 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Wiener process perspective on local intrinsic dimension estimation methods
Jun 24, 2024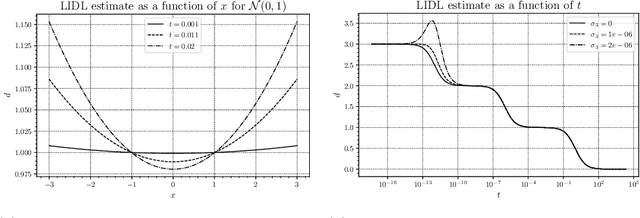
Local intrinsic dimension (LID) estimation methods have received a lot of attention in recent years thanks to the progress in deep neural networks and generative modeling. In opposition to old non-parametric methods, new methods use generative models to approximate diffused dataset density and scale the methods to high-dimensional datasets like images. In this paper, we investigate the recent state-of-the-art parametric LID estimation methods from the perspective of the Wiener process. We explore how these methods behave when their assumptions are not met. We give an extended mathematical description of those methods and their error as a function of the probability density of the data.
Polite Teacher: Semi-Supervised Instance Segmentation with Mutual Learning and Pseudo-Label Thresholding
Nov 07, 2022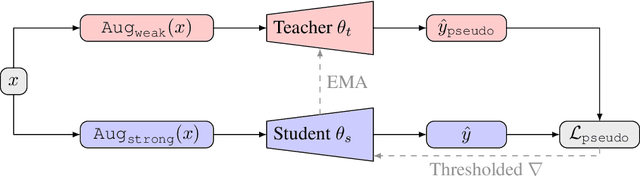
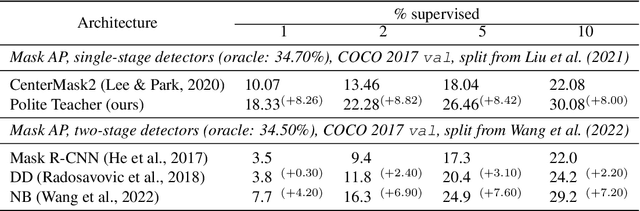


We present Polite Teacher, a simple yet effective method for the task of semi-supervised instance segmentation. The proposed architecture relies on the Teacher-Student mutual learning framework. To filter out noisy pseudo-labels, we use confidence thresholding for bounding boxes and mask scoring for masks. The approach has been tested with CenterMask, a single-stage anchor-free detector. Tested on the COCO 2017 val dataset, our architecture significantly (approx. +8 pp. in mask AP) outperforms the baseline at different supervision regimes. To the best of our knowledge, this is one of the first works tackling the problem of semi-supervised instance segmentation and the first one devoted to an anchor-free detector.
One Simple Trick to Fix Your Bayesian Neural Network
Jul 26, 2022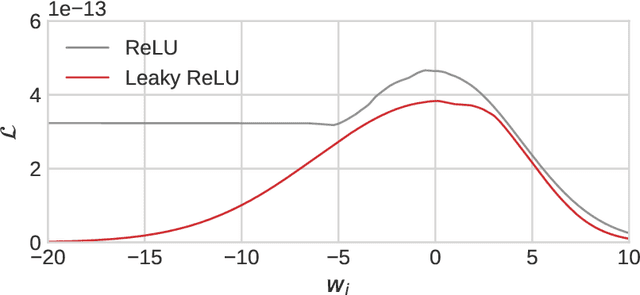
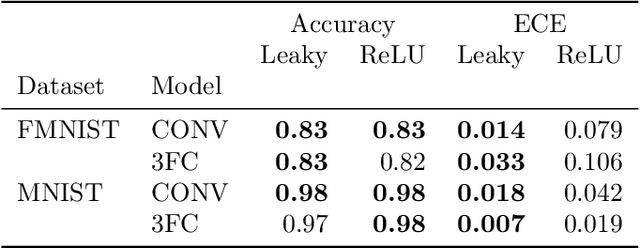
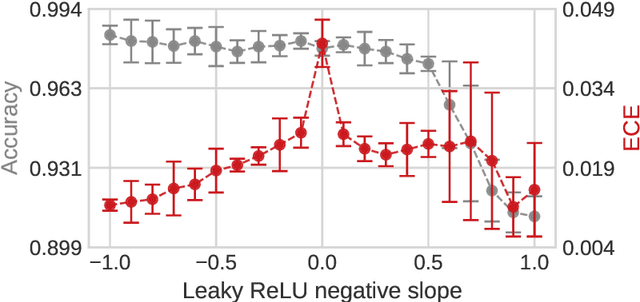

One of the most popular estimation methods in Bayesian neural networks (BNN) is mean-field variational inference (MFVI). In this work, we show that neural networks with ReLU activation function induce posteriors, that are hard to fit with MFVI. We provide a theoretical justification for this phenomenon, study it empirically, and report the results of a series of experiments to investigate the effect of activation function on the calibration of BNNs. We find that using Leaky ReLU activations leads to more Gaussian-like weight posteriors and achieves a lower expected calibration error (ECE) than its ReLU-based counterpart.
LIDL: Local Intrinsic Dimension Estimation Using Approximate Likelihood
Jun 29, 2022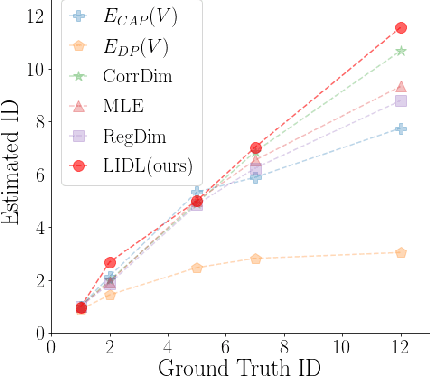

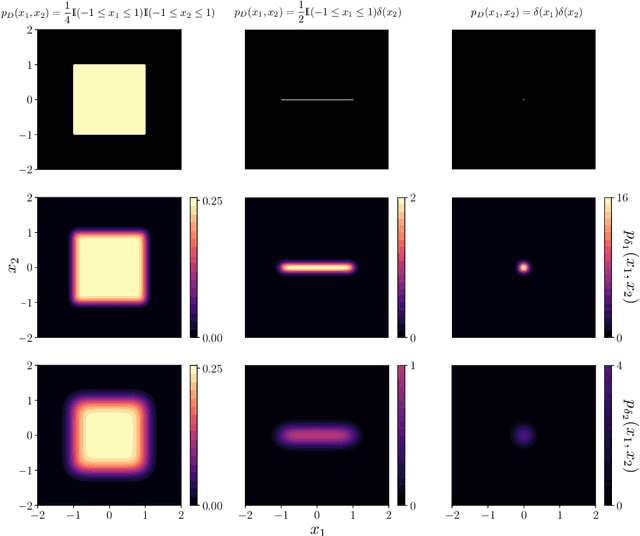
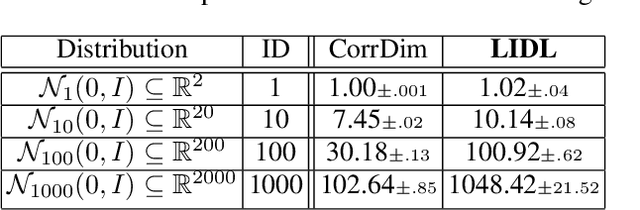
Most of the existing methods for estimating the local intrinsic dimension of a data distribution do not scale well to high-dimensional data. Many of them rely on a non-parametric nearest neighbors approach which suffers from the curse of dimensionality. We attempt to address that challenge by proposing a novel approach to the problem: Local Intrinsic Dimension estimation using approximate Likelihood (LIDL). Our method relies on an arbitrary density estimation method as its subroutine and hence tries to sidestep the dimensionality challenge by making use of the recent progress in parametric neural methods for likelihood estimation. We carefully investigate the empirical properties of the proposed method, compare them with our theoretical predictions, and show that LIDL yields competitive results on the standard benchmarks for this problem and that it scales to thousands of dimensions. What is more, we anticipate this approach to improve further with the continuing advances in the density estimation literature.
2021 BEETL Competition: Advancing Transfer Learning for Subject Independence & Heterogenous EEG Data Sets
Feb 14, 2022
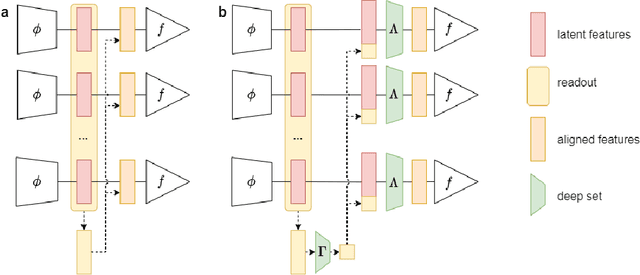
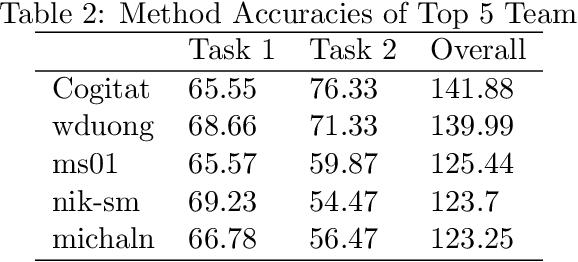
Transfer learning and meta-learning offer some of the most promising avenues to unlock the scalability of healthcare and consumer technologies driven by biosignal data. This is because current methods cannot generalise well across human subjects' data and handle learning from different heterogeneously collected data sets, thus limiting the scale of training data. On the other side, developments in transfer learning would benefit significantly from a real-world benchmark with immediate practical application. Therefore, we pick electroencephalography (EEG) as an exemplar for what makes biosignal machine learning hard. We design two transfer learning challenges around diagnostics and Brain-Computer-Interfacing (BCI), that have to be solved in the face of low signal-to-noise ratios, major variability among subjects, differences in the data recording sessions and techniques, and even between the specific BCI tasks recorded in the dataset. Task 1 is centred on the field of medical diagnostics, addressing automatic sleep stage annotation across subjects. Task 2 is centred on Brain-Computer Interfacing (BCI), addressing motor imagery decoding across both subjects and data sets. The BEETL competition with its over 30 competing teams and its 3 winning entries brought attention to the potential of deep transfer learning and combinations of set theory and conventional machine learning techniques to overcome the challenges. The results set a new state-of-the-art for the real-world BEETL benchmark.
n-CPS: Generalising Cross Pseudo Supervision to n networks for Semi-Supervised Semantic Segmentation
Dec 15, 2021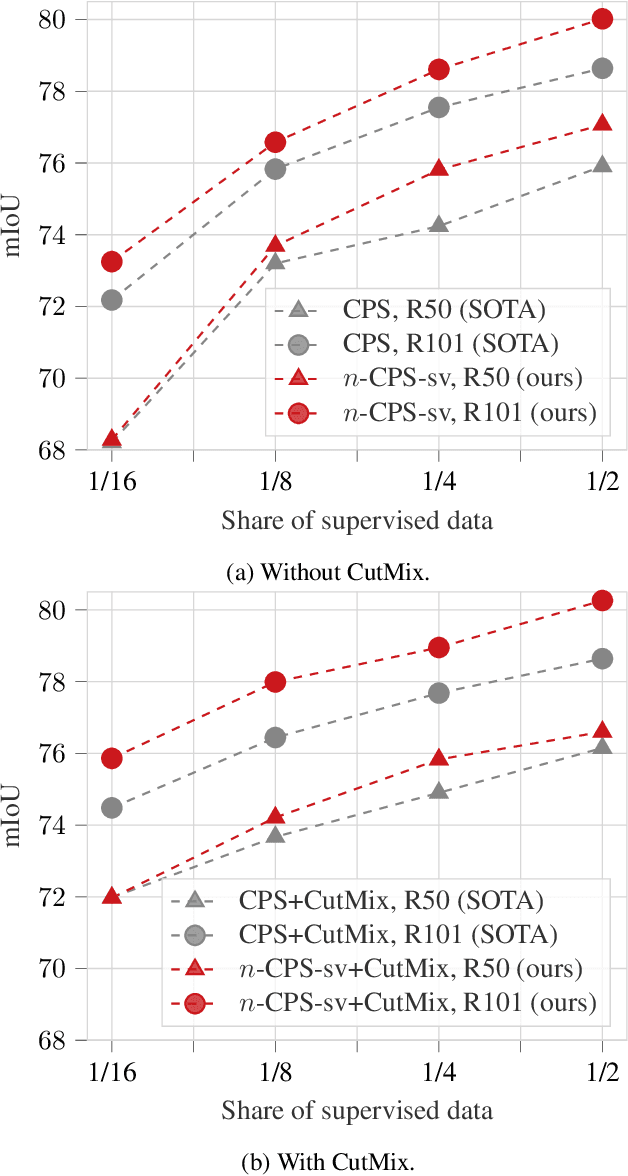
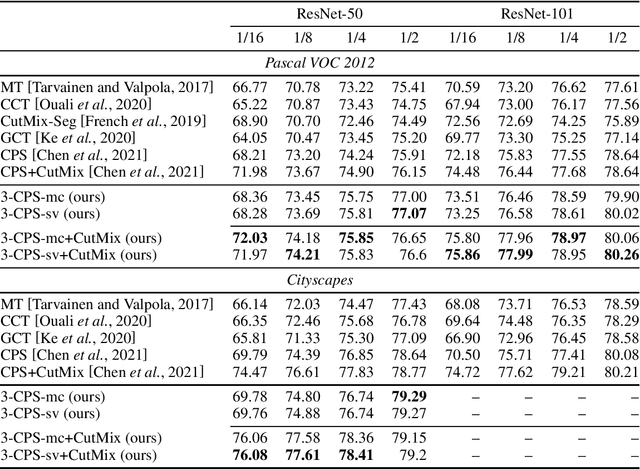
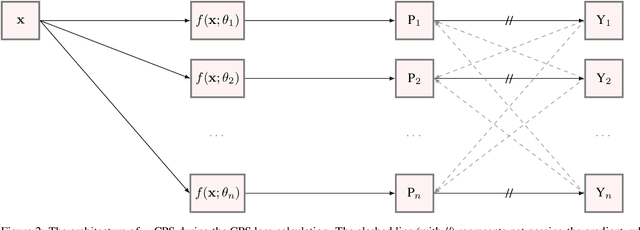
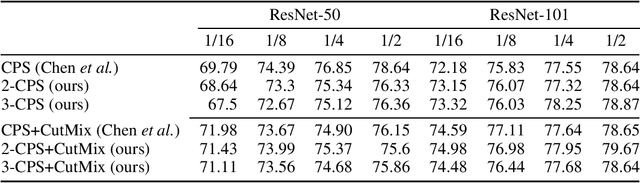
We present n-CPS - a generalisation of the recent state-of-the-art cross pseudo supervision (CPS) approach for the task of semi-supervised semantic segmentation. In n-CPS, there are n simultaneously trained subnetworks that learn from each other through one-hot encoding perturbation and consistency regularisation. We also show that ensembling techniques applied to subnetworks outputs can significantly improve the performance. To the best of our knowledge, n-CPS paired with CutMix outperforms CPS and sets the new state-of-the-art for Pascal VOC 2012 with (1/16, 1/8, 1/4, and 1/2 supervised regimes) and Cityscapes (1/16 supervised).