Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples Detection and Analysis with Layer-wise Autoencoders
Jun 17, 2020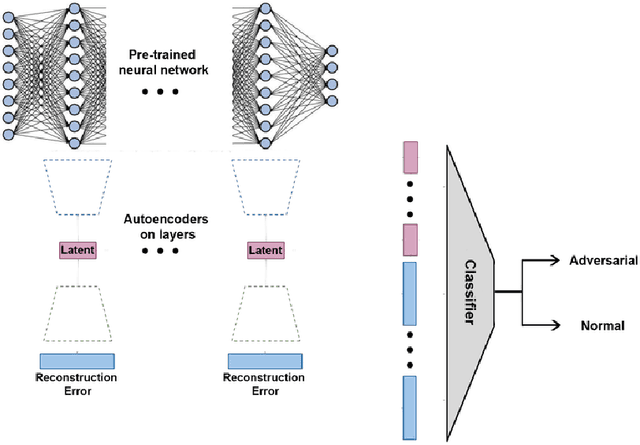



We present a mechanism for detecting adversarial examples based on data representations taken from the hidden layers of the target network. For this purpose, we train individual autoencoders at intermediate layers of the target network. This allows us to describe the manifold of true data and, in consequence, decide whether a given example has the same characteristics as true data. It also gives us insight into the behavior of adversarial examples and their flow through the layers of a deep neural network. Experimental results show that our method outperforms the state of the art in supervised and unsupervised settings.
Via