 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypernetworks build Implicit Neural Representations of Sounds
Feb 17, 2023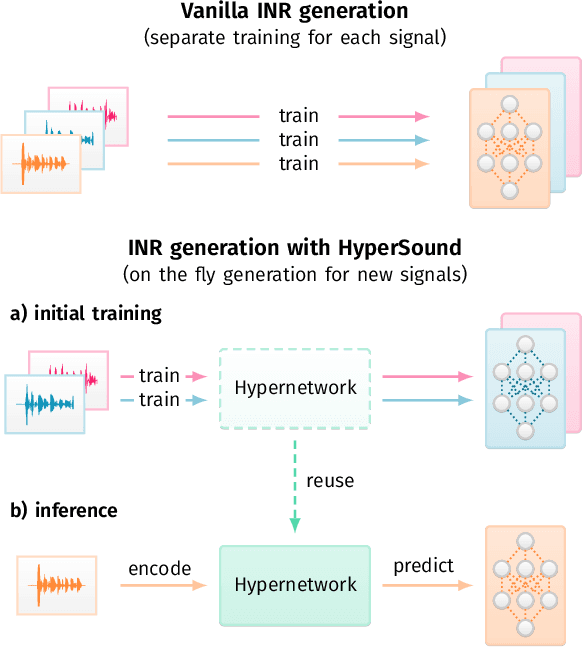

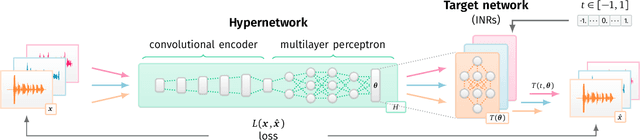
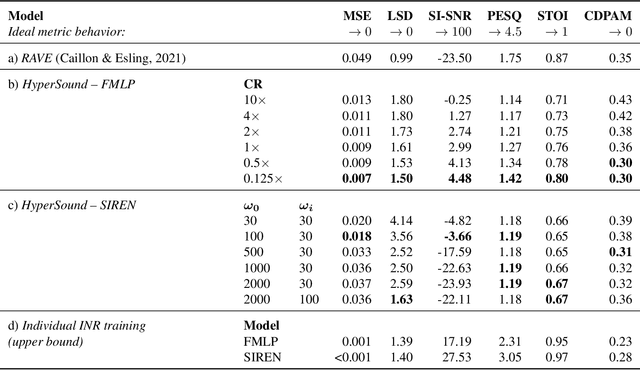
Implicit Neural Representations (INRs) are nowadays used to represent multimedia signals across various real-life applications, including image super-resolution, image compression, or 3D rendering. Existing methods that leverage INRs are predominantly focused on visual data, as their application to other modalities, such as audio, is nontrivial due to the inductive biases present in architectural attributes of image-based INR models. To address this limitation, we introduce HyperSound, the first meta-learning approach to produce INRs for audio samples that leverages hypernetworks to generalize beyond samples observed in training. Our approach reconstructs audio samples with quality comparable to other state-of-the-art models and provides a viable alternative to contemporary sound representations used in deep neural networks for audio processing, such as spectrograms.
HyperSound: Generating Implicit Neural Representations of Audio Signals with Hypernetworks
Nov 03, 2022


Implicit neural representations (INRs) are a rapidly growing research field, which provides alternative ways to represent multimedia signals. Recent applications of INRs include image super-resolution, compression of high-dimensional signals, or 3D rendering. However, these solutions usually focus on visual data, and adapting them to the audio domain is not trivial. Moreover, it requires a separately trained model for every data sample. To address this limitation, we propose HyperSound, a meta-learning method leveraging hypernetworks to produce INRs for audio signals unseen at training time. We show that our approach can reconstruct sound waves with quality comparable to other state-of-the-art models.
Continual Learning with Guarantees via Weight Interval Constraints
Jun 16, 2022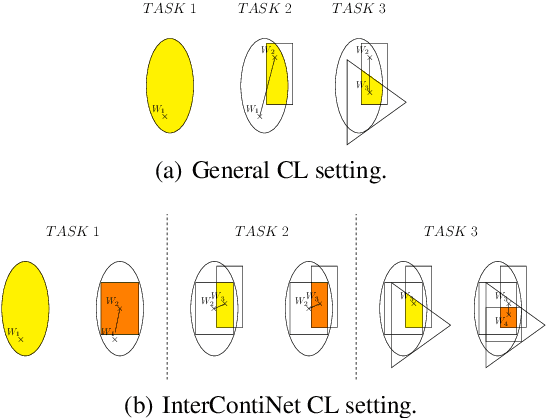



We introduce a new training paradigm that enforces interval constraints on neural network parameter space to control forgetting. Contemporary Continual Learning (CL) methods focus on training neural networks efficiently from a stream of data, while reducing the negative impact of catastrophic forgetting, yet they do not provide any firm guarantees that network performance will not deteriorate uncontrollably over time. In this work, we show how to put bounds on forgetting by reformulating continual learning of a model as a continual contraction of its parameter space. To that end, we propose Hyperrectangle Training, a new training methodology where each task is represented by a hyperrectangle in the parameter space, fully contained in the hyperrectangles of the previous tasks. This formulation reduces the NP-hard CL problem back to polynomial time while providing full resilience against forgetting. We validate our claim by developing InterContiNet (Interval Continual Learning) algorithm which leverages interval arithmetic to effectively model parameter regions as hyperrectangles. Through experimental results, we show that our approach performs well in a continual learning setup without storing data from previous tasks.