 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolite Teacher: Semi-Supervised Instance Segmentation with Mutual Learning and Pseudo-Label Thresholding
Nov 07, 2022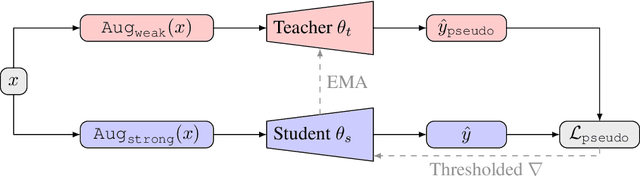
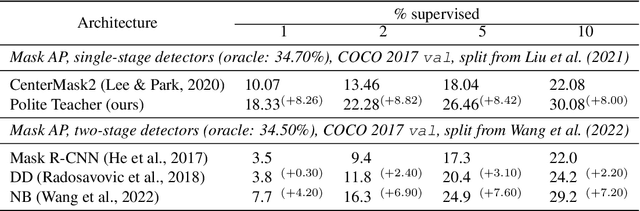


We present Polite Teacher, a simple yet effective method for the task of semi-supervised instance segmentation. The proposed architecture relies on the Teacher-Student mutual learning framework. To filter out noisy pseudo-labels, we use confidence thresholding for bounding boxes and mask scoring for masks. The approach has been tested with CenterMask, a single-stage anchor-free detector. Tested on the COCO 2017 val dataset, our architecture significantly (approx. +8 pp. in mask AP) outperforms the baseline at different supervision regimes. To the best of our knowledge, this is one of the first works tackling the problem of semi-supervised instance segmentation and the first one devoted to an anchor-free detector.
KGTN-ens: Few-Shot Image Classification with Knowledge Graph Ensembles
Nov 06, 2022We propose KGTN-ens, a framework extending the recent Knowledge Graph Transfer Network (KGTN) in order to incorporate multiple knowledge graph embeddings at a small cost. We evaluate it with different combinations of embeddings in a few-shot image classification task. We also construct a new knowledge source - Wikidata embeddings - and evaluate it with KGTN and KGTN-ens. Our approach outperforms KGTN in terms of the top-5 accuracy on the ImageNet-FS dataset for the majority of tested settings.
Towards Knowledge Graphs Validation through Weighted Knowledge Sources
Apr 26, 2021



The performance of applications, such as personal assistants, search engines, and question-answering systems, rely on high-quality knowledge bases, a.k.a. Knowledge Graphs (KGs). To ensure their quality one important task is Knowledge Validation, which measures the degree to which statements or triples of a Knowledge Graph (KG) are correct. KGs inevitably contains incorrect and incomplete statements, which may hinder the adoption of such KGs in business applications as they are not trustworthy. In this paper, we propose and implement a validation approach that computes a confidence score for every triple and instance in a KG. The computed score is based on finding the same instances across different weighted knowledge sources and comparing their features. We evaluated the performance of our Validator by comparing a manually validated result against the output of the Validator. The experimental results showed that compared with the manual validation, our Validator achieved as good precision as the manual validation, although with certain limitations. Furthermore, we give insights and directions toward a better architecture to tackle KG validation.