 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQICHWABASE: A Quechua Language and Knowledge Base for Quechua Communities
Apr 29, 2023Over the last decade, the Web has increasingly become a space of language and knowledge representation. However, it is only true for well-spread languages and well-established communities, while minority communities and their resources received less attention. In this paper, we propose QICHWABASE to support the harmonization process of the Quechua language and knowledge, and its community. For doing it, we adopt methods and tools that could become a game changer in favour of Quechua communities around the world. We conclude that the methodology and tools adopted on building QICHWABASE, which is a Wikibase instance, could enhance the presence of minorities on the Web.
Getting Quechua Closer to Final Users through Knowledge Graphs
Aug 17, 2022



Quechua language and Quechua knowledge gather millions of people around the world and in several countries in South America. Unfortunately, there are only a few resources available to Quechua communities, and they are mainly stored in PDF format. In this paper, the Quechua Knowledge Graph is envisioned and generated as an effort to get Quechua closer to the Quechua communities, researchers, and technology developers. Currently, there are 553636 triples stored in the Quechua Knowledge Graph, which is accessible on the Web, retrievable by machines, and curated by users. To showcase the deployment of the Quechua Knowledge Graph, use cases and future work are described.
Knowledge Graph Curation: A Practical Framework
Aug 17, 2022
Knowledge Graphs (KGs) have shown to be very important for applications such as personal assistants, question-answering systems, and search engines. Therefore, it is crucial to ensure their high quality. However, KGs inevitably contain errors, duplicates, and missing values, which may hinder their adoption and utility in business applications, as they are not curated, e.g., low-quality KGs produce low-quality applications that are built on top of them. In this vision paper, we propose a practical knowledge graph curation framework for improving the quality of KGs. First, we define a set of quality metrics for assessing the status of KGs, Second, we describe the verification and validation of KGs as cleaning tasks, Third, we present duplicate detection and knowledge fusion strategies for enriching KGs. Furthermore, we give insights and directions toward a better architecture for curating KGs.
* 6 pages, 1 figure, published in The 10th International Joint Conference on Knowledge Graphs (IJCKG'21) proceeding
Steps to Knowledge Graphs Quality Assessment
Aug 16, 2022

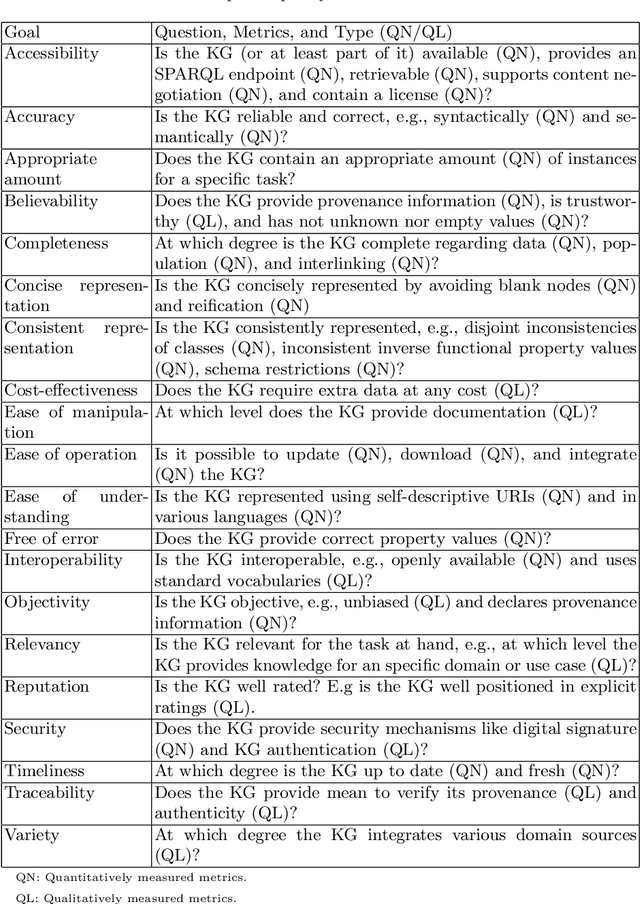
Knowledge Graphs (KGs) have been popularized during the last decade, for instance, they are used widely in the context of the web. In 2012 Google has presented the Google's Knowledge Graph that is used to improve their web search services. The web also hosts different KGs, such as DBpedia and Wikidata, which are used in various applications like personal assistants and question-answering systems. Various web applications rely on KGs to provide concise, complete, accurate, and fresh answer to users. However, what is the quality of those KGs? In which cases should a Knowledge Graph (KG) be used? How might they be evaluated? We reviewed the literature on quality assessment of data, information, linked data, and KGs. We extended the current state-of-the-art frameworks by adding various quality dimensions (QDs) and quality metrics (QMs) that are specific to KGs. Furthermore, we propose a general-purpose, customizable to a domain or task, and practical quality assessment framework for assessing the quality of KGs.
Towards Knowledge Graphs Validation through Weighted Knowledge Sources
Apr 26, 2021



The performance of applications, such as personal assistants, search engines, and question-answering systems, rely on high-quality knowledge bases, a.k.a. Knowledge Graphs (KGs). To ensure their quality one important task is Knowledge Validation, which measures the degree to which statements or triples of a Knowledge Graph (KG) are correct. KGs inevitably contains incorrect and incomplete statements, which may hinder the adoption of such KGs in business applications as they are not trustworthy. In this paper, we propose and implement a validation approach that computes a confidence score for every triple and instance in a KG. The computed score is based on finding the same instances across different weighted knowledge sources and comparing their features. We evaluated the performance of our Validator by comparing a manually validated result against the output of the Validator. The experimental results showed that compared with the manual validation, our Validator achieved as good precision as the manual validation, although with certain limitations. Furthermore, we give insights and directions toward a better architecture to tackle KG validation.