 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Use of Foundation Models for Named Entity Recognition and Lemmatization Tasks in Slavic Languages
Apr 11, 2023


This paper describes Adam Mickiewicz University's (AMU) solution for the 4th Shared Task on SlavNER. The task involves the identification, categorization, and lemmatization of named entities in Slavic languages. Our approach involved exploring the use of foundation models for these tasks. In particular, we used models based on the popular BERT and T5 model architectures. Additionally, we used external datasets to further improve the quality of our models. Our solution obtained promising results, achieving high metrics scores in both tasks. We describe our approach and the results of our experiments in detail, showing that the method is effective for NER and lemmatization in Slavic languages. Additionally, our models for lemmatization will be available at: https://huggingface.co/amu-cai.
Adam Mickiewicz University at WMT 2022: NER-Assisted and Quality-Aware Neural Machine Translation
Sep 07, 2022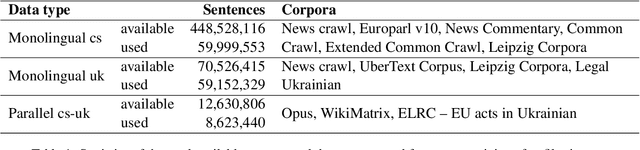
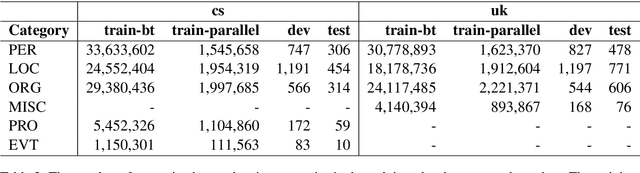
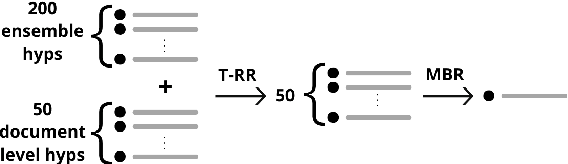
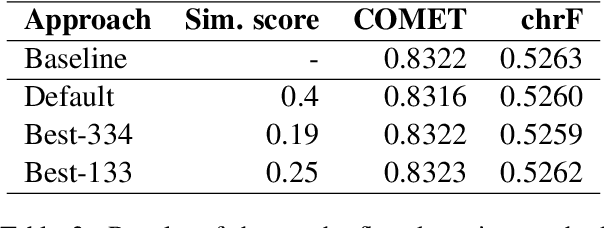
This paper presents Adam Mickiewicz University's (AMU) submissions to the constrained track of the WMT 2022 General MT Task. We participated in the Ukrainian $\leftrightarrow$ Czech translation directions. The systems are a weighted ensemble of four models based on the Transformer (big) architecture. The models use source factors to utilize the information about named entities present in the input. Each of the models in the ensemble was trained using only the data provided by the shared task organizers. A noisy back-translation technique was used to augment the training corpora. One of the models in the ensemble is a document-level model, trained on parallel and synthetic longer sequences. During the sentence-level decoding process, the ensemble generated the n-best list. The n-best list was merged with the n-best list generated by a single document-level model which translated multiple sentences at a time. Finally, existing quality estimation models and minimum Bayes risk decoding were used to rerank the n-best list so that the best hypothesis was chosen according to the COMET evaluation metric. According to the automatic evaluation results, our systems rank first in both translation directions.
STable: Table Generation Framework for Encoder-Decoder Models
Jun 08, 2022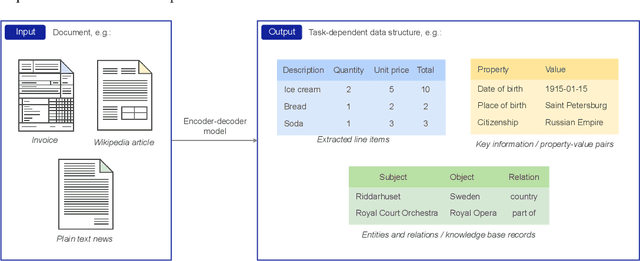
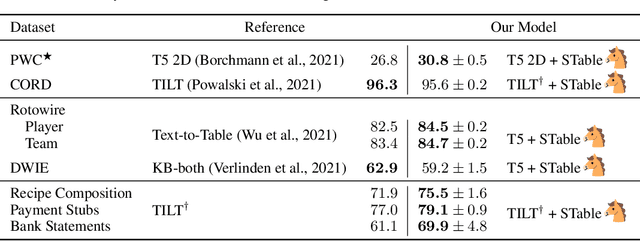

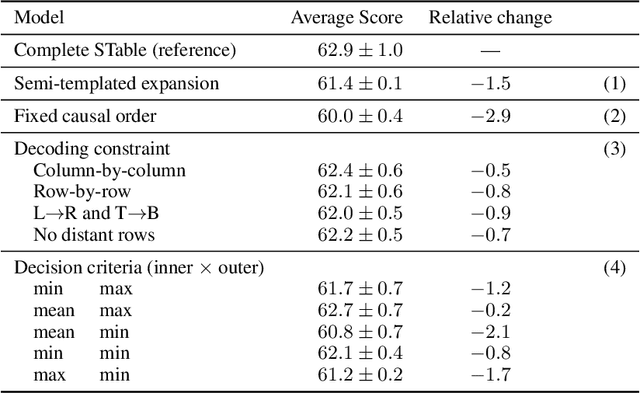
The output structure of database-like tables, consisting of values structured in horizontal rows and vertical columns identifiable by name, can cover a wide range of NLP tasks. Following this constatation, we propose a framework for text-to-table neural models applicable to problems such as extraction of line items, joint entity and relation extraction, or knowledge base population. The permutation-based decoder of our proposal is a generalized sequential method that comprehends information from all cells in the table. The training maximizes the expected log-likelihood for a table's content across all random permutations of the factorization order. During the content inference, we exploit the model's ability to generate cells in any order by searching over possible orderings to maximize the model's confidence and avoid substantial error accumulation, which other sequential models are prone to. Experiments demonstrate a high practical value of the framework, which establishes state-of-the-art results on several challenging datasets, outperforming previous solutions by up to 15%.
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Mar 02, 2021We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
Searching for Legal Clauses by Analogy. Few-shot Semantic Retrieval Shared Task
Nov 10, 2019
We introduce a novel shared task for semantic retrieval from legal texts, where one is expected to perform a so-called contract discovery -- extract specified legal clauses from documents given a few examples of similar clauses from other legal acts. The task differs substantially from conventional NLI and legal information extraction shared tasks. Its specification is followed with evaluation of multiple k-NN based solutions within the unified framework proposed for this branch of methods. It is shown that state-of-the-art pre-trained encoders fail to provide satisfactory results on the task proposed, whereas Language Model based solutions perform well, especially when unsupervised fine-tuning is applied. In addition to the ablation studies, the questions regarding relevant text fragments detection accuracy depending on number of examples available were addressed. In addition to dataset and reference results, legal-specialized LMs were made publicly available.