 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Monte Carlo: Simulating Reinforcement Learning for Black-Box Agents
Jun 03, 2026LLM agents operate in two distinct regimes: open-weight agents amenable to reinforcement learning (RL) and black-box agents whose behaviour must be controlled purely at test time. Although black-box agents are often backed by state-of-the-art proprietary LLMs, API-only access precludes parameter-level optimization, rendering most RL methods inapplicable. To address this limitation, we turn to a known equivalence between RL and Bayesian inference. We propose Agentic Monte Carlo (AMC) to directly sample from the optimal policy of a black-box agent rather than training it through RL. The optimal policy is a posterior over trajectories whose prior we define as the fixed black-box LLM agent. We employ Sequential Monte Carlo to sample from this posterior by learning a value function to steer the agent while leaving the underlying black-box model unchanged. We validate AMC on three diverse environments from the AgentGym benchmark, demonstrating significant improvements over prompting baselines and even outperforming Group Relative Policy Optimization (GRPO) as we scale the test-time compute of our method. AMC demonstrates the feasibility of performing principled RL-style optimization of black-box LLM agents. Code is available at https://github.com/layer6ai-labs/Agentic-Monte-Carlo
Last Layer Empirical Bayes
May 21, 2025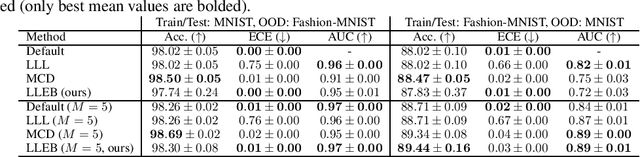
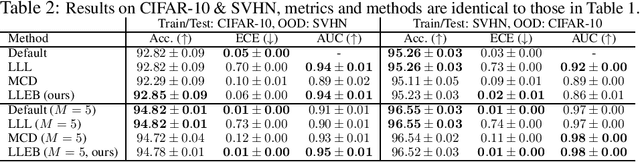


The task of quantifying the inherent uncertainty associated with neural network predictions is a key challenge in artificial intelligence. Bayesian neural networks (BNNs) and deep ensembles are among the most prominent approaches to tackle this task. Both approaches produce predictions by computing an expectation of neural network outputs over some distribution on the corresponding weights; this distribution is given by the posterior in the case of BNNs, and by a mixture of point masses for ensembles. Inspired by recent work showing that the distribution used by ensembles can be understood as a posterior corresponding to a learned data-dependent prior, we propose last layer empirical Bayes (LLEB). LLEB instantiates a learnable prior as a normalizing flow, which is then trained to maximize the evidence lower bound; to retain tractability we use the flow only on the last layer. We show why LLEB is well motivated, and how it interpolates between standard BNNs and ensembles in terms of the strength of the prior that they use. LLEB performs on par with existing approaches, highlighting that empirical Bayes is a promising direction for future research in uncertainty quantification.
Deep Ensembles Secretly Perform Empirical Bayes
Jan 29, 2025Quantifying uncertainty in neural networks is a highly relevant problem which is essential to many applications. The two predominant paradigms to tackle this task are Bayesian neural networks (BNNs) and deep ensembles. Despite some similarities between these two approaches, they are typically surmised to lack a formal connection and are thus understood as fundamentally different. BNNs are often touted as more principled due to their reliance on the Bayesian paradigm, whereas ensembles are perceived as more ad-hoc; yet, deep ensembles tend to empirically outperform BNNs, with no satisfying explanation as to why this is the case. In this work we bridge this gap by showing that deep ensembles perform exact Bayesian averaging with a posterior obtained with an implicitly learned data-dependent prior. In other words deep ensembles are Bayesian, or more specifically, they implement an empirical Bayes procedure wherein the prior is learned from the data. This perspective offers two main benefits: (i) it theoretically justifies deep ensembles and thus provides an explanation for their strong empirical performance; and (ii) inspection of the learned prior reveals it is given by a mixture of point masses -- the use of such a strong prior helps elucidate observed phenomena about ensembles. Overall, our work delivers a newfound understanding of deep ensembles which is not only of interest in it of itself, but which is also likely to generate future insights that drive empirical improvements for these models.
Inconsistencies In Consistency Models: Better ODE Solving Does Not Imply Better Samples
Nov 13, 2024



Although diffusion models can generate remarkably high-quality samples, they are intrinsically bottlenecked by their expensive iterative sampling procedure. Consistency models (CMs) have recently emerged as a promising diffusion model distillation method, reducing the cost of sampling by generating high-fidelity samples in just a few iterations. Consistency model distillation aims to solve the probability flow ordinary differential equation (ODE) defined by an existing diffusion model. CMs are not directly trained to minimize error against an ODE solver, rather they use a more computationally tractable objective. As a way to study how effectively CMs solve the probability flow ODE, and the effect that any induced error has on the quality of generated samples, we introduce Direct CMs, which \textit{directly} minimize this error. Intriguingly, we find that Direct CMs reduce the ODE solving error compared to CMs but also result in significantly worse sample quality, calling into question why exactly CMs work well in the first place. Full code is available at: https://github.com/layer6ai-labs/direct-cms.
Data-Efficient Multimodal Fusion on a Single GPU
Jan 02, 2024



The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim \! 600\times$ fewer GPU days and $\sim \! 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
Jun 07, 2023



We systematically study a wide variety of image-based generative models spanning semantically-diverse datasets to understand and improve the feature extractors and metrics used to evaluate them. Using best practices in psychophysics, we measure human perception of image realism for generated samples by conducting the largest experiment evaluating generative models to date, and find that no existing metric strongly correlates with human evaluations. Comparing to 16 modern metrics for evaluating the overall performance, fidelity, diversity, and memorization of generative models, we find that the state-of-the-art perceptual realism of diffusion models as judged by humans is not reflected in commonly reported metrics such as FID. This discrepancy is not explained by diversity in generated samples, though one cause is over-reliance on Inception-V3. We address these flaws through a study of alternative self-supervised feature extractors, find that the semantic information encoded by individual networks strongly depends on their training procedure, and show that DINOv2-ViT-L/14 allows for much richer evaluation of generative models. Next, we investigate data memorization, and find that generative models do memorize training examples on simple, smaller datasets like CIFAR10, but not necessarily on more complex datasets like ImageNet. However, our experiments show that current metrics do not properly detect memorization; none in the literature is able to separate memorization from other phenomena such as underfitting or mode shrinkage. To facilitate further development of generative models and their evaluation we release all generated image datasets, human evaluation data, and a modular library to compute 16 common metrics for 8 different encoders at https://github.com/layer6ai-labs/dgm-eval.
Bayesian Nonparametrics for Offline Skill Discovery
Feb 16, 2022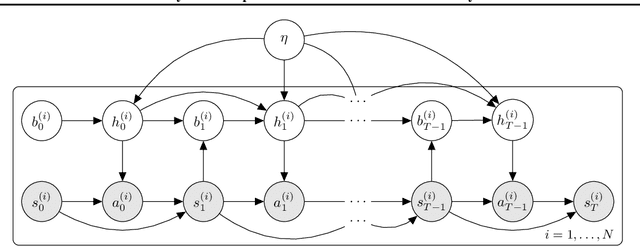
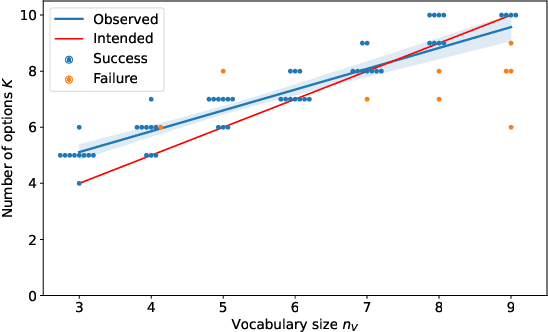
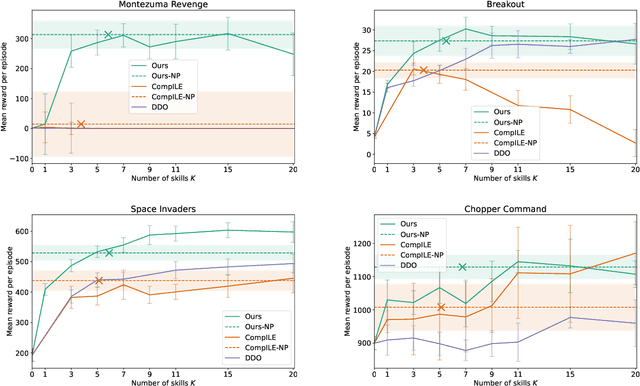
Skills or low-level policies in reinforcement learning are temporally extended actions that can speed up learning and enable complex behaviours. Recent work in offline reinforcement learning and imitation learning has proposed several techniques for skill discovery from a set of expert trajectories. While these methods are promising, the number K of skills to discover is always a fixed hyperparameter, which requires either prior knowledge about the environment or an additional parameter search to tune it. We first propose a method for offline learning of options (a particular skill framework) exploiting advances in variational inference and continuous relaxations. We then highlight an unexplored connection between Bayesian nonparametrics and offline skill discovery, and show how to obtain a nonparametric version of our model. This version is tractable thanks to a carefully structured approximate posterior with a dynamically-changing number of options, removing the need to specify K. We also show how our nonparametric extension can be applied in other skill frameworks, and empirically demonstrate that our method can outperform state-of-the-art offline skill learning algorithms across a variety of environments. Our code is available at https://github.com/layer6ai-labs/BNPO .