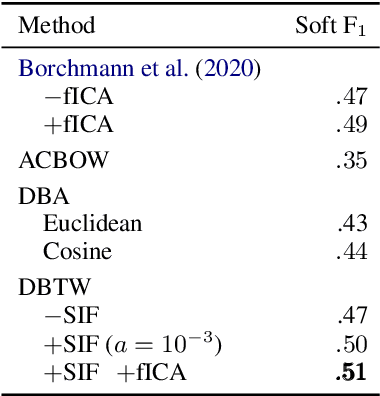
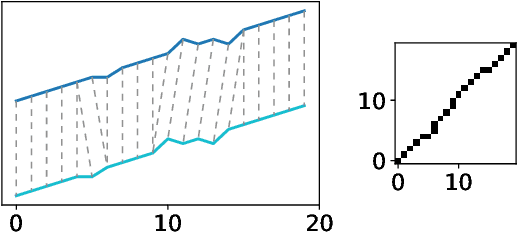

The paper presents a novel method of finding a fragment in a long temporal sequence similar to the set of shorter sequences. We are the first to propose an algorithm for such a search that does not rely on computing the average sequence from query examples. Instead, we use query examples as is, utilizing all of them simultaneously. The introduced method based on the Dynamic Time Warping (DTW) technique is suited explicitly for few-shot query-by-example retrieval tasks. We evaluate it on two different few-shot problems from the field of Natural Language Processing. The results show it either outperforms baselines and previous approaches or achieves comparable results when a low number of examples is available.