 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Usage Data for Linked Data Movie Entity Summarization
Paper and Code
Apr 12, 2012
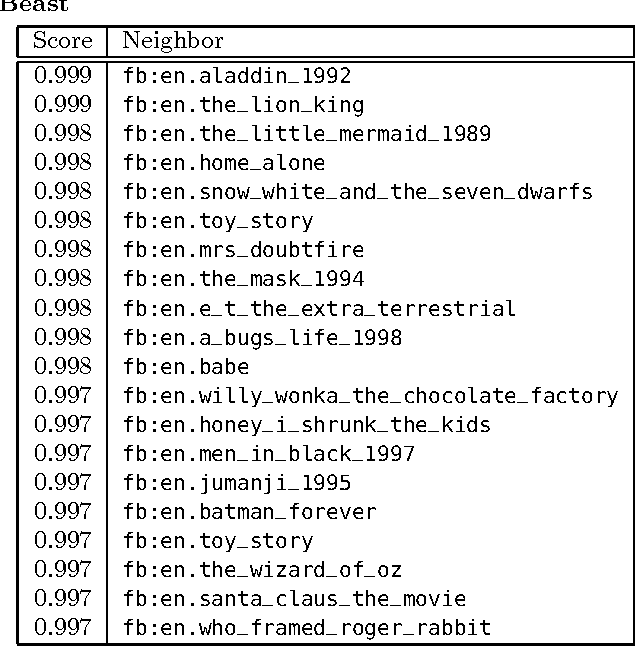
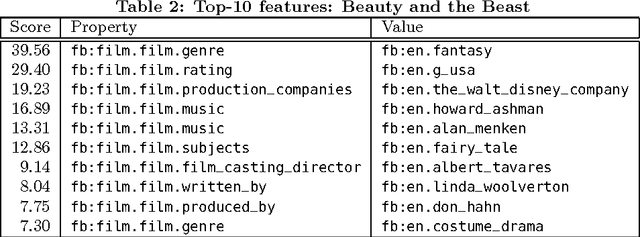
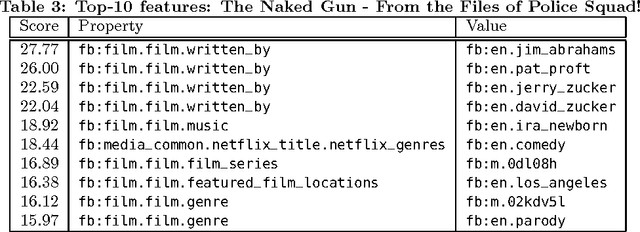
Novel research in the field of Linked Data focuses on the problem of entity summarization. This field addresses the problem of ranking features according to their importance for the task of identifying a particular entity. Next to a more human friendly presentation, these summarizations can play a central role for semantic search engines and semantic recommender systems. In current approaches, it has been tried to apply entity summarization based on patterns that are inherent to the regarded data. The proposed approach of this paper focuses on the movie domain. It utilizes usage data in order to support measuring the similarity between movie entities. Using this similarity it is possible to determine the k-nearest neighbors of an entity. This leads to the idea that features that entities share with their nearest neighbors can be considered as significant or important for these entities. Additionally, we introduce a downgrading factor (similar to TF-IDF) in order to overcome the high number of commonly occurring features. We exemplify the approach based on a movie-ratings dataset that has been linked to Freebase entities.