 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGerman Tourism Knowledge Graph
Apr 15, 2024Tourism is one of the most critical sectors of the global economy. Due to its heterogeneous and fragmented nature, it provides one of the most suitable use cases for knowledge graphs. In this poster, we introduce the German Tourism Knowledge Graph that integrates tourism-related data from 16 federal states of Germany and various other sources to provide a curated knowledge source for various applications. It is publicly available through GUIs and an API.
Knowledge Graph Curation: A Practical Framework
Aug 17, 2022
Knowledge Graphs (KGs) have shown to be very important for applications such as personal assistants, question-answering systems, and search engines. Therefore, it is crucial to ensure their high quality. However, KGs inevitably contain errors, duplicates, and missing values, which may hinder their adoption and utility in business applications, as they are not curated, e.g., low-quality KGs produce low-quality applications that are built on top of them. In this vision paper, we propose a practical knowledge graph curation framework for improving the quality of KGs. First, we define a set of quality metrics for assessing the status of KGs, Second, we describe the verification and validation of KGs as cleaning tasks, Third, we present duplicate detection and knowledge fusion strategies for enriching KGs. Furthermore, we give insights and directions toward a better architecture for curating KGs.
* 6 pages, 1 figure, published in The 10th International Joint Conference on Knowledge Graphs (IJCKG'21) proceeding
Duplicate Detection as a Service
Jul 20, 2022


Completeness of a knowledge graph is an important quality dimension and factor on how well an application that makes use of it performs. Completeness can be improved by performing knowledge enrichment. Duplicate detection aims to find identity links between the instances of knowledge graphs and is a fundamental subtask of knowledge enrichment. Current solutions to the problem require expert knowledge of the tool and the knowledge graph they are applied to. Users might not have this expert knowledge. We present our service-based approach to the duplicate detection task that provides an easy-to-use no-code solution that is still competitive with the state-of-the-art and has recently been adopted in an industrial context. The evaluation will be based on several frequently used test scenarios.
Intent Generation for Goal-Oriented Dialogue Systems based on Schema.org Annotations
Jul 03, 2018



Goal-oriented dialogue systems typically communicate with a backend (e.g. database, Web API) to complete certain tasks to reach a goal. The intents that a dialogue system can recognize are mostly included to the system by the developer statically. For an open dialogue system that can work on more than a small set of well curated data and APIs, this manual intent creation will not scalable. In this paper, we introduce a straightforward methodology for intent creation based on semantic annotation of data and services on the web. With this method, the Natural Language Understanding (NLU) module of a goal-oriented dialogue system can adapt to newly introduced APIs without requiring heavy developer involvement. We were able to extract intents and necessary slots to be filled from schema.org annotations. We were also able to create a set of initial training sentences for classifying user utterances into the generated intents. We demonstrate our approach on the NLU module of a state-of-the art dialogue system development framework.
Leveraging Usage Data for Linked Data Movie Entity Summarization
Apr 12, 2012
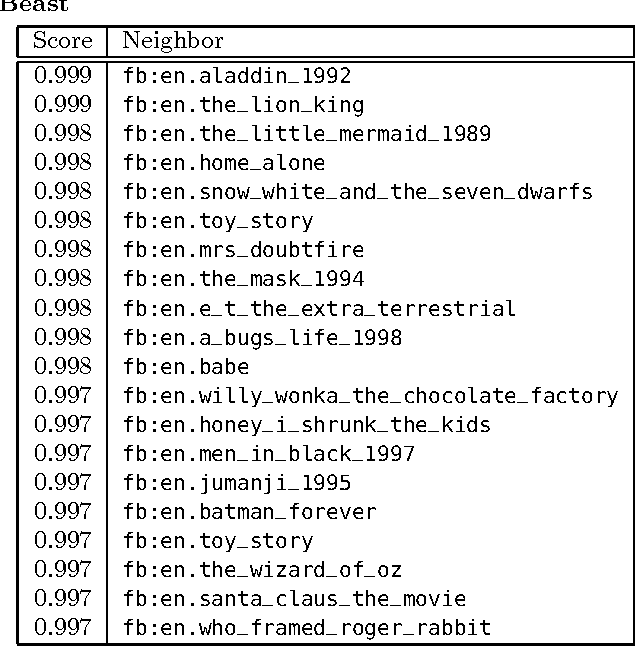
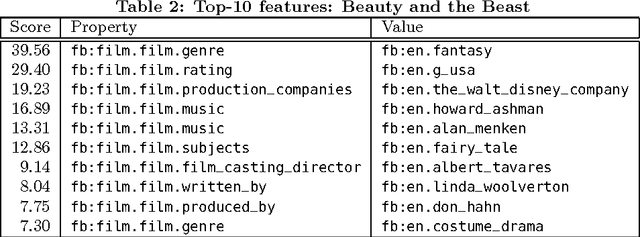
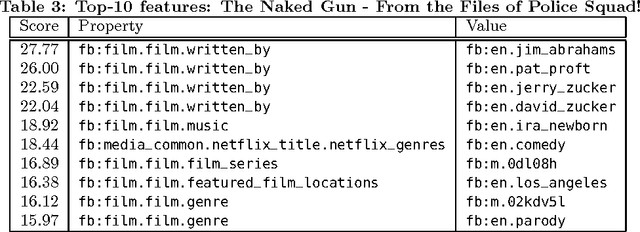
Novel research in the field of Linked Data focuses on the problem of entity summarization. This field addresses the problem of ranking features according to their importance for the task of identifying a particular entity. Next to a more human friendly presentation, these summarizations can play a central role for semantic search engines and semantic recommender systems. In current approaches, it has been tried to apply entity summarization based on patterns that are inherent to the regarded data. The proposed approach of this paper focuses on the movie domain. It utilizes usage data in order to support measuring the similarity between movie entities. Using this similarity it is possible to determine the k-nearest neighbors of an entity. This leads to the idea that features that entities share with their nearest neighbors can be considered as significant or important for these entities. Additionally, we introduce a downgrading factor (similar to TF-IDF) in order to overcome the high number of commonly occurring features. We exemplify the approach based on a movie-ratings dataset that has been linked to Freebase entities.